CVPR2019论文抢鲜看!20篇涵盖目标检测、跨模态、视频处理、语义分割和姿态估计等方向论文
【导读】计算机视觉顶会 CVPR 2019 的论文接前几天公布了接受论文:在超过 5100 篇投稿中,共有 1300 篇被接收,达到了接近 25.2% 的接收率。今天组委会公布口头报告论文(Oral presentation),专知特别整理了最近公布CVPR2019接受论文,涉及目标检测、跨模态、视频处理、语义分割和姿态估计,欢迎查看!

CVPR 作为计算机视觉领域的顶级学术会议,今年共收到了 5165 篇有效提交论文,比去年 CVPR2018 增加了 56%。不久之前,CVPR 2019 官网放出了最终的论文接收结果。据统计,本届大会共接收了 1300 论文,接收率接近 25.2%。
CVPR 2019 论文
目标检测
Generalized Intersection over Union: A Metric and A Loss for Bounding Box Regression
作者:Hamid Rezatofighi, Nathan Tsoi, JunYoung Gwak, Amir Sadeghian, Ian Reid, Silvio Savarese
论文链接:
http://www.zhuanzhi.ai/paper/46c5a1abbe9463bae94409c2ad1acd94

图像分类
Learning a Deep ConvNet for Multi-label Classification with Partial Labels
作者:Thibaut Durand, Nazanin Mehrasa, Greg Mori
论文链接:
http://www.zhuanzhi.ai/paper/fda6443955706ca76ce8c52ce52c8b24
图像处理
Iterative Residual CNNs for Burst Photography Applications
Filippos Kokkinos,Stamatios Lefkimmiatis
http://www.zhuanzhi.ai/paper/c72af348e2ee57d74a0d0d3d884b3b92

