基于 word2vec 和 CNN 的文本分类 :综述 & 实践
点击上方“专知”关注获取专业AI知识!

▌导语
传统的向量空间模型(VSM)假设特征项之间相互独立,这与实际情况是不相符的,为了解决这个问题,可以采用文本的分布式表示方式(例如 word embedding形式),通过文本的分布式表示,把文本表示成类似图像和语音的连续、稠密的数据。
这样我们就可以把深度学习方法迁移到文本分类领域了。基于词向量和卷积神经网络的文本分类方法不仅考虑了词语之间的相关性,而且还考虑了词语在文本中的相对位置,这无疑会提升在分类任务中的准确率。 经过实验,该方法在验证数据集上的F1-score值达到了0.9372,相对于原来业务中所采用的分类方法,有20%的提升。
▌业务背景描述
分类问题是人类所面临的一个非常重要且具有普遍意义的问题,我们生活中的很多问题归根到底都是分类问题。
文本分类就是根据文本内容将其分到合适的类别,它是自然语言处理的一个十分重要的问题。文本分类主要应用于信息检索,机器翻译,自动文摘,信息过滤,邮件分类等任务。
▌文本分类综述
文本分类的发展历史
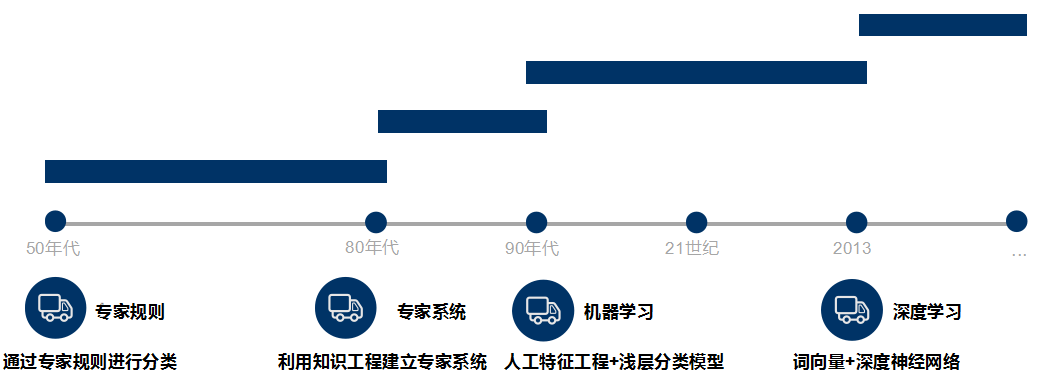
文本分类最早可以追溯到上世纪50年代,那时主要通过专家定义规则来进行文本分类
80年代出现了利用知识工程建立的专家系统
90年代开始借助于机器学习方法,通过人工特征工程和浅层分类模型来进行文本分类。
现在多采用词向量以及深度神经网络来进行文本分类。
文本分类的流程
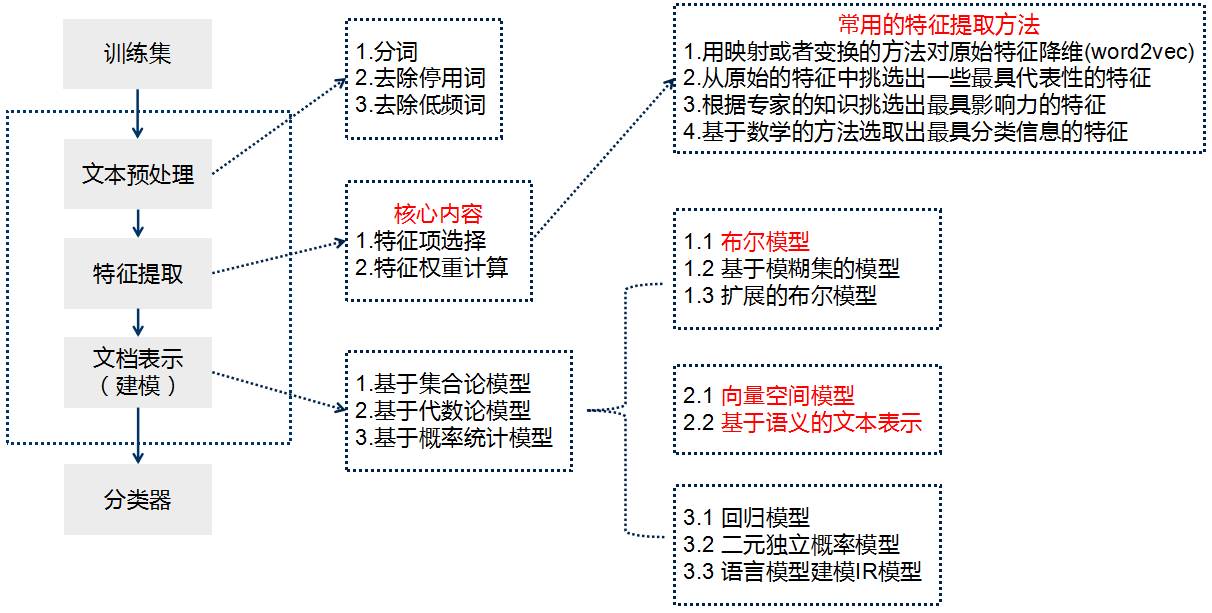
文档表示
如何把文档表示为算法能够处理的结构化数据无疑是文本分类非常重要的环节。
