【论文推荐】最新六篇自动问答相关论文—排序函数、文本摘要评估、信息抽取框架、层次递归编码器、半监督问答
【导读】既前两天推出十三篇自动问答(Question Answering)相关文章,专知内容组今天又推出六篇自动问答相关文章,为大家进行介绍,欢迎查看!
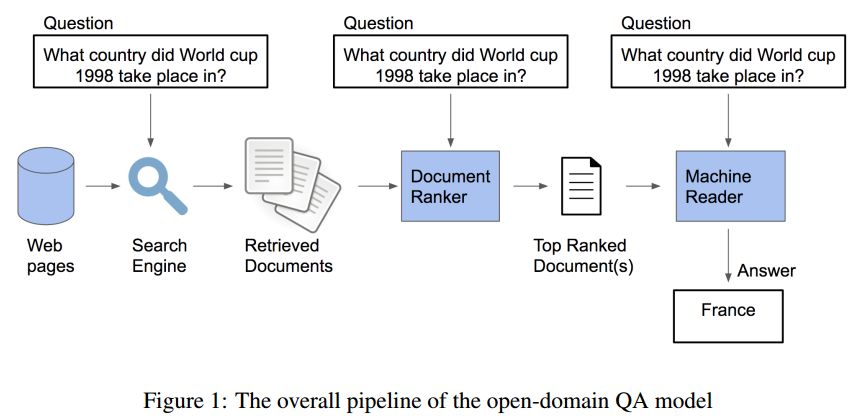
14. Training a Ranking Function for Open-Domain Question Answering(训练排序函数对开放式问题进行回答)
作者:Phu Mon Htut,Samuel R. Bowman,Kyunghyun Cho
机构:New York University
摘要:In recent years, there have been amazing advances in deep learning methods for machine reading. In machine reading, the machine reader has to extract the answer from the given ground truth paragraph. Recently, the state-of-the-art machine reading models achieve human level performance in SQuAD which is a reading comprehension-style question answering (QA) task. The success of machine reading has inspired researchers to combine information retrieval with machine reading to tackle open-domain QA. However, these systems perform poorly compared to reading comprehension-style QA because it is difficult to retrieve the pieces of paragraphs that contain the answer to the question. In this study, we propose two neural network rankers that assign scores to different passages based on their likelihood of containing the answer to a given question. Additionally, we analyze the relative importance of semantic similarity and word level relevance matching in open-domain QA.
期刊:arXiv, 2018年4月12日
网址:
http://www.zhuanzhi.ai/document/bd075132f2b950ddfe3129606b6695cd
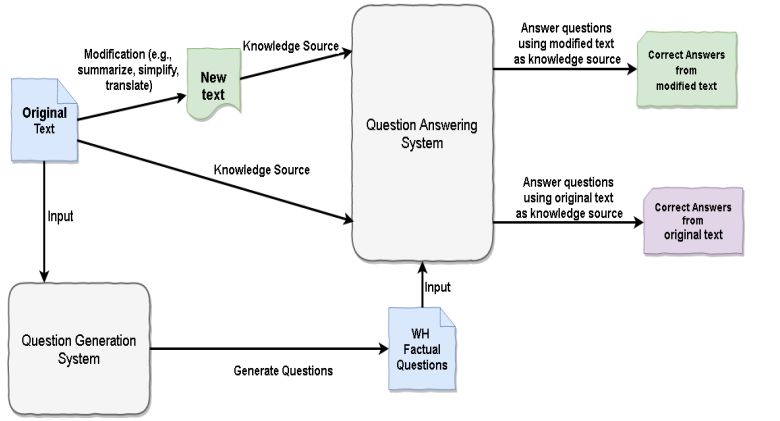
15. A Semantic QA-Based Approach for Text Summarization Evaluation(一种基于QA的文本摘要评估方法)
作者:Ping Chen,Fei Wu,Tong Wang,Wei Ding
机构:University of Massachusetts Boston
摘要:Many Natural Language Processing and Computational Linguistics applications involves the generation of new texts based on some existing texts, such as summarization, text simplification and machine translation. However, there has been a serious problem haunting these applications for decades, that is, how to automatically and accurately assess quality of these applications. In this paper, we will present some preliminary results on one especially useful and challenging problem in NLP system evaluation: how to pinpoint content differences of two text passages (especially for large pas-sages such as articles and books). Our idea is intuitive and very different from existing approaches. We treat one text passage as a small knowledge base, and ask it a large number of questions to exhaustively identify all content points in it. By comparing the correctly answered questions from two text passages, we will be able to compare their content precisely. The experiment using 2007 DUC summarization corpus clearly shows promising results.