Data augmentation using learned transforms for one-shot medical image segmentation
Amy Zhao, Guha Balakrishnan, Frédo Durand, John V. Guttag, Adrian V. Dalca
http://www.zhuanzhi.ai/paper/4af88c0816dd2632069cc84f13d177dc
CollaGAN : Collaborative GAN for Missing Image Data Imputation
Dongwook Lee, Junyoung Kim, Won-Jin Moon, Jong Chul Ye
http://www.zhuanzhi.ai/paper/900e58890d8345f90b9cb488a54aa657
视觉语言跨模态处理
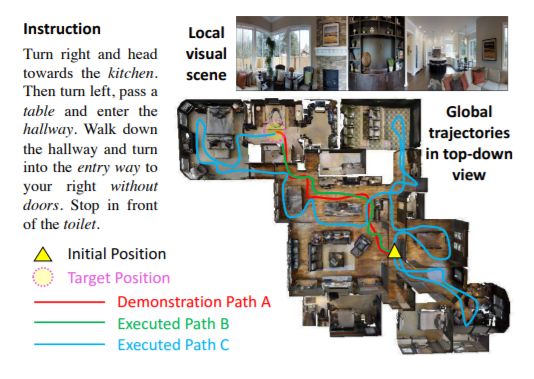
Reinforced Cross-Modal Matching and Self-Supervised Imitation Learning for Vision-Language Navigation
Xin Wang,Qiuyuan Huang,Asli Celikyilmaz,Jianfeng Gao,Dinghan Shen,Yuan-Fang Wang,William Yang Wang,Lei Zhang
论文地址:
http://www.zhuanzhi.ai/paper/6d1e314514c8fdbfb7eba783bde57d99
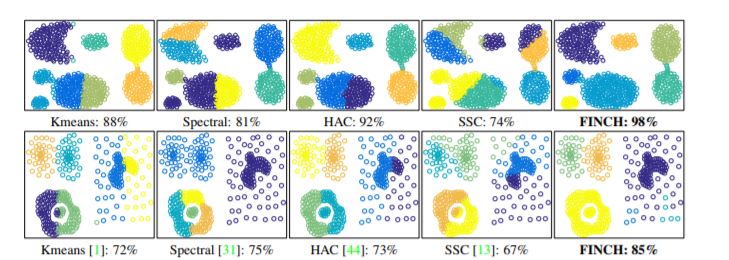
聚类学习
Efficient Parameter-free Clustering Using First Neighbor Relations
M. Saquib Sarfraz, Vivek Sharma, Rainer Stiefelhagen
论文链接:
http://www.zhuanzhi.ai/paper/d87f92bde8eba49b07b3e9594c61e2e9
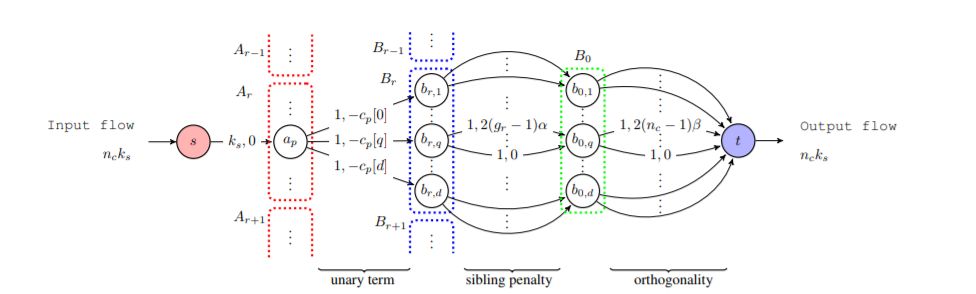
表示学习
End-to-End Efficient Representation Learning via Cascading Combinatorial Optimization
作者:Yeonwoo Jeong, Yoonsuing Kim, Hyun Oh Song
论文链接:
http://www.zhuanzhi.ai/paper/3f90437f7b5cd850702cd151def52c0d
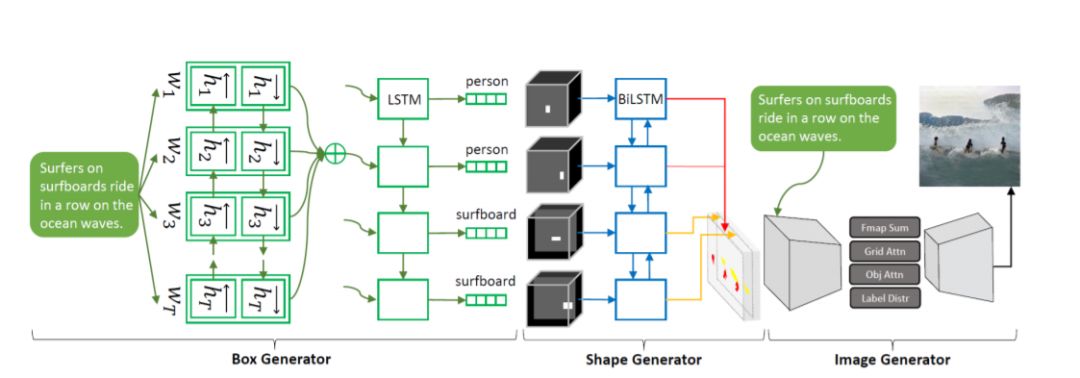
Text-to-Image
Object-driven Text-to-Image Synthesis via Adversarial Training
作者:Wenbo Li, Pengchuan Zhang, Lei Zhang, Qiuyuan Huang, Xiaodong He, Siwei Lyu, Jianfeng Gao
论文链接:
http://www.zhuanzhi.ai/paper/1761a44c2505c82125d839e612eaac40
人脸检测
Joint Face Detection and Facial Motion Retargeting for Multiple Faces
作者:Bindita Chaudhuri, Noranart Vesdapunt, Baoyuan Wang