根据文本表示过程所使用的数学方法不同,可以分为以下几类:
1.基于集合论模型
a 布尔模型 b. 基于模糊集的模型 c.扩展的布尔模型
2.基于代数论模型
a 向量空间模型(VSM) b 基于语义的文本表示
3.基于概率统计模型
a 回归模型 b.二元独立概率模型 c. 语言模型建模IR模型
接下来会详细介绍一下布尔模型、向量空间模型(VSM)、基于语义的文本表示。
布尔模型
布尔模型:查询和文档均表达为布尔表达式,其中文档表示成所有词的“与”关系,类似于传统的数据库检索,是精确匹配。
例如:
查询:2006 AND 世界杯 AND NOT 小组赛
文档1:2006年世界杯在德国举行
文档2:2006年世界杯小组赛已经结束
文档相似度计算:查询布尔表达式和所有文档的布尔表达式进行匹配,匹配成功得分为1,否则为0.
布尔模型的优缺点:
优点:简单、现代搜索引擎中依然包含了布尔模型的理念,例如谷歌、百度的高级搜索功能。
缺点:只能严格匹配,另外对于普通用户而言构建查询并不容易。
向量空间模型
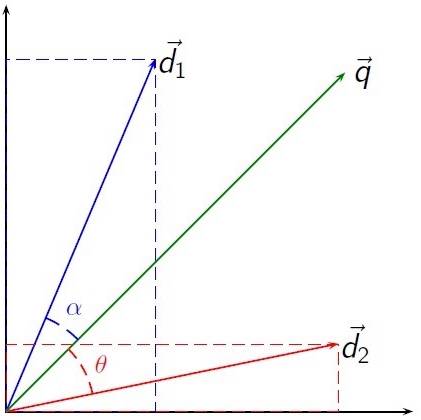
向量空间模型:把对文本内容的处理简化为向量空间的向量计算。并且以空间上的相似度表达文档的相似度。
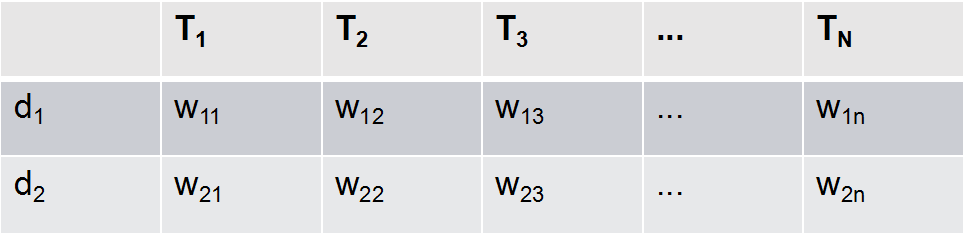
每篇文档由T1、T2、...、Tn一共N个特征项来表示,并且对应着Wi1、Wi2、... 、Win个权重。通过以上方式,每篇文章都表示成了一个N维的向量。
相似度计算:两个文档的相似程度可以用两向量的余弦夹角来进行度量,夹角越小证明相似度越高。
优缺点:
