无监督深度学习——这《元监督视觉学习》132页伯克利博士论文带你回顾无监督视觉应用最新发展脉络
【导读】作者Tinghui Zhou,加州大学伯克利分校的博士生,拥有强大的学术背景,是CVPR2017年Image-to-Image Translation with Conditional Adversarial Networks(使用条件Gan经行图像的转换)的作者之一,现在Google学术引用已经1600多了。他的博士论文——元监督视觉学习(Visual Learning Beyond Direct Supervision),主要是针对当前深度学习在解决许多计算机视觉任务方面取得了很大进展,但对于难以或不可能获得标签的任务,进展却有限,这一问题展开,研究如何在不需要任何直接标签的情况下,仍然利用深度学习的计算能力,使用可选的监督信息来学习视觉任务。作者在文中阐述直观上,虽然不知道ground-truth是什么,但我们可能知道它应该满足的各种属性,关键思想是将这些属性形式为学习目标任务的目标函数。并且也表明这类“元监督”,在学习各种视觉任务时竟然是非常有效的。感兴趣的同学可以仔细品味这一系统性的博士论文和其代表性工作。
元学习细节可以参考专知以前文章:
元学习究竟是什么?这《基于梯度的元学习》199页伯克利博士论文带你回顾元学习最新发展脉络
作者简介

