一步步构建推荐系统
【导读】推荐系统是数据科学中最常用和易于理解的应用之一。虽然在这个领域有很多工作,但互联网的快速发展和信息过载问题,这方面的兴趣和需求仍然很高。在线企业必须帮助用户处理信息过载并向他们提供个性化的推荐,内容和服务。
推荐系统的两种最流行的方法是协同过滤和基于内容的推荐。在这篇文章中,我们将重点关注协同过滤方法,即:用户是过去喜欢具有相似品味和偏好的人的推荐项目。换句话说,该方法通过使用用户之间的相似性来预测未知评分。
我们将使用由Nicolas Hug建立的Surprise库,Book-Crossing和一个用于开发推荐系统算法的书籍评分数据集。
作者:Susan Li
数据
Book-Crossing数据包括三个表,我们将使用其中两个:users表和book rating表。
user = pd.read_csv('BX-Users.csv', sep=';', error_bad_lines=False, encoding="latin-1")
user.columns = ['userID', 'Location', 'Age']
rating = pd.read_csv('BX-Book-Ratings.csv', sep=';', error_bad_lines=False, encoding="latin-1")
rating.columns = ['userID', 'ISBN', 'bookRating']
df = pd.merge(user, rating, on='userID', how='inner')
df.drop(['Location', 'Age'], axis=1, inplace=True)
df.head()
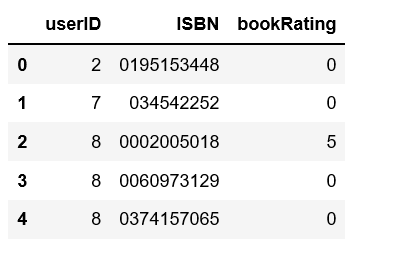
简单的数据分析
评分分布
from plotly.offline import init_notebook_mode, plot, iplotimport plotly.graph_objs as goinit_notebook_mode(connected=True)data = df['bookRating'].value_counts().sort_index(ascending=False)trace = go.Bar(x = data.index, text = ['{:.1f} %'.format(val) for val in (data.values / df.shape[0] * 100)], textposition = 'auto', textfont = dict(color = '#000000'), y = data.values, )# Create layoutlayout = dict(title = 'Distribution Of {} book-ratings'.format(df.shape[0]), xaxis = dict(title = 'Rating'), yaxis = dict(title = 'Count'))# Create plotfig = go.Figure(data=[trace], layout=layout)iplot(fig)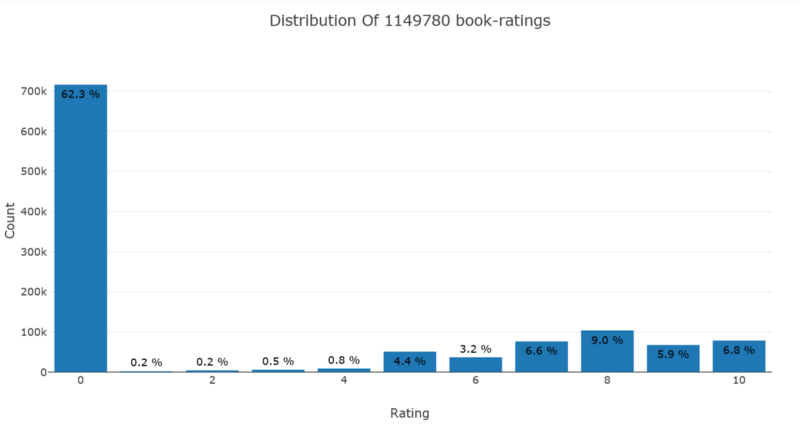