优点:1.简洁直观,可以应用到很多领域(文本分类、生物信息学等)2.支持部分匹配和近似匹配,结果可以排序 3. 检索效果不错
缺点:1.理论上支持不够,基于直觉的经验性公式。 2. 特征项之间相互独立的假设与实际不符。例如,VSM会假设小马哥和腾讯两个词语之间是相互独立的,这显然与实际不符。

基于语义的文本表示
基于语义的文本表示方法:为了解决VSM特征相互独立这一不符合实际的假设,有人提出了基于语义的文本表示方法,比如LDA主题模型,LSI/PLSI概率潜在语义索引等方法,一般认为这些方法得到的文本表示是文档的深层表示。而word embedding文本分布式表示方法则是深度学习方法的重要基础。
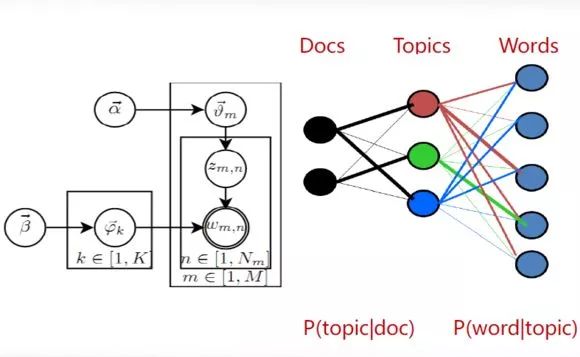
文本的分布式表示:词向量(word embedding)
文本的分布式表示(Distributed Representation)的基本思想是将每个词表示为n维稠密,连续的实数向量。
分布式表示的最大优点在于它具有非常强大的表征能力,比如n维向量每维k个值,可以表征k的n次方个概念。
事实上,不管是神经网络的影层,还是多个潜在变量的概率主题模型,都是在应用分布式表示。下图的神经网络语言模型(NNLM)采用的就是文本分布式表示。而词向量(word embedding)是训练该语言模型的一个附加产物,即图中的Matrix C。

神经网络语言模型(NNLM)
尽管词的分布式表示在86年就提出来了,但真正火起来是13年google发表的两篇word2vec的paper,并随之发布了简单的word2vec工具包,并在语义维度上得到了很好的验证,极大的推动了文本分析的进程。