Tinghui Zhou
个人主页:
https://people.eecs.berkeley.edu/~tinghuiz/
Tinghui Zhou是加州大学伯克利分校EECS系五年级的博士生,师从Alexei (Alyosha) Efros教授。在此之前我在卡内基梅隆大学获得了机器人学硕士学位,在明尼苏达大学获得了计算机科学学士学位。
博士论文摘要
深度学习在解决许多计算机视觉任务方面取得了很大进展,这些任务的标记数据非常丰富。但是,对于难以或不可能获得标签的任务,进展却是有限的。在本文中,我们提出了不需要直接标注的监督学习的替代方法。直观上,虽然我们不知道标签是什么,但我们可能知道它们应该满足的各种属性。关键思想是将这些属性形式化为监督目标任务的目标函数。我们表明,这种“元监督(meta-supervision)”思想在学习各种视觉任务方面证明是非常有效的。
论文组织如下。第一部分提出使用循环一致性的概念作为监督信息来学习dense语义对应性。第二部分提出用视图合成任务作为监督信息来学习场景几何的不同表示。第三部分提出使用对抗监督来学习渐进式图像转换的方法。最后,我们讨论了元监督的一般概念,以及如何将其应用于本文之外的任务。
其他更多详情,下载全文查看:
请关注专知公众号(扫一扫最下面专知二维码,或者点击上方蓝色专知)
后台回复“MAVL” 就可以获取论文的下载链接~
专知2019年1月将开设一门《深度学习:算法到实战》讲述相关ML2018论文,欢迎关注报名!
专知开课啦!《深度学习: 算法到实战》, 中科院博士为你讲授!
博士论文简介
计算机视觉在图像分类,目标检测,语义分割,人体姿态估计等多个领域都取得了很大的进展。 这种进步很大程度上是由使用深度神经网络的监督学习的快速发展所推动的。这些网络中可训练参数的数量可能在数百万到数十亿之间,这需要大量标记的示例来进行训练。像 ImageNet 和 COCO 这样的数据集是目前许多识别任务的极好的数据集。然而,我们还应该注意到存在一系列的视觉任务,对于这些任务而言,大规模获取标记数据是非常困难的,甚至根本不可行——例如,amodal场景补全、场景流估计(scene flow estimation)、密集对应(dense correspondence)、本征图像分解(intrinsic image decomposition)等等。因此,一个很自然的问题出现了:是否有可能在克服标签稀缺的同时仍然利用深度学习的计算能力?
一种可行的解决方案是计算机模拟,我们使用计算机图形渲染合成环境,以完全控制数据生成过程。虽然这些环境的质量和可用性多年来一直在提高,但是基于这些数据的模型仍然不能直接应用于真实世界,因为呈现的可视化数据与真实世界的可视化数据之间存在着显著的领域差异。另一种可能的解决方案是迁移学习,其中网络权重通过训练某些预训练任务(如ImageNet分类)进行初始化,然后在目标任务上进行微调。该策略在减少目标任务的训练标签数量方面是有效的,但目前仍需要大量标记数据。
