AI与深度学习重点回顾:Denny Britz眼中的2017
【导读】近日,博客WILDML的作者Denny Britz把他眼中的2017年AI和深度学习的大事进行了一番梳理和总结:从AlphaGo的自主学习到AlphaGo Zero的强化学习、进化算法的东山再起、谷歌WaveNet的应用、注意力机制大显身手、各种优秀的深度学习开源框架面世、以及深度学习应用在各领域取得重大突破,另外关于如何理性看待AI产业化的发展等。Denny Britz在其博客中都进行了深入浅出的阐述。专知内容组编辑整理。

2017年即将结束,今年我发布的年度回顾内容并没有我一开始计划的那么多。但我希望明年能有所改变,比如包含更多强化学习,进化计算以及贝叶斯方法的内容。新年最好的开启方式当然是来总结一下2017年出现的各种令人惊艳的新发现了。回顾这一年我在Twitter和WildML上发布的消息,你会发现一些主题多次重复出现,这些肯定也是重要内容,我将把它们一一列出。当然我也会不可避免地遗漏一些重要事件,所以对于任何遗漏请在评论中告诉我们。
▌强化学习称霸人类游戏
强化学习最成功的一个例子可能是AlphaGo(这篇发表在Nature上的论文),它用一个强化学习学习代理击败了世界上最好的围棋选手。由于围棋具有非常大的搜索空间,所以围棋曾经被认为在一段时间内是超出机器学习能力解决范围的。而AlphaGo的成就则颠覆了这一认识!
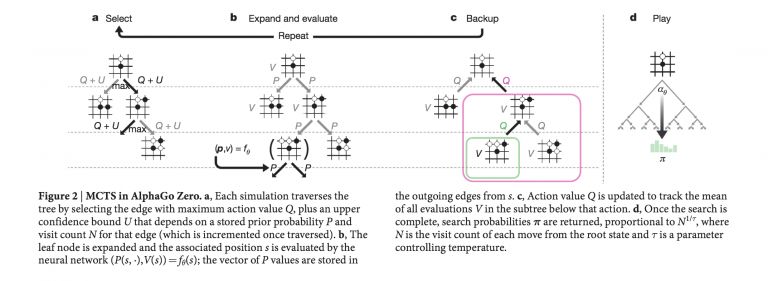
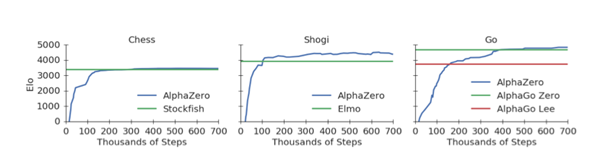
AlphaGo的第一个版本使用来自人类专家的训练数据进行引导,并通过自主学习和对蒙特卡洛树(Monte-Carlo Tree)搜索的适应得到了进一步的提升。不久之后,AlphaGo Zero(在Nature上发表)更进了一步,使用一种之前发表在“Thinking Fast and Slow with Deep Learning and Tree Search”中的技术,学会了从无到有,无需任何人工训练数据来自我对弈。此外AlphaGo Zero还轻松击败了AlphaGo的第一个版本。在今年年底,我们又看到了AlphaGo Zero算法的另一种推广,它被称为AlphaZero,它不仅掌握了围棋,使用相同的技术,它还掌握了国际象棋和将棋。有趣的是,这些程序让那些专业的围棋手都感到惊讶,促使他们从AlphaGo中学习,并相应地调整自己的作战风格。为了使这个更容易,DeepMind团队还发布了AlphaGo Teach工具。
但是围棋并不是我们取得重大进展的唯一游戏。来自CMU的研究人员开发的一个系统——Libratus(在Science发表的论文),在一场为期20天的德州扑克锦标赛中成功击败了顶级扑克玩家。在这之前,来自查尔斯大学,捷克技术大学和阿尔伯塔大学的研究人员开发的DeepStack系统成为第一个击败职业扑克玩家的系统。注意,DeepStack和Libratus这两种系统都是在两名玩家之间进行的,比在多名玩家的桌子上玩更容易。后者很可能会在2018年有更进一步地发展。
强化学习的下一个领域似乎是更复杂的多人游戏,包括多人扑克。DeepMind团队正在积极研究“星际争霸2”,发布研究训练环境,同时OpenAI在1v1 dota2中崭露头角,他们的目标是在不久的将来实现全面的5v5游戏。
AlphaGo:
https://storage.googleapis.com/deepmind-media/alphago/AlphaGoNaturePaper.pdf
AlphaGo Zero:
https://www.nature.com/articles/nature24270.epdf
AlphaZero:
https://arxiv.org/abs/1712.01815
Thinking Fast and Slow with Deep Learning and Tree Search:
https://arxiv.org/abs/1705.08439
Libratus论文:
http://science.sciencemag.org/content/early/2017/12/15/science.aao1733.full
▌进化算法卷土重来
基于梯度的反向传播算法在监督学习中一直都非常有效。而且这种情况在短期内会一直保持。然而,在强化学习中,进化策略(Evolution Strategies)似乎正在卷土重来。由于数据通常不是iid(独立同分布的),因此错误信号更加稀疏,而且由于需要进行探索,所以不依赖于梯度的算法可以很好地工作。此外,进化算法可以对成千上万的机器进行线性扩展,从而实现快速并行训练。它们不需要昂贵的GPU,但可以用大量(通常是成百上千)廉价的CPU来进行训练。
今年早些时候,OpenAI的研究人员证明,进化策略可以达到与标准强化学习算法(如Deep Q-Learning)类似的性能。今年年底,Uber的一个团队发表了一篇博文和五篇研究论文,进一步证明了遗传算法和新颖性搜索的潜能。使用一种极其简单的遗传算法,并且没有任何梯度信息,他们的算法学习玩难度大的Atary游戏。这里有一段关于Frostbite得分为10500的GA策略的视频。在这个游戏中,DQN,AC3和ES得分低于1000。
▌WaveNets, CNNs 以及 Attention Mechanisms
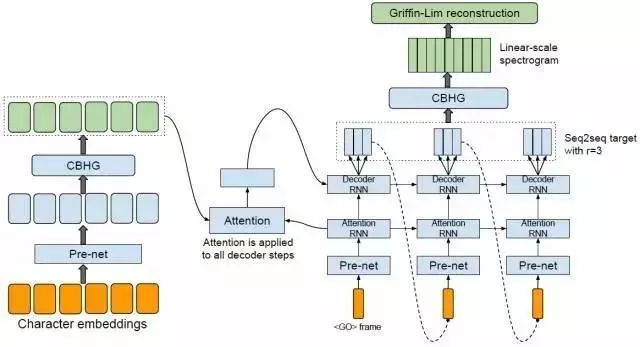
谷歌的Tacotron 2文本转语音系统产生了非常令人印象深刻的音频样本,并基于WaveNet,这是一种自回归模型,也被部署在谷歌助手中,并在过去一年中有了巨大的速度提升。WaveNet之前也被应用于机器翻译,从而加快了回归架构的训练时间。
在机器学习的子领域中,从花费很长时间来训练的昂贵的回归架构中走出来,似乎是更大的趋势。
在“Attention is All you Need”方面,研究人员完全摆脱了递归和卷积,并使用更复杂的Attention Mechanisms来达到训练的效果,而这只是训练成本的一小部分。
论文地址:https://arxiv.org/abs/1706.03762
▌深度学习框架年
如果我必须用一句话总结2017年的话,那将是2017年是框架的一年。Facebook用PyTorch引起了轰动。由于其动态图结构与Chainer所提供的类似,PyTorch得到了自然语言处理研究者的钟爱,他们经常需要处理在Tensorflow等静态图形框架中很难声明的动态和循环结构。
Tensorflow在2017年有相当大的发展。Tensorflow 1.0与一个稳定且向后兼容的API在2月份被发布。目前,Tensorflow的版本是1.4.1。除主框架之外,还发布了多个Tensorflow伴随库,包括用于动态计算图的Tensorflow折叠,用于数据输入管道的Tensorflow变换以及DeepMind的更高级别的Sonnet库。Tensorflow团队还宣布了一种新的热切执行模式,其工作方式类似于PyTorch的动态计算图。
除Google和Facebook之外,许多其他公司也加入了机器学习框架的潮流:
苹果公司发布了CoreML移动机器学习库。
Uber的一个团队发布了Pyro,一种深度概率编程语言(Deep Probabilistic Programming Language)。
亚马逊(Amazon)宣布在MXNet上提供更高级别的API,即Gluon。