文本的表示通过词向量的表示方法,把文本数据从高纬度稀疏的神经网络难处理的方式,变成了类似图像、语言的连续稠密数据,这样我们就可以把深度学习的算法迁移到文本领域了。下图是google的词向量文章中涉及的两个模型CBOW和Skip-gram。
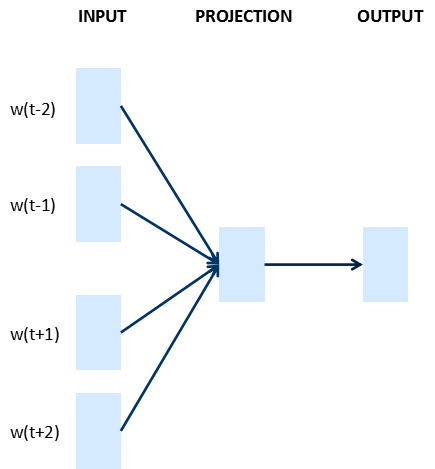
CBOW:上下文来预测当前词
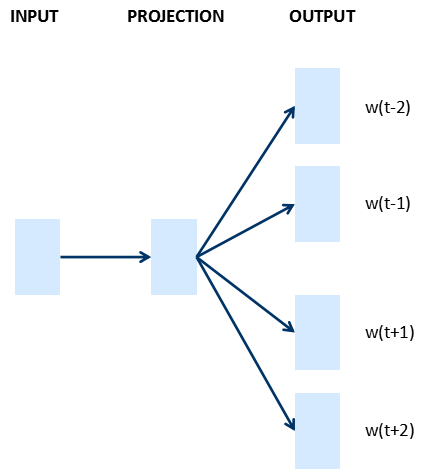
Skip-gram:当前词预测上下文
特征提取
特征提取对应着特征项的选择和特征权重的计算。
特征项的选择就是指根据某个评价指标独立的对原始特征项(词语)进行评分排序,从中选取得分最高的一些特征项,过滤掉其余的特征项。
特征权重的计算:主要思路是依据一个词的重要程度与类别内的词频成正比(代表性),与所有类别中出现的次数成反比(区分度)。
当选用数学方法进行特征提取时,决定文本特征提取效果的最主要因素是评估函数的质量。常见的评估函数主要有如下方法:
TF-IDF
TF:词频,计算该词描述文档内容的能力
IDF:逆向文档频率,用于计算该词区分文档的的能力
思想:一个词的重要程度与在类别内的词频成正比,与所有类别出现的次数成反比。
评价:a.TF-IDF的精度并不是特别高。b.TF-IDF并没有体现出单词的位置信息。
词频(TF)
词频是一个词在文档中出现的次数。通过词频进行特征选择就是将词频小于某一阈值的词删除。
思想:出现频次低的词对过滤的影响也比较小。
评价:有时频次低的词汇含有更多有效的信息,因此不宜大幅删减词汇。
文档频次法(DF)
它指的是在整个数据集中,有多少个文本包含这个单词。
思想:计算每个特征的文档频次,并根据阈值去除文档频次特别低(没有代表性)和特别高的特征(没有区分度)