我们可以看到,数据中超过62%的评分为0,很少有评分为1或2或3,低评级书籍意味着它们通常非常糟糕。
根据书籍对评分分布进行计算
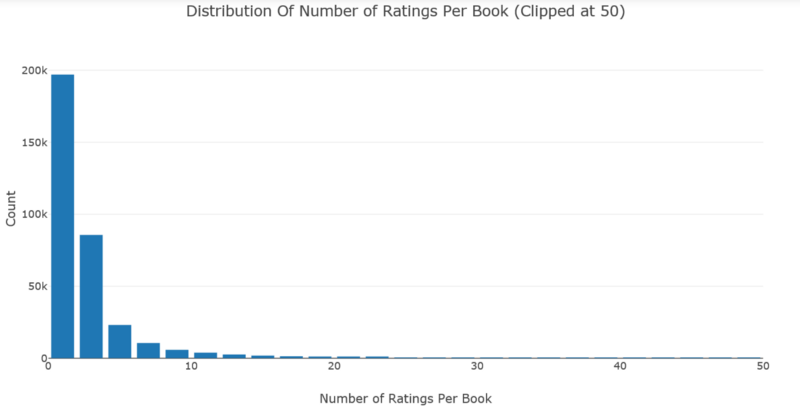
# Number of ratings per bookdata = df.groupby('ISBN')['bookRating'].count().clip(upper=50)# Create tracetrace = go.Histogram(x = data.values,name = 'Ratings',xbins = dict(start = 0,end = 50,size = 2))# Create layoutlayout = go.Layout(title = 'Distribution Of Number of Ratings Per Book (Clipped at 100)',xaxis = dict(title = 'Number of Ratings Per Book'),yaxis = dict(title = 'Count'),bargap = 0.2)# Create plotfig = go.Figure(data=[trace], layout=layout)iplot(fig)
df.groupby('ISBN')['bookRating'].count().reset_index().sort_values('bookRating', ascending=False)[:10]
数据中的大多数书籍收到的评分不到5个,很少有书籍有很多评级,尽管评分最高的书籍收到了2,502个评分。
用户评分分布
# Number of ratings per userdata = df.groupby('userID')['bookRating'].count().clip(upper=50)# Create tracetrace = go.Histogram(x = data.values,name = 'Ratings',xbins = dict(start = 0,end = 50,size = 2))# Create layoutlayout = go.Layout(title = 'Distribution Of Number of Ratings Per User (Clipped at 50)',xaxis = dict(title = 'Ratings Per User'),yaxis = dict(title = 'Count'),bargap = 0.2)# Create plotfig = go.Figure(data=[trace], layout=layout)iplot(fig)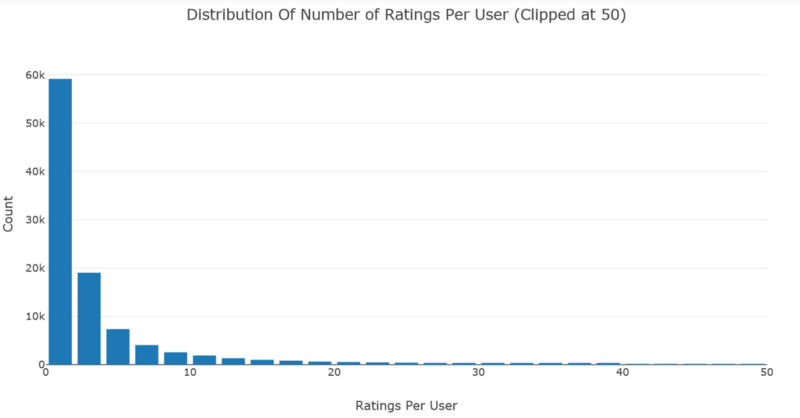
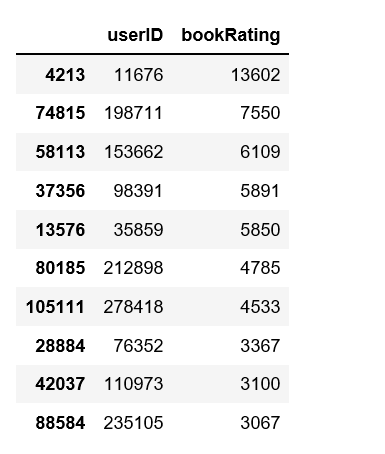