Uber公布了其内部米开朗基罗机器学习基础设施平台的详细信息。
而且由于框架的数量越来越多,已经失控,Facebook和微软宣布了ONNX开放格式,以便跨框架共享深度学习模型。例如,你可以在一个框架中训练你的模型,然后在另一个框架中进行应用。
除了通用的深度学习框架外,我们还看到大量的强化学习(Reinforcement Learning)框架被发布,其中包括:
OpenAI Roboschool是一款用于机器人仿真的开源软件。
https://blog.openai.com/roboschool/
OpenAI Baselines是一套高质量强化学习实现的算法。
https://github.com/openai/baselines
Tensorflow代理包含优化的基础结构,用于使用Tensorflow来训练Reinforcement Learning代理。
https://github.com/tensorflow/agents
Unity ML Agents允许研究人员和开发人员使用Unity Editor创建游戏和模拟,并使用强化学习进行训练。
https://github.com/Unity-Technologies/ml-agents
Nervana Coach允许使用最先进的强化学习算法进行实验。
http://coach.nervanasys.com/
Facebook的ELF平台用于游戏研究。
https://code.facebook.com/posts/132985767285406/introducing-elf-an-extensive-lightweight-and-flexible-platform-for-game-research/
DeepMind Pycolab是一个可定制的gridworld游戏引擎。
https://github.com/deepmind/pycolab
Geek.ai MAgent是一个多代理强化学习的研究平台。
https://github.com/geek-ai/MAgent
为了让深度学习更可得更容易操作,我们也为Web端提供了一些框架,比如Google的deeplearn.js和MIL WebDNN的执行框架。但这其中至少有一个非常流行的框架已经消亡。那就是Theano。在Theano邮件列表的一个公告中,开发人员决定1.0版本将是它的最后一个版本。
▌学习资源
随着深度学习和强化学习越来越受欢迎,越来越多的讲座,训练营和活动已经在2017年被在线录制和发布。以下是我最喜欢的一些:
由OpenAI和加州大学伯克利分校联合主办的Deep RL Bootcamp讲授了关于强化学习基础知识以及最新研究成果的讲座。
斯坦福大学2017年春季版卷积神经网络用于视觉识别课程。也可以查看课程网站。https://www.youtube.com/playlist?list=PL3FW7Lu3i5JvHM8ljYj-zLfQRF3EO8sYv,http://cs231n.stanford.edu/
斯坦福大学2017年冬季版自然语言处理与深度学习课程。也可以查看课程网站。https://www.youtube.com/playlist?list=PL3FW7Lu3i5Jsnh1rnUwq_TcylNr7EkRe6,http://web.stanford.edu/class/cs224n/
斯坦福大学的深度学习理论课程。
https://stats385.github.io/
新的Coursera上的深度学习专业化课程。
https://www.coursera.org/specializations/deep-learning
蒙特利尔大学的深度学习和强化暑期课程。