评价:简单、计算量小、速度快、时间复杂度和文本数量成线性关系,非常适合超大规模文本数据集的特征选择。
互信息方法(Mutual information)
互信息用于衡量某个词与类别之间的统计独立关系,在过滤问题中用于度量特征对于主题的区分度。
思想:在某个特定类别出现频率高,在其他类别出现频率低的词汇与该类的互信息较大。
评价:优点-不需要对特征词和类别之间关系的性质做任何假设。缺点-得分非常容易受词边缘概率的影响。实验结果表明互信息分类效果通常比较差。
期望交叉熵
交叉熵反映了文本类别的概率分布和在出现了某个特定词的条件下文本类别的概率分布之间的距离
思想:特征词t 的交叉熵越大, 对文本类别分布的影响也越大。
评价:熵的特征选择不考虑单词未发生的情况,效果要优于信息增益。
信息增益
信息增益是信息论中的一个重要概念, 它表示了某一个特征项的存在与否对类别预测的影响。
思想:某个特征项的信息增益值越大, 贡献越大, 对分类也越重要。
评价:信息增益表现出的分类性能偏低,因为信息增益考虑了文本特征未发生的情况。
卡方校验
它指的是在整个数据集中,有多少个文本包含这个单词。
思想:在指定类别文本中出现频率高的词条与在其他类别文本中出现频率比较高的词条,对判定文档是否属于该类别都是很有帮助的.
评价:卡方校验特征选择算法的准确率、分类效果受训练集影响较小,结果稳定。对存在类别交叉现象的文本进行分类时,性能优于其他类别的分类方法。
其他评估函数
二次信息熵(QEMI)
文本证据权(The weight of Evidence for Text)
优势率(Odds Ratio)
遗传算法(Genetic Algorithm)
主成分分析(PCA)