论文链接:
http://www.zhuanzhi.ai/paper/11554b44077224153d5f553bf1b003b4
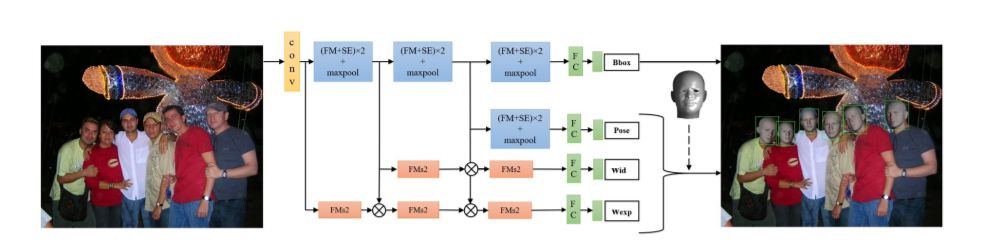
视频处理、分类、描述、分割
Spatio-Temporal Dynamics and Semantic Attribute Enriched Visual Encoding for Video Captioning
Nayyer Aafaq, Naveed Akhtar, Wei Liu, Syed Zulqarnain Gilani, Ajmal Mian
论文链接:
http://www.zhuanzhi.ai/paper/05ba5dda315f921bf0510cea6fe58e41
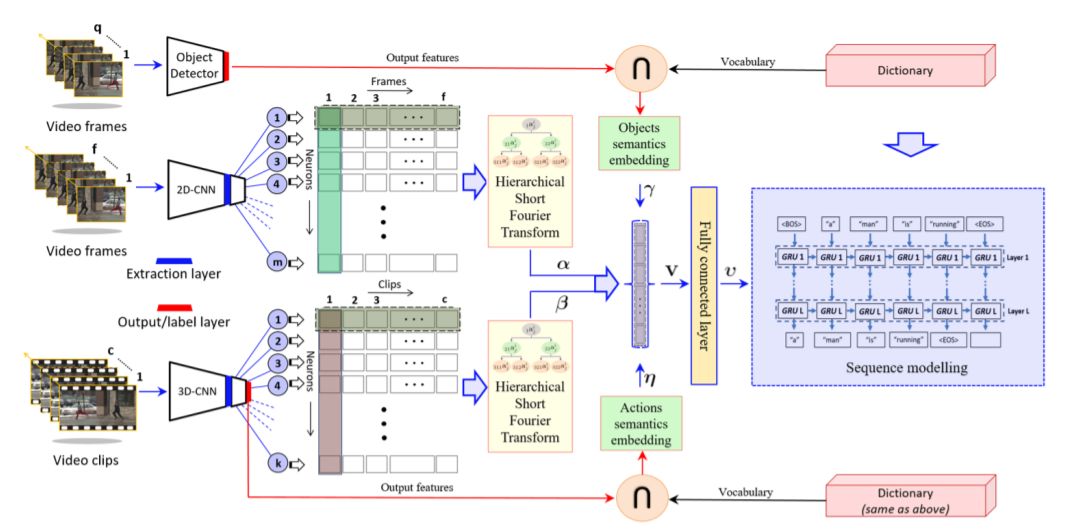
Single-frame Regularization for Temporally Stable CNNs
作者:Gabriel Eilertsen, Rafa? K. Mantiuk, Jonas Unger
论文链接:
http://www.zhuanzhi.ai/paper/479a239277f9cb5f7b5dc8605651631f
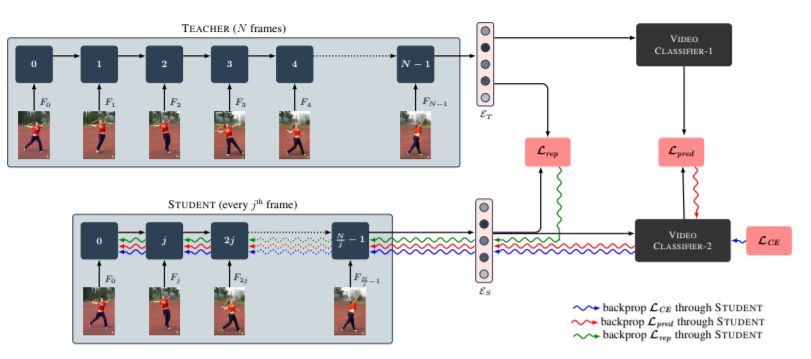
Efficient Video Classification Using Fewer Frames
作者:Shweta Bhardwaj, Mukundhan Srinivasan, Mitesh M. Khapra
论文链接:
http://www.zhuanzhi.ai/paper/2c6aa131c90428629cdb4c10be60044d
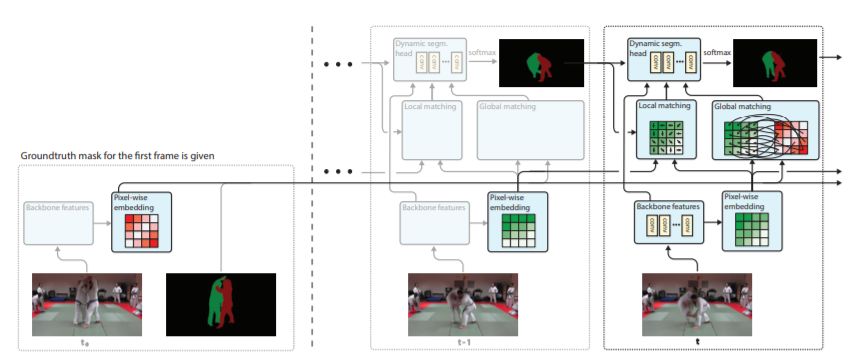
FEELVOS: Fast End-to-End Embedding Learning for Video Object Segmentation
作者:Paul Voigtlaender, Yuning Chai, Florian Schroff, Hartwig Adam, Bastian Leibe, Liang-Chieh Chen
论文链接:
http://www.zhuanzhi.ai/paper/b7016fc2c3a303d2c8f1f8001b4875d
弱监督语义分割
FickleNet: Weakly and Semi-supervised Semantic Image Segmentation using Stochastic Inference
Jungbeom Lee, Eunji Kim, Sungmin Lee, Jangho Lee, Sungroh Yoon
论文链接:
http://www.zhuanzhi.ai/paper/07116fa469bea1b90551d7cf4f8f5306
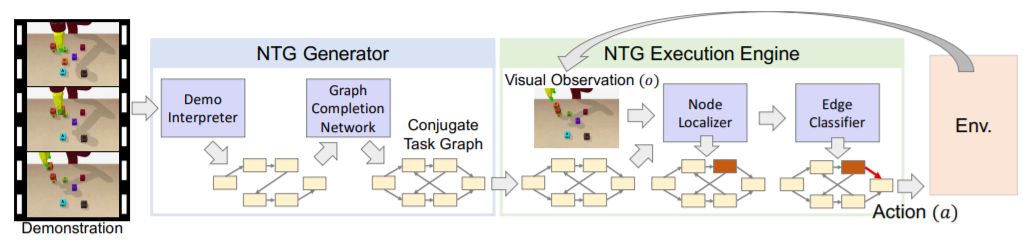
Neural Task Graphs: Generalizing to Unseen Tasks from a Single Video Demonstration
De-An Huang,Suraj Nair,Danfei Xu,Yuke Zhu,Animesh Garg,Li Fei-Fei,Silvio Savarese,Juan Carlos Niebles
地址链接:
http://www.zhuanzhi.ai/paper/22d03c247815526b3b31d7e4b98cbd69