http://videolectures.net/deeplearning2017_montreal/
加州大学伯克利分校2017年秋季深度强化学习课程。
http://rll.berkeley.edu/deeprlcourse/
Tensorflow Dev Summit上关于深度学习基础知识和相关Tensorflow API的讲话。
https://www.youtube.com/playlist?list=PLOU2XLYxmsIKGc_NBoIhTn2Qhraji53cv
几个学术会议继续在网上发布关于会议的最新进展。如果你想赶上前沿的研究,你可以在网上观看NIPS 2017,ICLR 2017或EMNLP 2017的一些录音。
NIPS 2017:
https://nips.cc/Conferences/2017/Videos
ICLR 2017:
https://www.facebook.com/pg/iclr.cc/videos/
EMNLP 2017:
https://ku.cloud.panopto.eu/Panopto/Pages/Sessions/List.aspx
研究人员也开始在arXiv上发布易懂的教程和论文。以下是我今年最喜欢的一些:
深化强化学习:概述
https://arxiv.org/abs/1701.07274
对工程师的机器学习简介
https://arxiv.org/abs/1709.02840
神经机器翻译
https://arxiv.org/abs/1709.07809
神经机器翻译和序列 - 序列模型:教程
https://arxiv.org/abs/1703.01619
▌应用:人工智能与医学
2017年看到许多关于深度学习技术解决医疗问题和打败人类专家的大胆声明。 有很多炒作,对于不是来自医学背景的人来说是了解真正的突破与进展是很容易的。为了进行全面的回顾,我推荐Luke Oakden-Rayner的“人类医生博士”系列博客文章。我将在这里简要介绍一些发展。
https://lukeoakdenrayner.wordpress.com/2017/04/20/the-end-of-human-doctors-introduction/
在今年的重要新闻中,其中有一个是斯坦福大学的团队发布了深度学习算法的细节以及皮肤科医生在识别皮肤癌方面的工作。 你可以在这里阅读Nature文章。 斯坦福大学的另一个研究小组开发了一种模型,可以比心脏病专家更好地从单导联心电图信号中诊断不规则的心律(诊断心律失常)。

但是今年并非没有失误。DeepMind与NHS的交易中充斥着“不可原谅”的错误。美国国立卫生研究院(NIH)向科学界公布了一个胸部x光数据集,但仔细观察后发现它并不适合训练诊断性人工智能模型。
相关研究:
https://cs.stanford.edu/people/esteva/nature/
https://stanfordmlgroup.github.io/projects/ecg/
▌应用:艺术与生成对抗网络(GANs)
另一个今年开始获得更多关注的应用是图像,音乐,素描和视频的生成模型。
NIPS 2017会议今年首次推出了机器学习创意与设计研讨会。
最受欢迎的应用程序之一是谷歌的QuickDraw,它使用神经网络来识别你的涂鸦。 利用发布的数据集,你甚至可以教机器帮你完成你的绘图。
https://quickdraw.withgoogle.com/
生成对抗网络(GANs)在今年取得重大进展。 例如CycleGAN,DiscoGAN和StarGAN等新模型在生成人脸方面取得了令人印象深刻的成果。 GANs在传统上难以生成逼真的高分辨率图像,但是pix2pixHD的令人印象深刻的结果表明,我们正在努力解决这些问题。GANs会成为新的画笔吗?
