NeurIPS2019公布获奖论文!7篇论文斩获!微软华裔研究员斩获经典论文

人工智能顶会NeurlPS 2019周日一早在温哥华拉开序幕,今天,大会公布了包括杰出论文奖、杰出新方向论文奖等五大类奖项。

NeurIPS,全称神经信息处理系统大会(Conference and Workshop on Neural Information Processing Systems),自1987年诞生至今已有32年的历史,一直以来备受学术界和产业界的高度关注。NeurIPS为人工智能领域的A类会议,同时也是人工智能领域最富盛名的年度会议之一。
在论文方面,今年大会投稿数量也创下了历史新高,共提交6743 篇有效论文,接收 1428 篇,接受率为 21.17%。
今年的参会人数也再创新高,参会总人数已经突破了13000人,相比去年参会的9000人增加了近一半。由于报名人数过多。

评审委员会一致通过的评审标准包括,鼓励以下9种研究特质:
持久的潜力ーー专注于主要工作,而不是边边角角。 在未来的几十年里,人们可能仍然会关心这个问题;
洞察力——提供新的(最好是深入的)理解;不仅仅是为了模型表现出几个百分点的改进;
创造力——以创造性的新方式看待问题,给出一个真正让读者感到惊讶的结果;
革命性ーー将从根本上改变人们未来的思维方式;
严谨性ーー无懈可击的严谨和考虑;
优雅感ーー美丽、干净、光滑、优雅;
现实性ーー不过分强调其重要性;
科学性——在实际上是可证伪的;
可重复性ーー结果是可重现的;代码是可用的,并且可以在各种机器上使用;数据集是可用的;证明细节是完整的。
组委会还公布了一些他们不鼓励的3种论文特质:
低效ーー远离那些仅仅因为资源浪费而脱颖而出的工作(主要是因为浪费了大量资源而获得了较高的排名)
趋附大势——因为一个想法很时尚所以采用某种方法,但可以通过其他方法以不同的更有效的方式获得。
过于复杂ーー论文有非必要的复杂性。
此外,组委会今年还新增加了一个杰出新方向论文奖,以突出在为未来的研究设置一个新的途径方面出色的工作。
一起来看看5大奖项的获奖论文。
杰出论文奖(Outstanding Paper Award)
获奖论文:
Distribution-Independent PAC Learning of Halfspaces with Massart Noise

论文链接:
https://papers.nips.cc/paper/8722-distribution-independent-pac-learning-of-halfspaces-with-massart-noise.pdf
论文作者:Ilias Diakonikolas、Themis Gouleakis、Christos Tzamos
机构:威斯康辛大学麦迪逊分校、马普所
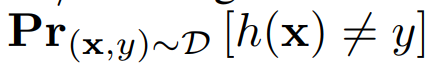 。
。
杰出新方向论文奖(Outstanding New Directions Paper Award)
获奖论文:
Uniform convergence may be unable to explain generalization in deep learning

论文链接:
https://papers.nips.cc/paper/9336-uniform-convergence-may-be-unable-to-explain-generalization-in-deep-learning.pdf
论文作者:Vaishnavh Nagarajan、J. Zico Kolter
机构:卡耐基梅隆大学、博世人工智能中心
杰出论文荣誉提名奖(Honorable Mention Outstanding Paper Award)
获奖论文:
Nonparametric Density Estimation & Convergence Rates for GANs under Besov IPM Losses

论文链接:
论文作者:AnanyaUppal、 ShashankSingh、BarnabásPóczos
机构:卡内基梅隆大学
获奖论文:
Fast and Accurate Least-Mean-Squares Solvers

论文链接:
https://papers.nips.cc/paper/9040-fast-and-accurate-least-mean-squares-solvers
论文作者:AlaaMaalouf、IbrahimJubran、DanFeldman
机构:海法大学计算机科学系机器人与大数据实验室
杰出新方向论文荣誉提名奖(Honorable Mention Outstanding New Directions Paper Award)
获奖论文:
Putting An End to End-to-End: Gradient-Isolated Learning of Representations

论文地址:
论文作者:Sindy Löwe、Peter O'Connor、Bastiaan Veeling
机构:阿姆斯特丹大学
获奖论文:
Scene Representation Networks: Continuous 3D-Structure-Aware Neural Scene Representations

论文链接:
论文作者:Vincent Sitzmann 、Michael Zollhöfer、Gordon Wetzstein
机构:斯坦福大学
经典论文奖(Test of Time Award)
论文名称:
Dual Averaging Method for Regularized Stochastic Learning and Online Optimization

论文链接:
https://www.microsoft.com/en-us/research/wp-content/uploads/2016/02/xiao10JMLR.pdf
论文作者:Lin Xiao,微软研究院的高级首席研究员,曾就读于北京航空航天大学和斯坦福大学。他目前的研究方向包括:大规模优化的理论和算法、机器学习和在线算法、并行和分布式计算。

本文认为正规化随机学习和在线优化问题,目标函数是两个凸的和术语:一个是损失函数的学习任务;另一个是一个简单的正则化项。研究中开发了Nesterov的双重平均方法的扩展,可以利用在线设置的正则化结构。在这些方法的每次迭代中,通过解决一个简单的最小化问题来调整学习变量,该问题涉及到损失函数过去所有次梯度的运行平均值和整个正则化项,而不仅仅是其次梯度。对于ℓ1的正则化,该方法能够有效的获得稀疏效果。研究还证明这些方法达到了随机学习标准的最优收敛速度。对于损失函数具有Lipschitz连续梯度的随机学习问题,研究者提出了对偶平均法的加速版。
该论文提出了一种全新在线算法——正则化双重平均算法(RDA),研究实验证明,RDA 对于ℓ1 正则化的稀疏在线学习非常有效。
经典论文奖的授予原则为:具有重要贡献、持久影响和广泛吸引力。官方设置了专门的委员会负责筛选对社会产生重大且持久影响的论文。Amir Globerson, Antoine Bordes, Francis Bach和Iain Murray承担参与到评选工作中。
委员会从18篇被接受的论文开始进行评选工作——到2009年NeurIPS,这些论文自发表以来被引用次数最多。然后,他们把搜索的重点放在那些已经产生了持续影响的论文上,即那些在最近的论文仍然被引用的论文。委员会还希望能够确定对该领域的准确贡献,使选定的论文脱颖而出;并确保该论文写得足够好,使当今社会的大多数人都能阅读。
参考链接:
1. https://medium.com/@NeurIPSConf/neurips-2019-paper-awards-807e41d0c1e
2. 机器之心:
https://mp.weixin.qq.com/s/bSsmaOzQYzJ_7RjnzS804g
3. 大数据文摘:
https://mp.weixin.qq.com/s/B2ocJ1Y2evLwVkG5FrUz5A



展开全文



