【机器学习实战】理解Scikit-Learn中分类性能度量指标
【导读】本文是数据科学家Andrew Long撰写的技术博文,介绍了在分类模型中需要用到的度量标准以及对应Python中Scikit-Learn库实战。本文就举例介绍了分类任务中的其他度量标准,首先介绍一些相关概念:精确度、召回率、F1分数、TRP和FPR等。另外包括两种可视化方法:混淆矩阵和ROC曲线。并且也详细说明了如何使用Scikit-Learn库进行各种度量指标的实现,建议大家收藏学习。
作者 | Andrew Long
编译 | 专知
整理 | Mandy

Understanding Data Science Classification Metrics in Scikit-Learn in Python
在本教程中,我们将介绍Python的scikit-learn中的一些分类度量指标 - 从头开始学习和编写我们自己的函数,以理解其中一些函数背后的数学知识。
数据科学中预测建模的一个主要领域是分类。分类就是试图预测一个群体中某一特定样本来自哪个类别。例如,如果我们试图预测某个病人是否会再次住院,可能的两类是住院(正)和非住院(负)。然后,分类模型试图预测每个患者是否将住院或未住院。换句话说,分类只是试图简单地预测人群中某一特定样本应该被放在哪个桶中(预测是正的还是预测是负的),如下所示。
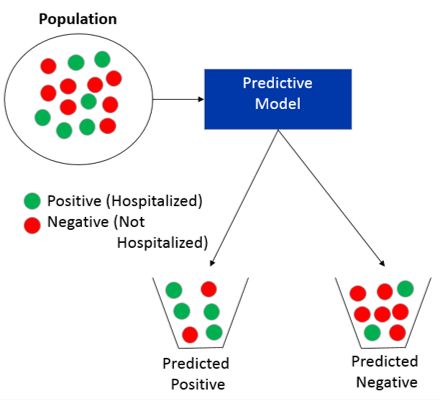
在训练分类预测模型时,你需要评估它的好坏程度。有趣的是,有很多不同的方法来评估性能。大多数使用Python进行预测建模的数据科学家都使用名为scikit-learn的Python库。 Scikit-learn包含许多用于分析模型性能的内置函数。在本教程中,我们将介绍其中的一些指标,并从头开始编写我们自己的函数,以理解其中一些指标背后的数学原理。如果您只想阅读关于性能度量的文章,请参阅我之前的一篇文章:
https://towardsdatascience.com/data-science-performance-metrics-for-everyone-4d68f4859eef。
专知公众号以前也写过
【干货】不止准确率:为分类任务选择正确的机器学习度量指标(附代码实现)
本教程将介绍sklearn.metrics中的以下指标:
confusion_matrix
accuracy_score
recall_score
precision_score
f1_score
roc_curve
roc_auc_score
让我们开始吧
有关示例数据集和jupyter notebook,请参阅我的github:
https://github.com/andrewwlong/classification_metrics_sklearn。
我们将从头开始编写自己的函数,现在假设有两个类别。请注意,您需要标记为#your code here的地方填写您自己的部分。
让我们加载一个样本数据集,其中包含两个模型(model_RF 和 model_LR)的真实标签(actual_label)和预测概率。这里的概率是第1类的概率。
import pandas as pd
df = pd.read_csv('data.csv')
df.head()
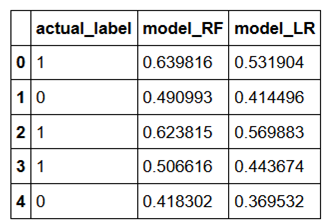
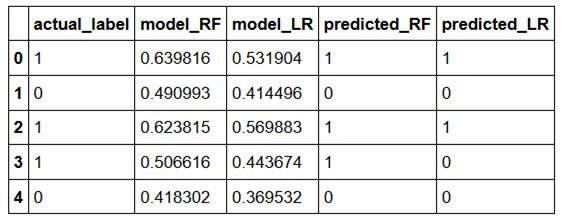
在大多数数据科学项目中,您需要定义一个阈值,以定义哪些预测概率被标记为预测正值,哪些预测概率被标记为预测负值。现在让我们假设阈值是0.5。让我们再添加另外两列,将概率转换为预测标签。
thresh = 0.5
df['predicted_RF'] = (df.model_RF >=0.5).astype('int')
df['predicted_LR'] = (df.model_LR >=0.5).astype('int')
df.head()
confusion_matrix
给定一个实际的标签和一个预测的标签,我们能做的第一件事就是把样本分成4个部分:
True positive(真阳性) — 真实值(actual) = 1, 预测值(predicted) = 1
False positive(假阳性) — 真实值(actual) = 0, 预测值(predicted) = 1
False negative(假阴性) — 真实值(actual) = 1, 预测值(predicted) = 0
True negative(真阴性) — 真实值(actual) = 0, 预测值(predicted) = 0
这四个部分可以用以下图像表示,我们将在下面的许多计算中用到此图像。引用自:
https://en.wikipedia.org/wiki/Precision_and_recall#/media/File:Precisionrecall.svg。
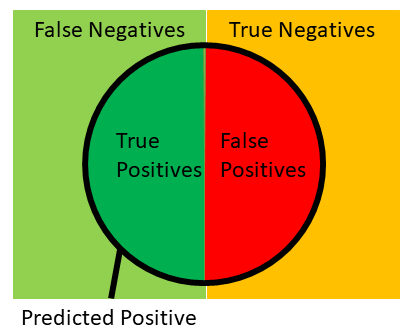
这四个部分还可以使用混淆矩阵表示,如下所示:

我们可以从scikit-learn获得混淆矩阵(作为一个2x2数组),它将实际标签和预测标签作为输入:
from sklearn.metrics importconfusion_matrix
confusion_matrix(df.actual_label.values,df.predicted_RF.values)

其中有5047个 true positive,2360个false positive,2832个false negative和5519个true negative。让我们定义自己的函数来验证confusion_matrix。请注意,我的代码只写了第一个,你需要自己来写其他3个。