模拟退火算法(Simulating Anneal)
N-Gram算法
传统特征提取方法总结
传统的特征选择方法大多采用以上特征评估函数进行特征权重的计算。
但由于这些评估函数都是基于统计学原理的,因此一个缺点就是需要一个庞大的训练集,才能获得对分类起关键作用的特征,这需要消耗大量的人力和物力。
另外基于评估函数的特征提取方法建立在特征独立的假设基础上,但在实际中这个假设很难成立。
通过映射和变化来进行特征提取
特征选择也可以通过用映射或变换的方法把原始特征变换为较少的新特征
传统的特征提取降维方法,会损失部分文档信息,以DF为例,它会剔除低频词汇,而很多情况下这部分词汇可能包含较多信息,对于分类的重要性比较大。
如何解决传统特征提取方法的缺点:找到频率低词汇的相似高频词,例如:在介绍月亮的古诗中,玉兔和婵娟是低频词,我们可以用高频词月亮来代替,这无疑会提升分类系统对文本的理解深度。词向量能够有效的表示词语之间的相似度。
传统的文本分类方法。
基本上大部分机器学习方法都在文本分类领域有所应用。
例如:Naive Bayes,KNN,SVM,集合类方法,最大熵,神经网络等等。
深度学习文本分类方法
卷积神经网络(TextCNN)
循环神经网络(TextRNN)
TextRNN+Attention
TextRCNN(TextRNN+CNN)
本文采用的是卷积神经网络(TextCNN)
▌实践及结果
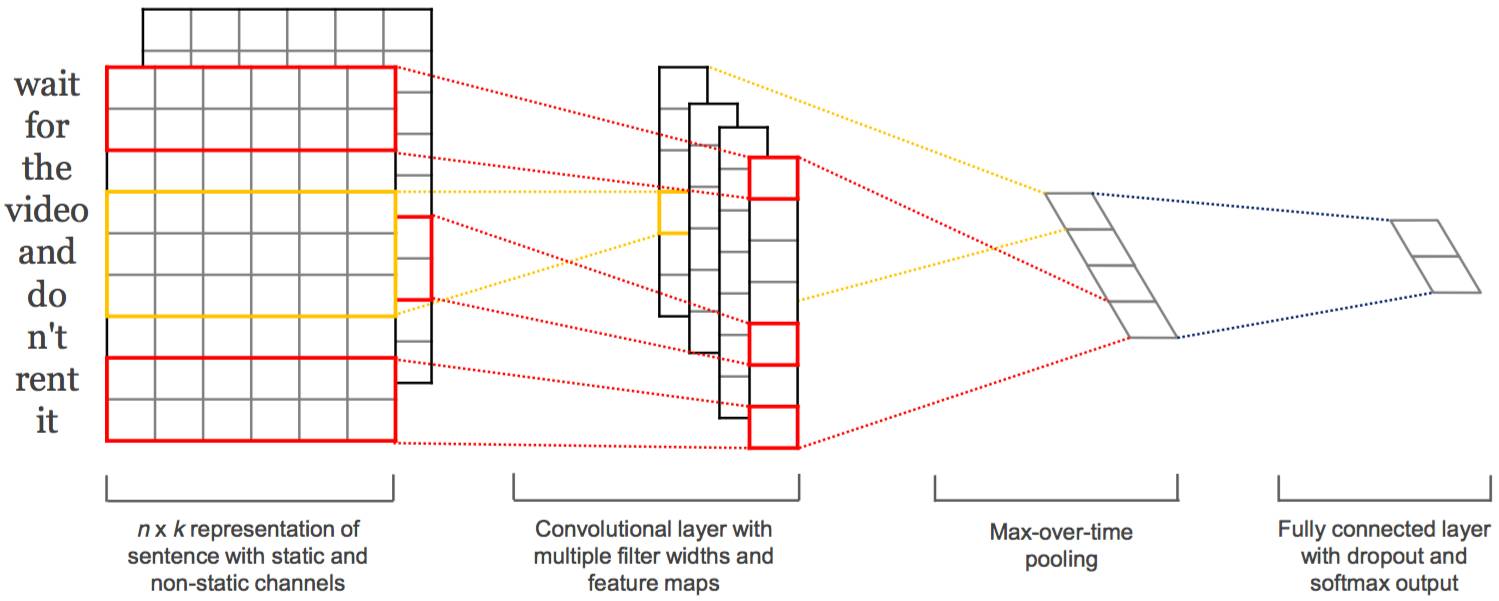
TextCNN网络概览图
实验与步骤
根据警情详情首先训练词向量模型,vector.model
把警情详情文本进行分词,去除停用词,然后利用词向量来表示,每篇文档表示为250*200的矩阵(250:文档包含的词语个数,不够的以200维-5.0填充,200:每个词语用200维向量来表示)