在本文中,我们研究如何在不需要任何直接标签的情况下,使用可选的监督信息来学习视觉任务。直观上,虽然我们不知道ground-truth是什么,但我们可能知道它应该满足的各种属性。关键思想是将这些属性形式为学习目标任务的目标函数。正如本文所论证的那样,这类“元监督”,在学习各种视觉任务时竟然是非常有效的。
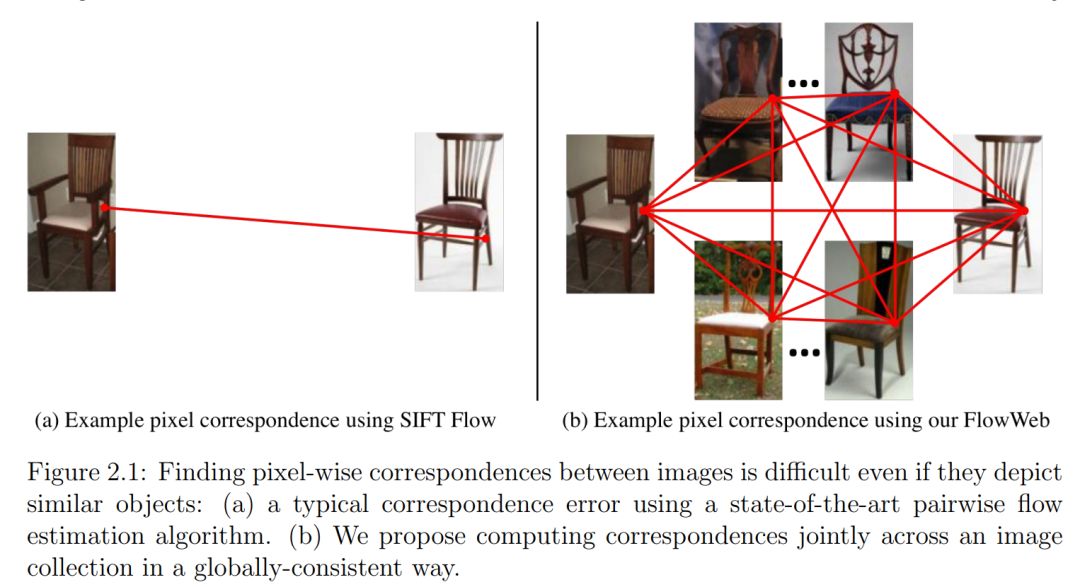
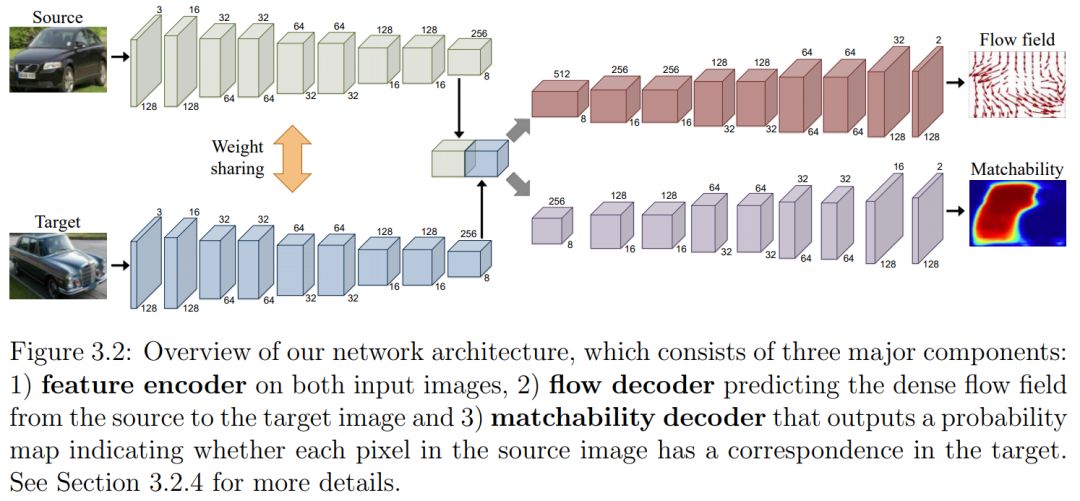
第一部分:学习密集的语义对应(Learning dense semantic correspondence)。我们首先研究了循环一致性的概念,以及如何利用它在图像集合中获得全局一致的语义对应。然后,我们展示了如何使用循环一致性作为监督信号学习成对密集对应。对于这项任务,虽然在真实图像领域收集大规模的ground-truth是不可行的,但我们知道ground-truth应该在同一类别的实例之间保持一致,即使对于合成的实例也是如此。我们使用一致性作为监督来训练深层网络,而无需获得真实领域中的ground-truth对应。
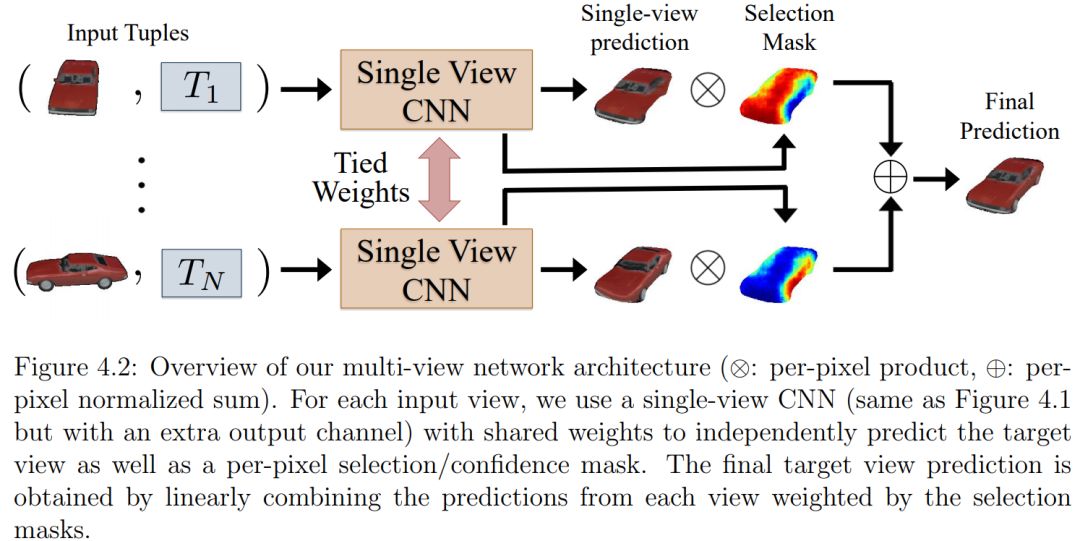
第二部分:学习场景几何(Learning scene geometry)。在此基础上,提出了一种基于视图合成的场景几何学习框架,没有ground-truth几何标签。我们围绕观察来制定学习目标函数,即如果从输入图像中正确预测场景几何,则通过新的视图合成任务来一致解释附近的帧。特别地,我们展示了可以从非结构化视频序列学习单眼深度和相机运动估计,以及从构成图像中学习分层场景表示。
第三部分:学习渐进式图像转换(Learning gradual image transformation)。最后,我们提出利用对抗性网络提供监督信号,以学习渐进式图像转换。通过使用对抗性训练,加上差异损失(提供转换方向)和内容损失(保留所需的输入语义),我们能够训练网络在不直接标记数据的情况下预测渐进式转换。
文章的最后,我们讨论了“元监督(meta-supervision)”的一般概念:监督的不是数据是什么,而是数据应该如何表现,以及如何将其应用于本文之外的各种领域。
本文大纲



参考链接:
https://people.eecs.berkeley.edu/~tinghuiz/
https://www2.eecs.berkeley.edu/Pubs/TechRpts/2018/EECS-2018-128.pdf
请关注专知公众号(扫一扫最下面专知二维码,或者点击上方蓝色专知)
后台回复“MAVL” 就可以获取本文的下载链接~
专 · 知
专知开课啦!《深度学习: 算法到实战》, 中科院博士为你讲授!

请加专知小助手微信(扫一扫如下二维码添加),咨询《深度学习:算法到实战》参团限时优惠报名~

欢迎微信扫一扫加入专知人工智能知识星球群,获取专业知识教程视频资料和与专家交流咨询!

请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

点击“阅读原文”,了解报名专知《深度学习:算法到实战》课程
展开全文