def find_TP(y_true, y_pred):
#counts the number of true positives (y_true = 1, y_pred = 1)
return sum((y_true == 1) & (y_pred == 1))
def find_FN(y_true, y_pred):
#counts the number of false negatives (y_true = 1, y_pred = 0)
return # your code here
def find_FP(y_true, y_pred):
# countsthe number of false positives (y_true = 0, y_pred = 1)
return # your code here
def find_TN(y_true, y_pred):
#counts the number of true negatives (y_true = 0, y_pred = 0)
return # your code here
您可以检查您的结果是否匹配:
print('TP:',find_TP(df.actual_label.values,df.predicted_RF.values))
print('FN:',find_FN(df.actual_label.values,df.predicted_RF.values))
print('FP:',find_FP(df.actual_label.values,df.predicted_RF.values))
print('TN:',find_TN(df.actual_label.values,df.predicted_RF.values))
让我们写一个函数,它将为我们计算所有这四个,以及另一个函数来复制confusion_matrix:
import numpy as np
def find_conf_matrix_values(y_true,y_pred):
#calculate TP, FN, FP, TN
TP =find_TP(y_true,y_pred)
FN =find_FN(y_true,y_pred)
FP =find_FP(y_true,y_pred)
TN =find_TN(y_true,y_pred)
return TP,FN,FP,TN
def my_confusion_matrix(y_true, y_pred):
TP,FN,FP,TN = find_conf_matrix_values(y_true,y_pred)
return np.array([[TN,FP],[FN,TP]])
检查您的结果是否匹配:
my_confusion_matrix(df.actual_label.values,df.predicted_RF.values)
与其手工比较,不如使用Python内置的assert和numpy的array_equal函数来验证我们的函数是否有效:
assert np.array_equal(my_confusion_matrix(df.actual_label.values,
df.predicted_RF.values), confusion_matrix(df.actual_label.values,
df.predicted_RF.values) ), 'my_confusion_matrix() is not correct for RF'
assert np.array_equal(my_confusion_matrix(df.actual_label.values,
df.predicted_LR.values),confusion_matrix(df.actual_label.values,
df.predicted_LR.values) ), 'my_confusion_matrix() is not correct for LR'
给定了这四个部分(TP、FP、FN、TN),我们可以计算许多其他性能指标。
accuracy_score
最常用的分类度量指标就是准确性,即正确预测的样本的分数,如下图所示:
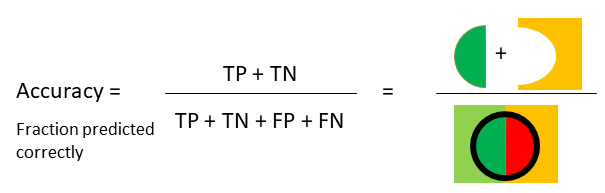
我们可以从scikit-learn获得accuracy score,它以实际标签和预测标签作为输入:
from sklearn.metrics importaccuracy_score
accuracy_score(df.actual_label.values,df.predicted_RF.values)
您的结果应该是 0.6705165630156111
复制accuracy_score来定义您自己的函数,使用上面的公式。
def my_accuracy_score(y_true,y_pred):
#calculates the fraction of samples predicted correctly
TP,FN,FP,TN = find_conf_matrix_values(y_true,y_pred)
return # your code here
assertmy_accuracy_score(df.actual_label.values, df.predicted_RF.values)
==accuracy_score(df.actual_label.values, df.predicted_RF.values),