把警情训练样本分割为train-set,validation set,test set。
利用设计好的卷积神经网络进行训练,并测试。
设计的卷积神经网络结构
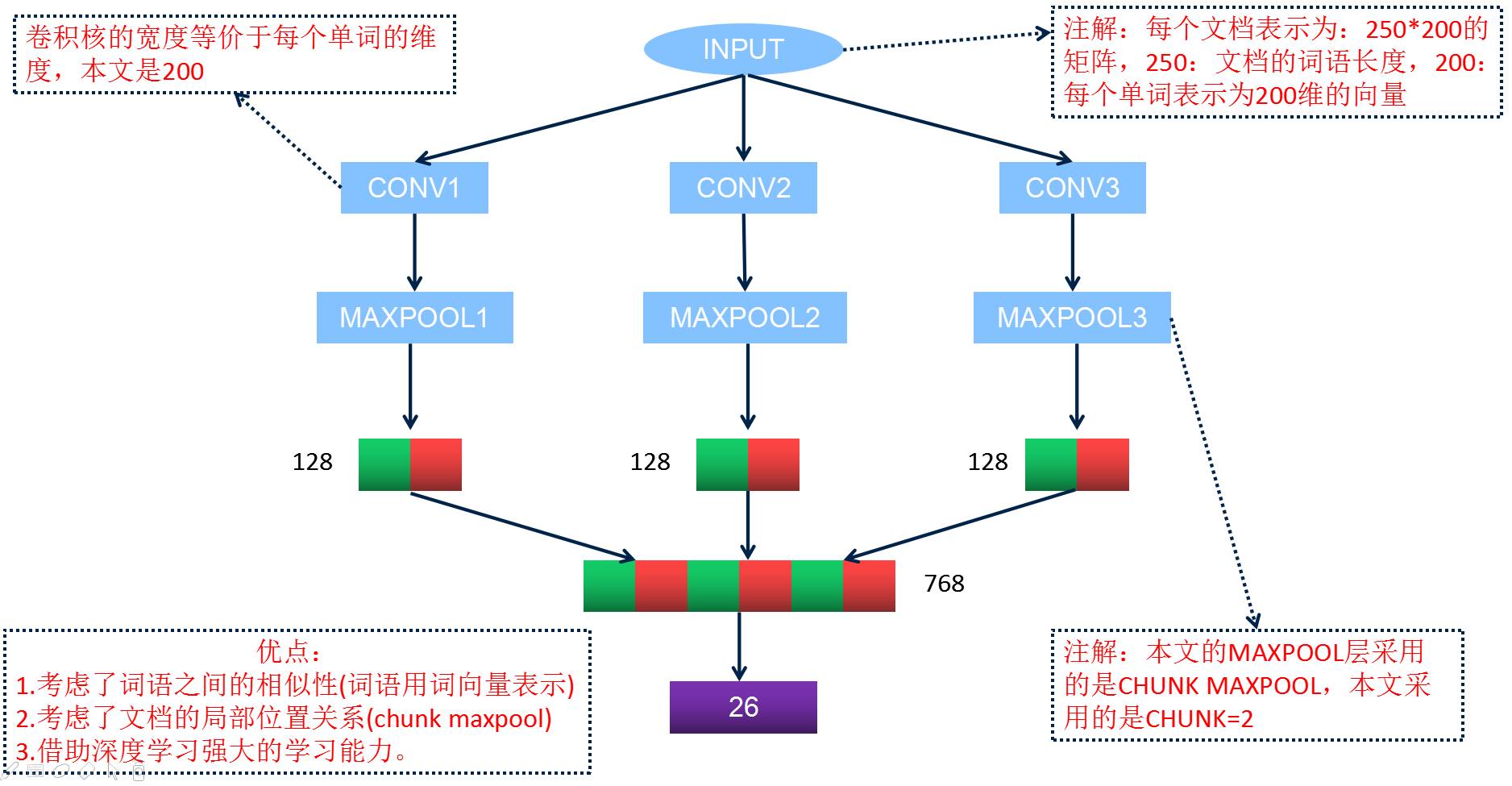
实验结果
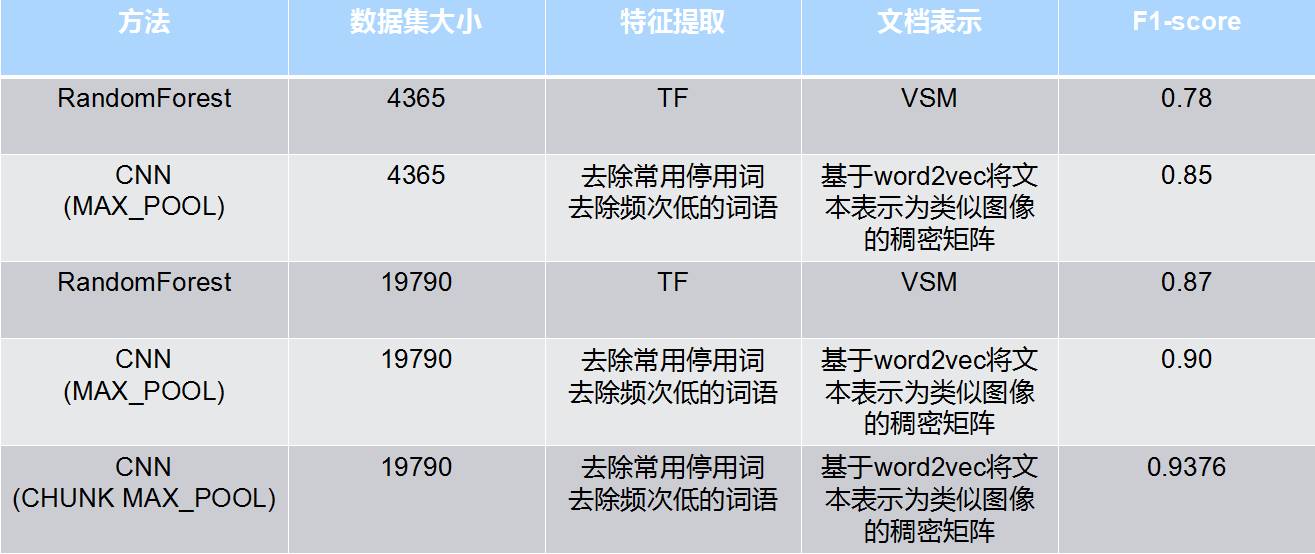
为了检验模型在真实数据上的分类准确率,我们又额外人工审核了1000条深圳地区的案情数据,相较于原来分类准确率的68%,提升到了现在的90%,说明我们的模型确实有效,相对于原来的模型有较大的提升。
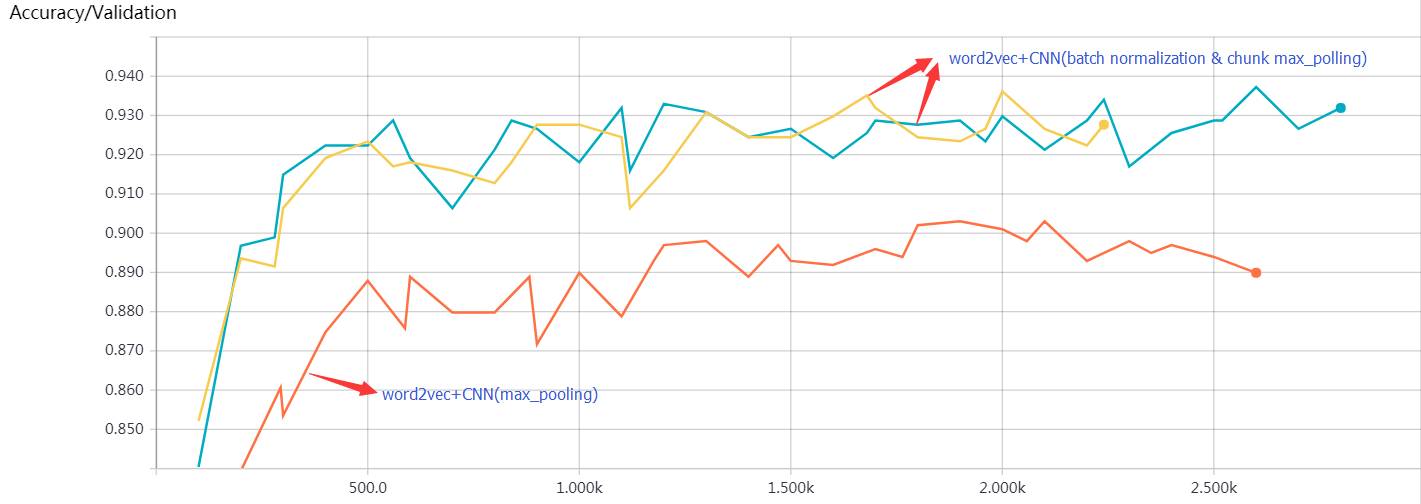
红色:word2vec+CNN(max_pooling)在验证集上的准确率走势图
黄色和蓝色:word2vec+CNN(batch normalization & chunk max_pooling:2 chunk)在验证集上的准确率走势图
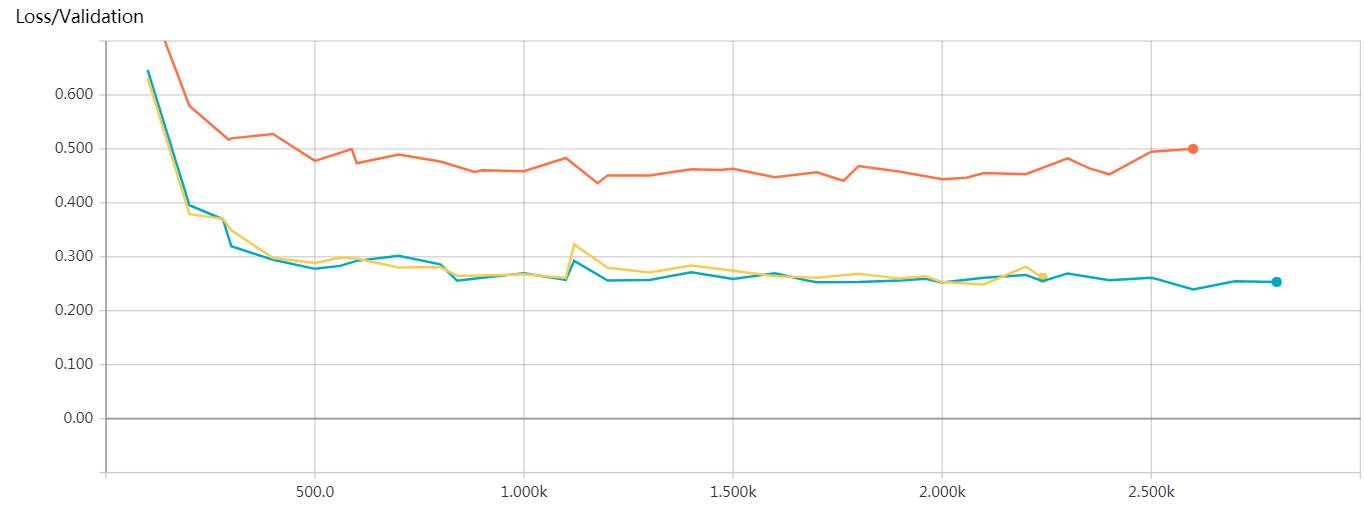
红色:word2vec+CNN(max_pooling) 在验证集上的Loss走势
黄色和蓝色:word2vec+CNN(batch normalization & chunk max_pooling:2 chunk)在验证集上的Loss走势
一些感悟
一定要理解你的数据
做好实验记录和分析
大量的数据样本比改善模型来的更有效,但代价也很高
阅读paper,理解原理,开阔视野,加强实践,敢于尝试,追求卓越
一些参考文献
CSDN-基于tensorflow的CNN文本分类