期刊:arXiv, 2018年4月11日
网址:
http://www.zhuanzhi.ai/document/bd075132f2b950ddfe3129606b6695cd
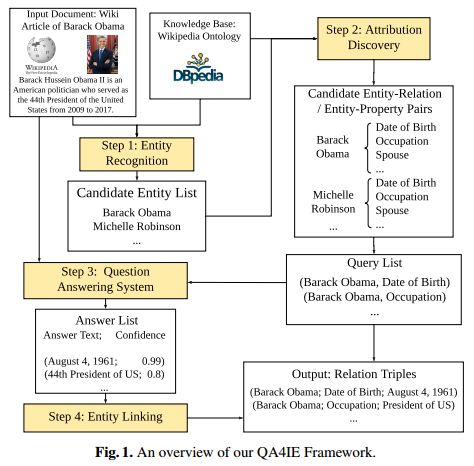
16. QA4IE: A Question Answering based Framework for Information Extraction(QA4IE:一个基于问答的信息抽取框架)
作者:Lin Qiu,Hao Zhou,Yanru Qu,Weinan Zhang,Suoheng Li,Shu Rong,Dongyu Ru,Lihua Qian,Kewei Tu,Yong Yu
机构:Shanghai Jiao Tong University
摘要:Information Extraction (IE) refers to automatically extracting structured relation tuples from unstructured texts. Common IE solutions, including Relation Extraction (RE) and open IE systems, can hardly handle cross-sentence tuples, and are severely restricted by limited relation types as well as informal relation specifications (e.g., free-text based relation tuples). In order to overcome these weaknesses, we propose a novel IE framework named QA4IE, which leverages the flexible question answering (QA) approaches to produce high quality relation triples across sentences. Based on the framework, we develop a large IE benchmark with high quality human evaluation. This benchmark contains 293K documents, 2M golden relation triples, and 636 relation types. We compare our system with some IE baselines on our benchmark and the results show that our system achieves great improvements.
期刊:arXiv, 2018年4月10日
网址:
http://www.zhuanzhi.ai/document/100545a8407b2ec4d748cbf7579edbeb
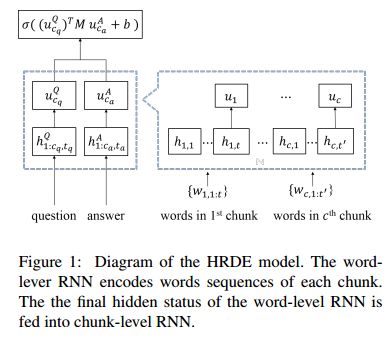
17. Learning to Rank Question-Answer Pairs using Hierarchical Recurrent Encoder with Latent Topic Clustering(学习用层次式递归编码器和潜在的主题聚类对问题回答对进行排序)
作者:Seunghyun Yoon,Joongbo Shin,Kyomin Jung
机构:Seoul National University
摘要:In this paper, we propose a novel end-to-end neural architecture for ranking candidate answers, that adapts a hierarchical recurrent neural network and a latent topic clustering module. With our proposed model, a text is encoded to a vector representation from an word-level to a chunk-level to effectively capture the entire meaning. In particular, by adapting the hierarchical structure, our model shows very small performance degradations in longer text comprehension while other state-of-the-art recurrent neural network models suffer from it. Additionally, the latent topic clustering module extracts semantic information from target samples. This clustering module is useful for any text related tasks by allowing each data sample to find its nearest topic cluster, thus helping the neural network model analyze the entire data. We evaluate our models on the Ubuntu Dialogue Corpus and consumer electronic domain question answering dataset, which is related to Samsung products. The proposed model shows state-of-the-art results for ranking question-answer pairs.