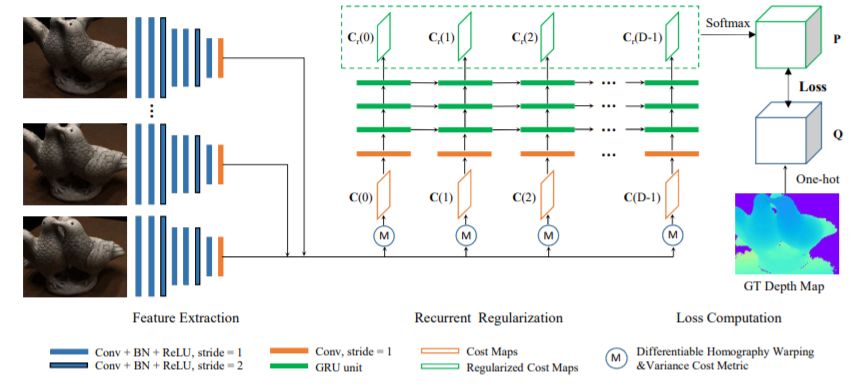
多视几何
Recurrent MVSNet for High-resolution Multi-view Stereo Depth Inference
作者:Yao Yao, Zixin Luo, Shiwei Li, Tianwei Shen, Tian Fang, Long Quan
论文链接:
http://www.zhuanzhi.ai/paper/1b79b35bfd6765ff23f55ea5f0835f9b
代码链接:
https://github.com/YoYo000/MVSNet
3D检测、重建
Stereo R-CNN based 3D Object Detection for Autonomous Driving
作者:Peiliang Li, Xiaozhi Chen, Shaojie Shen
论文链接:
http://www.zhuanzhi.ai/paper/6e707f41e5ed6d33eafc78bdab39034f
Single-Image Piece-wise Planar 3D Reconstruction via Associative Embedding
作者:Zehao Yu, Jia Zheng, Dongze Lian, Zihan Zhou, Shenghua Gao
论文链接:
http://www.zhuanzhi.ai/paper/7362035ddd1d69d241cb45fa3a401d85
代码链接:
https://github.com/svip-lab/PlanarReconstruction
Associatively Segmenting Instances and Semantics in Point Clouds
作者:Xinlong Wang, Shu Liu, Xiaoyong Shen, Chunhua Shen, Jiaya Jia
论文链接:
http://www.zhuanzhi.ai/paper/21645d409b84d40c3fdda548a9dc53c7
代码链接:
https://github.com/WXinlong/ASIS
Deep High-Resolution Representation Learning for Human Pose Estimation
作者:Ke Sun, Bin Xiao, Dong Liu, Jingdong Wang
论文链接:
http://www.zhuanzhi.ai/paper/e0c5f29e3ccc9267bd3bd24876db21e8
代码链接:
https://github.com/leoxiaobin/deep-high-resolution-net.pytorch
【CVPR2019论文便捷获取】
请关注专知公众号(点击上方蓝色专知关注)
后台回复“CVPR2019” 就可以获取CVPR2019论文的下载链接~
END-
专 · 知
专知《深度学习:算法到实战》课程全部完成!490+位同学在学习,现在报名,限时优惠!网易云课堂人工智能畅销榜首位!

欢迎微信扫一扫加入专知人工智能知识星球群,获取最新AI专业干货知识教程视频资料和与专家交流咨询!

请加专知小助手微信(扫一扫如下二维码添加),加入专知人工智能主题群,咨询《深度学习:算法到实战》课程,咨询技术商务合作~

请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

点击“阅读原文”,了解报名专知《深度学习:算法到实战》课程
展开全文