CSDN-深度学习在文本分类中的应用
知乎-用深度学习解决大规模文本分类的问题-综述和实践
简书-利用tensorflow实现卷积神经网络做文本分类
CSDN-利用word-embedding自动生成语义相近句子
Github-Implementing a CNN for text classification in tensorflow
卷积神经网络在句子建模上的应用
CSDN-自然语言处理中CNN模型几种常见的Max-Pooling操作
WILDML-understanding convolutional neural network for NLP
博客园-文本深度表示模型--word2vec & doc2vec词向量模型
CSDN-用docsim/doc2vec/LSH比较两个文档之间的相似度
Deeplearning中文论坛-自然语言处理(三)之 word embedding
CSDN-DeepNLP的学习,词嵌入来龙去脉-深度学习
CSDN-自己动手写word2vec
本文转载自:https://www.qcloud.com/community/article/931071
欢迎查看专知计算机视觉荟萃知识资料全集(关注本公众号-专知,获取下载链接):
【专知荟萃02】自然语言处理NLP知识资料大全集(入门/进阶/论文/Toolkit/数据/综述/专家等)(附pdf下载)
-END-
专 · 知
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取AI知识资料!
请关注我们的公众号,获取人工智能的专业知识。扫一扫关注我们的微信公众号。


点击“阅读原文”,使用专知!
展开全文