期刊:arXiv, 2018年4月9日
网址:
http://www.zhuanzhi.ai/document/3ed10f562bf0cb5d81c85a7ee339969f
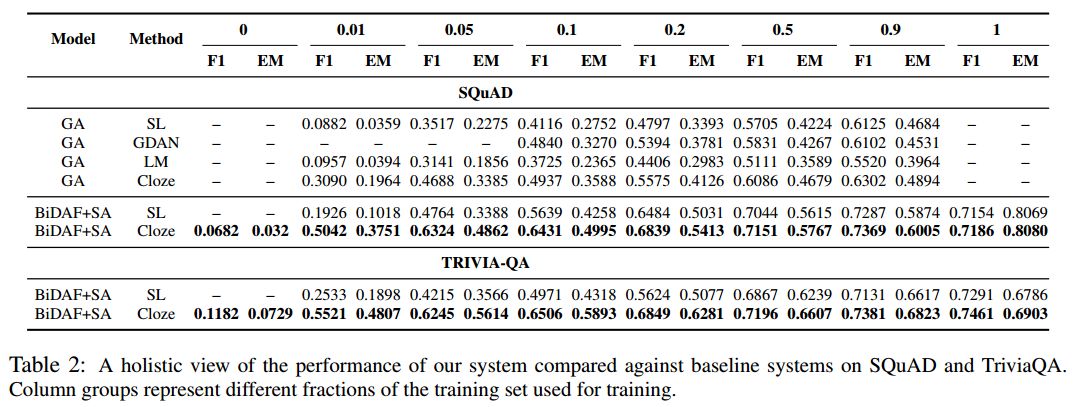
18. Simple and Effective Semi-Supervised Question Answering(简单有效的半监督问答)
作者:Bhuwan Dhingra,Danish Pruthi,Dheeraj Rajagopal
机构:Carnegie Mellon University
摘要:Recent success of deep learning models for the task of extractive Question Answering (QA) is hinged on the availability of large annotated corpora. However, large domain specific annotated corpora are limited and expensive to construct. In this work, we envision a system where the end user specifies a set of base documents and only a few labelled examples. Our system exploits the document structure to create cloze-style questions from these base documents; pre-trains a powerful neural network on the cloze style questions; and further fine-tunes the model on the labeled examples. We evaluate our proposed system across three diverse datasets from different domains, and find it to be highly effective with very little labeled data. We attain more than 50% F1 score on SQuAD and TriviaQA with less than a thousand labelled examples. We are also releasing a set of 3.2M cloze-style questions for practitioners to use while building QA systems.
期刊:arXiv, 2018年4月3日
网址:
http://www.zhuanzhi.ai/document/6036d026edb9f761e3a61d4ac11b61bc
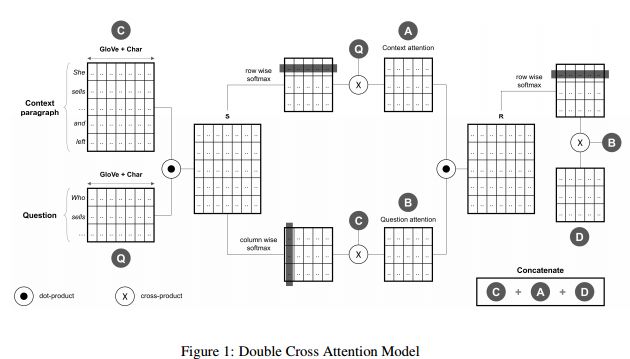
19. Pay More Attention - Neural Architectures for Question-Answering(更多的关注-基于神经结构的问答)
作者:Zia Hasan,Sebastian Fischer
摘要:Machine comprehension is a representative task of natural language understanding. Typically, we are given context paragraph and the objective is to answer a question that depends on the context. Such a problem requires to model the complex interactions between the context paragraph and the question. Lately, attention mechanisms have been found to be quite successful at these tasks and in particular, attention mechanisms with attention flow from both context-to-question and question-to-context have been proven to be quite useful. In this paper, we study two state-of-the-art attention mechanisms called Bi-Directional Attention Flow (BiDAF) and Dynamic Co-Attention Network (DCN) and propose a hybrid scheme combining these two architectures that gives better overall performance. Moreover, we also suggest a new simpler attention mechanism that we call Double Cross Attention (DCA) that provides better results compared to both BiDAF and Co-Attention mechanisms while providing similar performance as the hybrid scheme. The objective of our paper is to focus particularly on the attention layer and to suggest improvements on that. Our experimental evaluations show that both our proposed models achieve superior results on the Stanford Question Answering Dataset (SQuAD) compared to BiDAF and DCN attention mechanisms.
期刊:arXiv, 2018年3月25日
网址:
http://www.zhuanzhi.ai/document/9923a1c986b1e65f0eb7060a305c864d
-END-
专 · 知
人工智能领域主题知识资料查看与加入专知人工智能服务群:
【专知AI服务计划】专知AI知识技术服务会员群加入与人工智能领域26个主题知识资料全集获取

点击上面图片加入会员
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

点击“阅读原文”,使用专知
展开全文