相关地址:
CycleGAN
https://arxiv.org/abs/1703.10593
DiscoGAN
https://github.com/carpedm20/DiscoGAN-pytorch
StarGAN
https://github.com/yunjey/StarGAN
▌应用:自动驾驶汽车
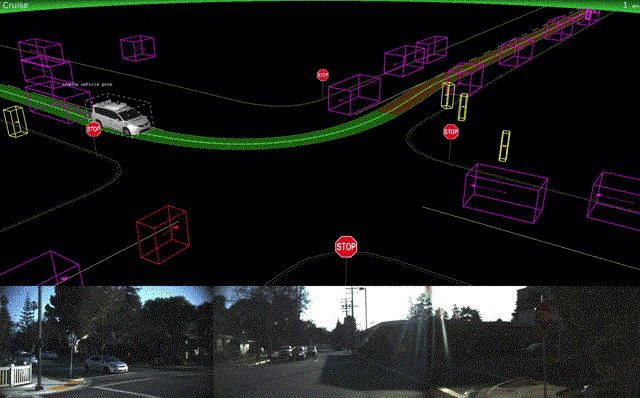
自动驾驶汽车领域的大玩家是拼车软件优步(Uber)和Lyft,Alphabet的Waymo以及特斯拉(Tesla)。 优步(Uber)今年开始的时候遇到了一些挫折,因为他们的自动驾驶汽车在旧金山因软件错误而错过了几次红灯,而之前报道的称这其中没有人为失误。随后,Uber分享了其内部使用的汽车可视化平台的详细信息。在12月,Uber的自驾汽车项目达到了200万英里里程。
与此同时,Waymo的自动驾驶汽车在四月份收获了他们的第一批真正意义上的乘客,后来在亚利桑那州的凤凰城(Phoenix, Arizona)完全取代了人类操作。 Waymo还公布了他们的测试和模拟技术的细节。
Lyft宣布,它正在建立自己的自主驾驶硬件和软件。它在波士顿的第一次试驾正在准备进行中。Tesla Autpilot还没有看到太多的进展消息,但自动驾驶领域出现了一个新的成员:Apple。Tim Cook证实,苹果公司正在研发用于自动驾驶汽车的软件,苹果公司的研究人员在arXiv上发表了一篇个与mapping相关的论文。
▌应用:有趣的研究项目
今年发布了许多有趣的项目和演示,在这里不可能全部提到。但是,这里有一些项目在今年表现很突出:
通过深度学习去除背景
https://towardsdatascience.com/background-removal-with-deep-learning-c4f2104b3157
通过深度学习创作动漫角色
http://make.girls.moe/#/
使用神经网络着色黑白照片
https://blog.floydhub.com/colorizing-b&w-photos-with-neural-networks/
由神经网络操作马里奥赛车(SNES)
https://www.polygon.com/2017/11/5/16610012/mario-kart-mariflow-neural-network-video
实时马里奥卡丁车64 AI(Mario Kart 64 AI)
https://github.com/rameshvarun/NeuralKart
使用深度学习发现赝品
https://www.technologyreview.com/s/609524/this-ai-can-spot-art-forgeries-by-looking-at-one-brushstroke/
猫的随手画成像
https://affinelayer.com/pixsrv/index.html
在更多的研究方面有:
无监督情绪神经元 - 一种学习一种优秀的情感表达方式的系统,尽管它被训练仅仅用来预测亚马逊评论文本中的下一个字符。
学会沟通 - 研究人员开发他们自己的语言。
学习索引结构的案例 - 使用神经网络优化高速缓存优化的B-Tree,速度高达70%,同时为多个实际数据集在内存中的存储节省了数量级的空间。
https://arxiv.org/abs/1712.01208
Attention is All You Need
https://arxiv.org/pdf/1706.03762.pdf
Mask R-CNN - 对象实例分割的一般框架
Deep Image Prior 图像去噪,超分辨率和修补
▌数据集
众所周知,用于监督学习神经网络的数据集是非常匮乏的,因此, 这开放数据集对研究界来说是非常重要的贡献。 以下是今年出现的几个数据集:
1. Youtube Bounding Boxes
https://research.google.com/youtube-bb
2. Google QuickDraw Data
https://quickdraw.withgoogle.com/data