'my_accuracy_score failed on RF'
assertmy_accuracy_score(df.actual_label.values, df.predicted_LR.values)
==accuracy_score(df.actual_label.values, df.predicted_LR.values),
'my_accuracy_score failed on LR'
print('Accuracy RF:%.3f'%(my_accuracy_score(df.actual_label.values,
df.predicted_RF.values)))
print('Accuracy LR:%.3f'%(my_accuracy_score(df.actual_label.values,
df.predicted_LR.values)))
使用accuracy作为性能指标,RF模型(0.67)比LR模型(0.62)准确率更高。那么我们应该说RF模型是最好的模型吗?不!准确性(Accuracy)并不总是用于评估分类模型的最佳指标。例如,假设我们要预测的是100次中只有1次发生的事情。我们可以建立一个模型,说这个事件从来没有发生过,从而获得99%的准确率。然而,我们真正关心的事件却获得了0%的正确率。其实,这里的0%是另一个性能度量,称为recall(召回率)。
recall_score
Recall召回率是您正确预测的positive事件的分数,如下所示:
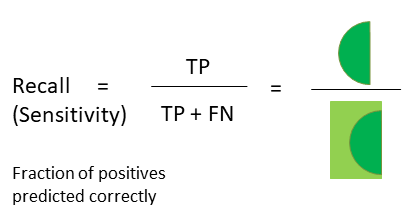
我们可以从scikit-learn获得recall score,它以实际标签和预测标签作为输入:
from sklearn.metrics importrecall_score
recall_score(df.actual_label.values,df.predicted_RF.values)
复制recall_score来定义您自己的函数,使用上面的公式。
def my_recall_score(y_true,y_pred):
#calculates the fraction of positive samples predicted correctly
TP,FN,FP,TN = find_conf_matrix_values(y_true,y_pred)
return # your code here
assert my_recall_score(df.actual_label.values,df.predicted_RF.values)
== recall_score(df.actual_label.values,df.predicted_RF.values),
'my_accuracy_score failed on RF'
assert my_recall_score(df.actual_label.values,df.predicted_LR.values)
== recall_score(df.actual_label.values,df.predicted_LR.values),
'my_accuracy_score failed on LR'
print('Recall RF:%.3f'%(my_recall_score(df.actual_label.values,
df.predicted_RF.values)))
print('Recall LR:%.3f'%(my_recall_score(df.actual_label.values,
df.predicted_LR.values)))
提高召回率的一种方法是通过降低predicted positive的阈值来增加predictedpositive的样本数。但是,这也会增加false positive的数量。另一个称为精确度(precision)的性能指标考虑到了这一点。
precision_score
Precision(精确度)是实际为正的事件所占总的预测阳性事件的比,如下所示:
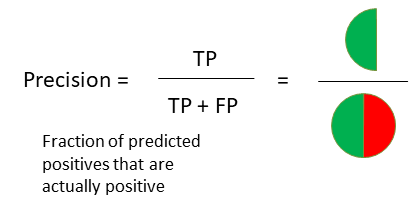
我们可以从scikit-learn获得precision score,它以实际标签和预测标签作为输入:
from sklearn.metrics importprecision_score
precision_score(df.actual_label.values,df.predicted_RF.values)
复制precision_score来定义您自己的函数,使用上面的公式。
def my_precision_score(y_true, y_pred):
#calculates the fraction of predicted positives samples that
are actuallypositive
TP,FN,FP,TN = find_conf_matrix_values(y_true,y_pred)
return # your code here
assert my_precision_score(df.actual_label.values,
df.predicted_RF.values) == precision_score(df.actual_label.values,
df.predicted_RF.values), 'my_accuracy_score failed on RF'
assertmy_precision_score(df.actual_label.values,