df.groupby('userID')['bookRating'].count().reset_index().sort_values('bookRating', ascending=False)[:10]
数据中的大多数用户给出的评分低于5,而且用户评分很高,尽管效率最高的用户给出了13,602个评分。
注意到,上面两个图表共享相同的分布。 每部电影的评分数量和每位用户的评分数量呈指数级衰减。
为了减少数据集的维度,并避免遇到“内存错误”,我们将过滤掉很少评级的电影,很少评级用户。
min_book_ratings = 50filter_books = df['ISBN'].value_counts() > min_book_ratingsfilter_books = filter_books[filter_books].index.tolist()min_user_ratings = 50filter_users = df['userID'].value_counts() > min_user_ratingsfilter_users = filter_users[filter_users].index.tolist()df_new = df[(df['ISBN'].isin(filter_books)) & (df['userID'].isin(filter_users))]print('The original data frame shape:\t{}'.format(df.shape))print('The new data frame shape:\t{}'.format(df_new.shape))

Surprise
reader = Reader(rating_scale=(0, 9))data = Dataset.load_from_df(df_new[['userID', 'ISBN', 'bookRating']], reader)
要从上面的pandas数据框加载数据集,我们将使用load_from_df()方法,我们还需要一个Reader对象,并且必须指定rating_scale参数。 数据框必须有三列,对应于用户ID,项ID和此顺序中的评级。 因此,每行对应于给定的评级。
使用Surprise库中包含以下算法:
基本算法
NormalPredictor 算法根据训练集的分布预测随机评分。 这是最基本的算法之一,没有做太多工作。
BaselineOnly 算法预测给定用户和项目的基线估计。
k-NN算法
KNNBasic 基本协同过滤算法
KNNWithMeans 考虑平均评分的基本协同过滤算法
KNNWithZScore 考虑Z-score的基本协同过滤算法
KNNBaseline 考虑baseline打分的基本协同过滤算法
基于矩阵分解的算法:SVD、SVDpp、NMF算法
其他:SlopeOne,Coclustering
使用rmse作为评估标准