3. DeepMind Open Source Datasets
https://deepmind.com/research/open-source/open-source-datasets
4. Google Speech Commands Dataset
https://research.googleblog.com/2017/08/launching-speech-commands-dataset.html
5. Atomic Visual Actions
https://research.google.com/ava/
6. Several updates to the Open Images data set
https://github.com/openimages/dataset
7. Nsynth dataset of annotated musical notes
https://magenta.tensorflow.org/datasets/nsynth
8. Quora Question Pairs
https://data.quora.com/First-Quora-Dataset-Release-Question-Pairs
▌深度学习、复现性和炼金术
在这一年中,一些研究人员对学术论文结果的可复现性提出了担忧。 深度学习模型通常需要大量的超参数,必须对其进行优化才能获得足够好的结果。 这种优化可能会很麻烦并且成本很高,只有像Google和Facebook这样的公司才能负担得起。 并不是所有的研究人员都把代码公布出来,如果忘了把重要的细节放到最终版本的论文中,或者使用稍微不同的评估程序,或者在同一段数据上过拟合数据以重复优化超参数。 这些细节都会使重现性成为一个大问题。 另外,在强化学习中重现性也是非常重要的。研究人员表明,用不同的代码库实现相同的方法,获得的结果也是大不相同的:
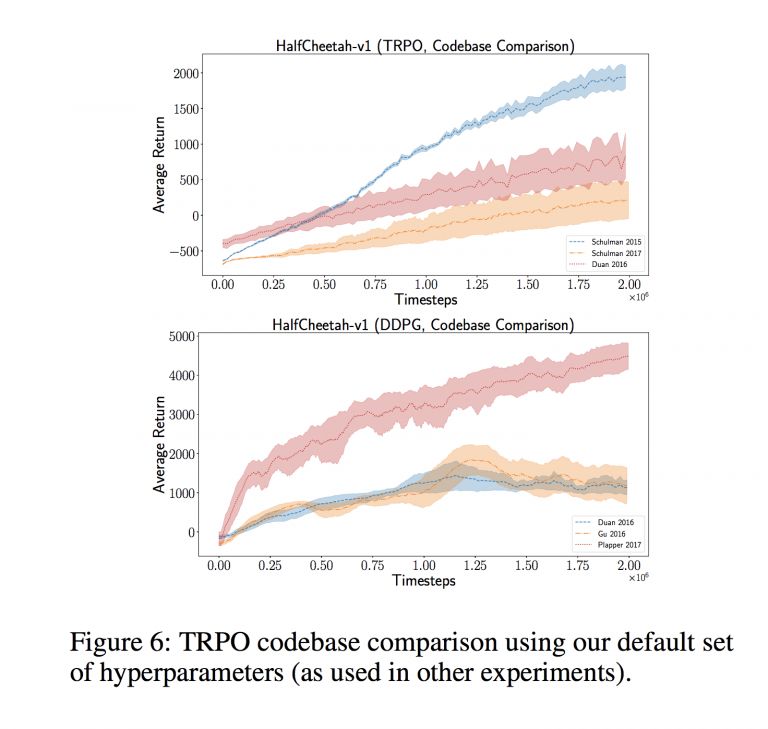
图6:我们在TRPO代码库中使用默认的一组超参数进行比较(按照论文提供的步骤进行)
在论文“Are GANs Created Equal? A Large-Scale Study”中的研究表明,使用昂贵的超参数搜索方法进行调整的GAN可以击败很多更为复杂的方法(这些方法自称是更好的)。 同样,在论文“On the State of the Art of Evaluation in Neural Language Models”,研究人员表明,简单的LSTM架构在正确调整后,可以胜过很多近期提出的模型。
Are GANs Created Equal? A Large-Scale Study
链接:https://arxiv.org/abs/1711.10337
On the State of the Art of Evaluation in Neural Language Models
链接:https://arxiv.org/abs/1707.05589
在NIPS talk引起了许多研究者注意,Ali Rahimi把最近的深度学习方法比作炼金术,并且呼吁设计更严格的实验。Yann LeCun认为这是一种侮辱,并迅速做出回应。
Ali Rahimi
链接:https://www.youtube.com/watch?v=Qi1Yry33TQE

▌加拿大和中国的人工智能
随着美国移民政策收紧,越来越多的公司在海外开设办事处,加拿大成为主要目的地。 Google在多伦多开设了新的办公室,DeepMind在加拿大Edmonton开设了一个新办公室,Facebook AI Research也扩展到了Montreal(蒙特利尔)。
中国是另一个受到很多关注的地方。 由于拥有大量的资金,大量的人才库和政府数据,在人工智能的发展和生产部署方面,中国正在与美国竞争。 Google还宣布即将在北京开设一个新实验室。
▌硬件战争:Nvidia, Intel, Google, Tesla
现代深度学习技术训练先进的模型非常依赖昂贵的GPU。 到目前为止,NVIDIA一直是一家独大。 今年,它宣布了其新的Titan V旗舰GPU。