df.predicted_LR.values) ==precision_score(df.actual_label.values,
df.predicted_LR.values),'my_accuracy_score failed on LR'
print('Precision RF:%.3f'%(my_precision_score(df.actual_label.values,
df.predicted_RF.values)))
print('Precision LR:%.3f'%(my_precision_score(df.actual_label.values,
df.predicted_LR.values)))
在这种情况下,看起来RF模型在召回率和精确度方面都更好。但如果一个模型在召回率上更好,另一个在精度上更好,你会怎么做?一些数据科学家使用的方法称为F1 score。
f1_score
f1 score是召回率和精确度的调和平均值,得分越高越好。f1 score的计算公式如下:
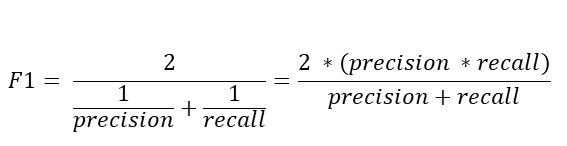
我们可以从scikit-learn获得f1 score,它以实际标签和预测标签作为输入:
from sklearn.metrics importf1_score
f1_score(df.actual_label.values,df.predicted_RF.values)
复制f1_score来定义您自己的函数,使用上面的公式。
def my_f1_score(y_true,y_pred):
#calculates the F1 score
recall = my_recall_score(y_true,y_pred)
precision = my_precision_score(y_true,y_pred)
return# your code here
assert my_f1_score(df.actual_label.values,df.predicted_RF.values) ==
f1_score(df.actual_label.values,df.predicted_RF.values),
'my_accuracy_score failed on RF'
assert my_f1_score(df.actual_label.values,df.predicted_LR.values) ==
f1_score(df.actual_label.values,df.predicted_LR.values),
'my_accuracy_score failed on LR'
print('F1 RF:%.3f'%(my_f1_score(df.actual_label.values,
df.predicted_RF.values)))
print('F1 LR:%.3f'%(my_f1_score(df.actual_label.values,
df.predicted_LR.values)))
到目前为止,我们假设我们定义了0.5的阈值,用于选择哪些样本被预测为正样本。如果我们更改此阈值,性能指标将会发生变化。如下所示:
print('scores with threshold= 0.5')
print('Accuracy RF:%.3f'%(my_accuracy_score(df.actual_label.values,
df.predicted_RF.values)))
print('Recall RF:%.3f'%(my_recall_score(df.actual_label.values,
df.predicted_RF.values)))
print('Precision RF:%.3f'%(my_precision_score(df.actual_label.values,
df.predicted_RF.values)))
print('F1 RF:%.3f'%(my_f1_score(df.actual_label.values,
df.predicted_RF.values)))
print(' ')
print('scores with threshold = 0.25')
print('Accuracy RF:%.3f'%(my_accuracy_score(df.actual_label.values,
(df.model_RF >=0.25).astype('int').values)))
print('Recall RF:%.3f'%(my_recall_score(df.actual_label.values,
(df.model_RF >=0.25).astype('int').values)))
print('Precision RF: %.3f'%(my_precision_score(df.actual_label.values,
(df.model_RF >= 0.25).astype('int').values)))
print('F1 RF:%.3f'%(my_f1_score(df.actual_label.values,
(df.model_RF >=0.25).astype('int').values)))

如果我们最初没有选择一个阈值,我们如何评估模型?一种非常常见的方法是使用ROC曲线。
roc_curve 和 roc_auc_score
ROC曲线非常有助于理解真阳性率(true-positive rate)和假阳性率(false positive rates)之间的平衡。 Scikit learn为实现和分析ROC曲线构建了函数。这些函数的输入(roc_curve和roc_auc_score)是实际标签和预测概率(不是预测标签)。