benchmark = []# Iterate over all algorithmsfor algorithm in [SVD(), SVDpp(), SlopeOne(), NMF(), NormalPredictor(), KNNBaseline(), KNNBasic(), KNNWithMeans(), KNNWithZScore(), BaselineOnly(), CoClustering()]:# Perform cross validation results = cross_validate(algorithm, data, measures=['RMSE'], cv=3, verbose=False) # Get results & append algorithm name tmp = pd.DataFrame.from_dict(results).mean(axis=0) tmp = tmp.append(pd.Series([str(algorithm).split(' ')[0].split('.')[-1]], index=['Algorithm'])) benchmark.append(tmp) pd.DataFrame(benchmark).set_index('Algorithm').sort_values('test_rmse')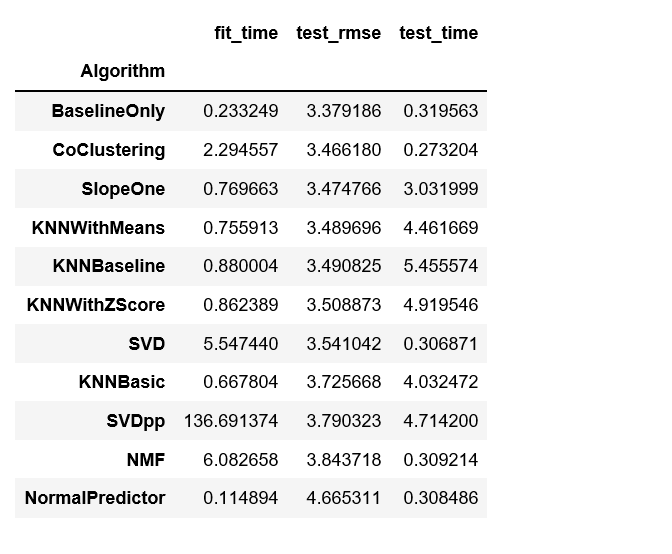
训练和预测
BaselineOnly的rmse最高,因此,我们将使用BaselineOnly训练和预测并使用交替最小二乘法(ALS)作为损失。
print('Using ALS')bsl_options = {'method': 'als','n_epochs': 5,'reg_u': 12,'reg_i': 5 }algo = BaselineOnly(bsl_options=bsl_options)cross_validate(algo, data, measures=['RMSE'], cv=3, verbose=False)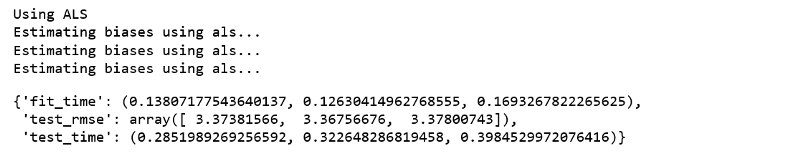
我们使用train_test_split()对具有给定大小的trainset和testset进行采样,并使用rmse的精度度量。 然后我们将使用fit()方法来训练上的算法,test()方法将返回从testset中做出的预测。
trainset, testset = train_test_split(data, test_size=0.25)algo = BaselineOnly(bsl_options=bsl_options)predictions = algo.fit(trainset).test(testset)accuracy.rmse(predictions)

我们构建一个包含所有预测的pandas数据。
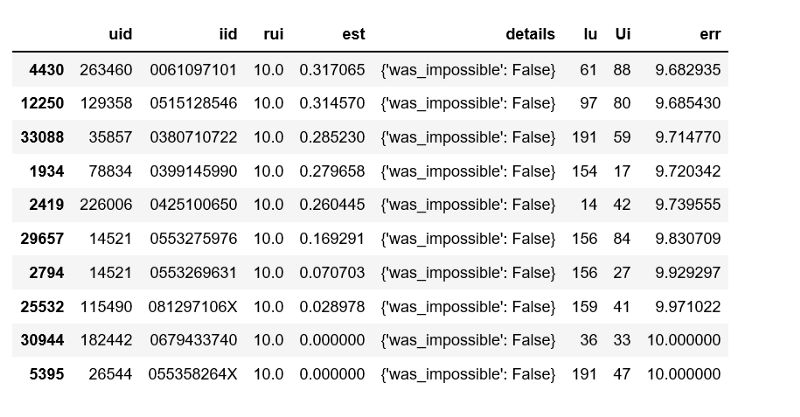
def get_Iu(uid):""" return the number of items rated by given user args: uid: the id of the user returns: the number of items rated by the user """try:return len(trainset.ur[trainset.to_inner_uid(uid)])except ValueError: # user was not part of the trainsetreturn 0 def get_Ui(iid):""" return number of users that have rated given item args: iid: the raw id of the item returns: the number of users that have rated the item. """try: return len(trainset.ir[trainset.to_inner_iid(iid)])except ValueError:return 0 df = pd.DataFrame(predictions, columns=['uid', 'iid', 'rui', 'est', 'details'])df['Iu'] = df.uid.apply(get_Iu)df['Ui'] = df.iid.apply(get_Ui)df['err'] = abs(df.est - df.rui)best_predictions = df.sort_values(by='err')[:10]worst_predictions = df.sort_values(by='err')[-10:]最好的预测结果:
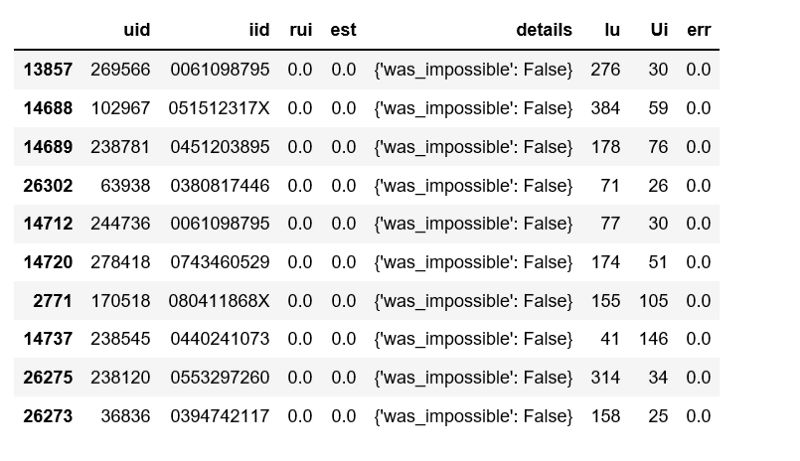
最差的预测结果:
import matplotlib.pyplot as plt%matplotlib notebookdf_new.loc[df_new['ISBN'] == '055358264X']['bookRating'].hist()plt.xlabel('rating')plt.ylabel('Number of ratings')plt.title('Number of ratings book ISBN 055358264X has received')plt.show();
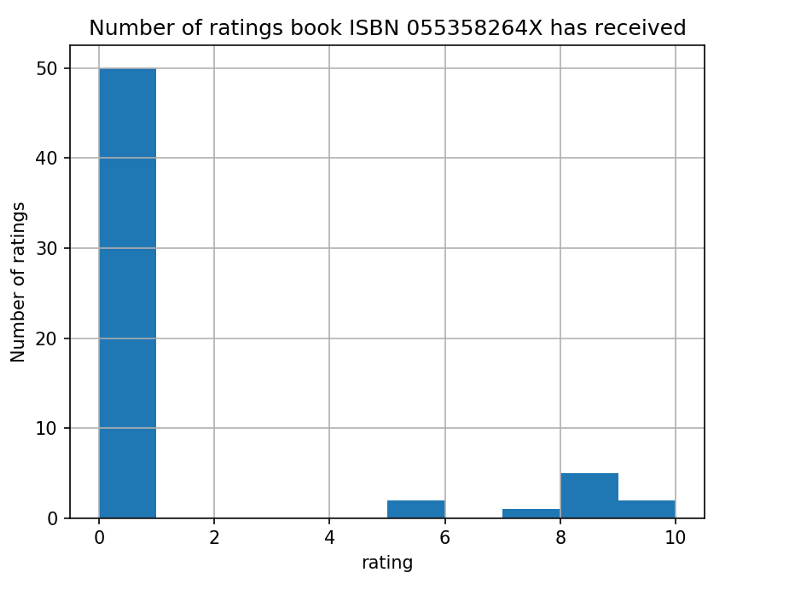
事实证明,该书大多数评分为0,换句话说,数据中的大多数用户将本书评为0,只有极少数用户评为10.与“最差预测”列表中的其他预测相同。 似乎对于每个预测,用户都是某种局外人。
原文链接:
https://towardsdatascience.com/building-and-testing-recommender-systems-with-surprise-step-by-step-d4ba702ef80b
-END-
专 · 知
专知,专业可信的人工智能知识分发,让认知协作更快更好!欢迎登录www.zhuanzhi.ai,注册登录专知,获取更多AI知识资料!
欢迎微信扫一扫加入专知人工智能知识星球群,获取最新AI专业干货知识教程视频资料和与专家交流咨询!

请加专知小助手微信(扫一扫如下二维码添加),加入专知人工智能主题群,咨询技术商务合作~

专知《深度学习:算法到实战》课程全部完成!530+位同学在学习,现在报名,限时优惠!网易云课堂人工智能畅销榜首位!

点击“阅读原文”,了解报名专知《深度学习:算法到实战》课程
展开全文