但是竞争正在加剧。 Google的TPU现在已经在其云平台上使用,英特尔的Nervana推出了一套新的芯片,甚至特斯拉也宣布它正在开发自己的AI硬件。 竞争也可能来自中国,专门从事比特币挖掘的硬件制造商希望进入以人工智能为核心的GPU领域。
▌炒作和失败
大炒作也带来巨大的责任。 主流媒体的报道与实验室或产品系统的实际情况往往不相符。 IBM Watson是过度营销的典范,其根本没有提供相应的结果。 每个人都在讨厌IBM Watson,因为它在医疗方面一再失败。
最出名的炒作可能是Facebook的“研究人员关闭了发明自己语言的AI”(号称其AI能发明自己的语言),这次炒作造成非常恶劣的影响。当然,标题不可能与事实相去甚远。事实应该是,研究人员停止了一项似乎没有取得好结果的标准实验。
但是,媒体炒作不是唯一的罪魁祸首。 研究人员在标题和摘要中不能反映实际的实验结果,比如在这个自然语言生成论文(https://medium.com/@yoav.goldberg/an-adversarial-review-of-adversarial-generation-of-natural-language-409ac3378bd7 ),或者这个针对市场的机器学习论文(http://zacharydavid.com/2017/08/06/fitting-to-noise-or-nothing-at-all-machine-learning-in-markets/ )。
▌高调的招聘和离职
Coursera的联合创始人Andrew Ng今年被多次报道,他的机器学习开发课程(MOOC)非常出名。 Andrew在三月份离开百度的AI团队,筹集了一个1.5亿美元的基金,并宣布开办创业公司landing.ai,专注于制造业。 还有,Gary Marcus辞去了Uber人工智能实验室主任的职务,Facebook聘请了Siri的自然语言理解部门负责人,还有几位着名的研究人员离开了OpenAI,开创新的机器人公司。
学术界正在逐步失去科学家,大学实验室的薪水无法和行业巨头进行竞争。
▌创业投资和收购
伴随着几次高调的收购,AI发展正在如火如荼进行:
Microsoft acquired deep learning startup Maluuba
Google Cloud acquired Kaggle
Softbank bought robot maker Boston Dynamics (which famously does not use much Machine Learning)
Facebook bought AI assistant startup Ozlo
Samsung acquired Fluently to build out Bixby
并且,新公司筹集了大量的资金:
Mythic raised $8.8 million to put AI on a chip
Element AI, a platform for companies to build AI solutions, raised $102M
Drive.ai raised $50M and added Andrew Ng to its board
Graphcore raised $30M
Appier raised a $33M Series C
Prowler.io raised $13M
Sophia Genetics raises $30 million to help doctors diagnose using AI and genomic data
参考链接:
http://www.wildml.com/2017/12/ai-and-deep-learning-in-2017-a-year-in-review/
-END-
专 · 知
人工智能领域主题知识资料查看获取:【专知荟萃】人工智能领域26个主题知识资料全集(入门/进阶/论文/综述/视频/专家等)
请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

点击“阅读原文”,使用专知!
展开全文