roc_curve和roc_auc_score都是复杂的函数,所以我们不会让你从头开始编写这些函数。相反,我们将向您展示如何使用scikit learn中的函数来实现并解释关键点。让我们先用roc_curve来做ROC图。
from sklearn.metrics importroc_curve
fpr_RF, tpr_RF, thresholds_RF =roc_curve(df.actual_label.values,
df.model_RF.values)
fpr_LR, tpr_LR, thresholds_LR =roc_curve(df.actual_label.values,
df.model_LR.values)
roc_curve函数返回三个列表:
thresholds = 按降序排列的所有唯一预测概率
fpr = 每个阈值的假阳性率(FP/ (FP + TN))
tpr = 每个阈值的真阳性率(TP/ (TP + FN))
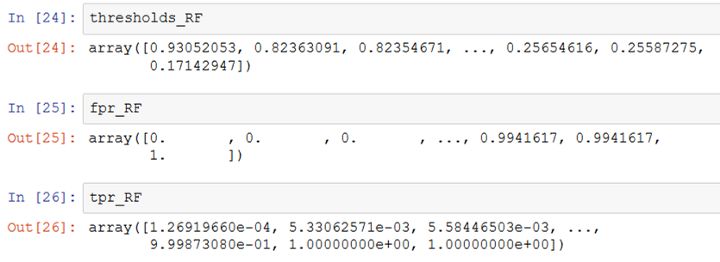
我们可以绘制每个模型的ROC曲线,如下所示。
import matplotlib.pyplot asplt
plt.plot(fpr_RF, tpr_RF,'r-',label = 'RF')
plt.plot(fpr_LR,tpr_LR,'b-', label= 'LR')
plt.plot([0,1],[0,1],'k-',label='random')
plt.plot([0,0,1,1],[0,1,1,1],'g-',label='perfect')
plt.legend()
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.show()
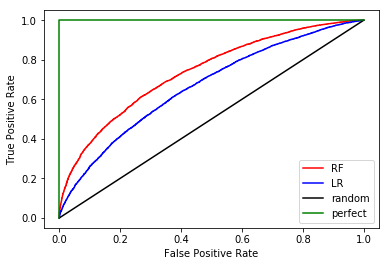
我们可以从这个图中得到一些结论:
一个随机猜测标签的模型应该如黑色的线所表示的那样,你想要一个在黑线之上有一条曲线的模型
距离黑线较远的ROC更好,因此RF(红色)看起来比LR(蓝色)好
虽然没有直接看到,但是高阈值会产生左下角的点,低阈值产生了右上角的点。这意味着当您降低阈值时,您将获得更高的TPR,但代价是更高的FPR
为了分析性能,我们将使用area-under-curve(曲线下面积)这一度量指标.
from sklearn.metrics importroc_auc_score
auc_RF = roc_auc_score(df.actual_label.values,df.model_RF.values)
auc_LR = roc_auc_score(df.actual_label.values,df.model_LR.values)
print('AUC RF:%.3f'% auc_RF)
print('AUC LR:%.3f'% auc_LR)
如您所见,RF模型的曲线下面积(AUC = 0.738)优于LR(AUC = 0.666)。当我绘制ROC曲线时,我喜欢在图例中添加AUC,如下所示。
import matplotlib.pyplot asplt
plt.plot(fpr_RF, tpr_RF,'r-',label = 'RF AUC:%.3f'%auc_RF)
plt.plot(fpr_LR,tpr_LR,'b-', label= 'LR AUC:%.3f'%auc_LR)
plt.plot([0,1],[0,1],'k-',label='random')
plt.plot([0,0,1,1],[0,1,1,1],'g-',label='perfect')
plt.legend()
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.show()
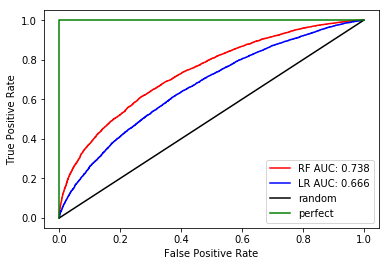
总的来说,在这个示例中,模型RF在每个性能指标上都是获胜的。
总结
在预测分析中,当在两个模型之间做决定时,选择单个性能指标非常重要。正如您在此处所看到的,您可以选择许多(准确度,召回率,精确度,f1-score,AUC等等)。最终,您应该使用最适合当前业务问题的性能度量。许多数据科学家更喜欢使用AUC来分析每个模型的性能,因为它不需要选择阈值并有助于平衡真阳性率(true positive rate)和假阳性率(false positiverate)。
参考链接:
https://towardsdatascience.com/understanding-data-science-classification-metrics-in-scikit-learn-in-python-3bc336865019
-END-
专 · 知
人工智能领域主题知识资料查看与加入专知人工智能服务群:
专知AI知识技术服务会员群加入与人工智能领域26个主题知识资料全集获取。欢迎微信扫一扫加入专知人工智能知识星球群,获取专业知识教程视频资料和与专家交流咨询!

请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请加专知小助手微信(扫一扫如下二维码添加),加入专知主题群(请备注主题类型:AI、NLP、CV、 KG等)交流~

AI 项目技术 & 商务合作:bd@zhuanzhi.ai, 或扫描上面二维码联系!
请关注专知公众号,获取人工智能的专业知识!
点击“阅读原文”,使用专知
展开全文



