【论文笔记】自动分类归纳与扩展
【导读】知识图谱 Induction Service(KGIS)是一个端到端的知识归纳系统,它的主要功能是将输入文档自动归类,KGIS允许用户通过利用分布式语义的电子表格(SSS)组件半自动管理和扩展归纳分类。本文中,描述了KGIS的分类法与扩展功能。
论文链接:
https://www.aclweb.org/anthology/D19-3005.pdf
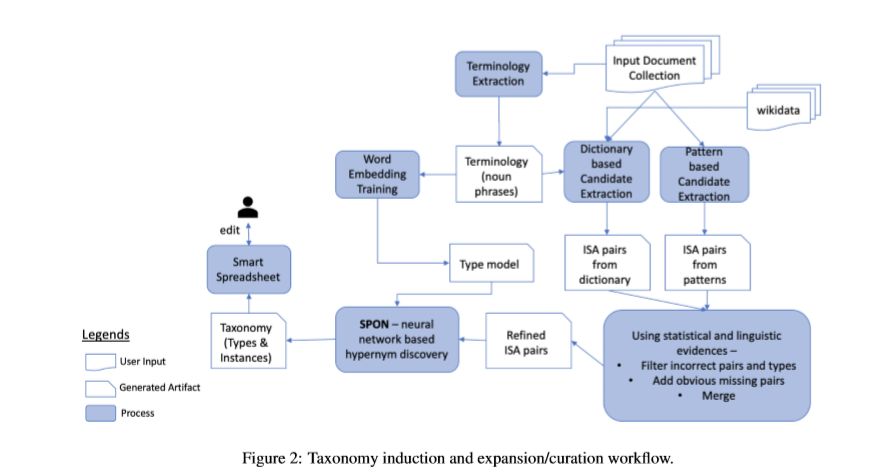
分类法利用不同方法的组合来实现的:一个是基于语言模式,另一种是利用语义网,最后通过神经网络来清洗和扩展分类。KGIS中有一个组件称为智能电子表格(SSS),该表格由可编辑的交互式网格组成,第一行为类型,对应的列为其术语。用户可以通过删除错误的类型或术语以及扩展特定类型的术语来完善自动归类。
数据集合的大小使人工分析或注释变得不切实际,因此,用户将数据提取到KGIS中,并完成KG归纳工作。根据数据的大小,系统会在几分钟或几个小时内完成以下工作:带注释的语料库,术语、类型嵌入模型以及进一步完善的分类器。

输入过程与注释
系统的输入是文本集合。语料生成的过程是将不同格式(txt, json, pdf, word,etc)的输入转换成一个标准的格式。这个主要是通过IBM云平台的Document Conversion Service API接口。
注释术语主要就是名词词性的短语,主要是经过IBM WatsonR NLU API来实现,然后,将频率大于阈值的术语组合在一起形成术语集。
type模型
此部分是为了获取type的相似度,因此,训练一个word2vec模型,窗口为2。
分类归纳
分类归纳模块采用了上述的注释语料,并且定义了术语对之间的is-a关系,KGIS使用三种不同的方法来归纳非分类层,每种方法的结果都以SSS呈现。
基于模式的方法
为了提取is-a对,系统使用24种lexico-syntactic模式,提取is-a对后,将进行预处理。首先,将没对is-a视为边,并将相应的主语宾语视为节点,将is-a对表示为图形,每个边缘的权重是通过模式匹配提取的术语对的频率数。
系统将自行排除有闭环的is-a关系,例如提取的is-a列表中存在(x,y),(y,z),(z,x),那么将其全部丢弃。KGIS还会丢弃低于用户指定的频率阈值的边。KGIS还可以识别潜在专有名词,满足以下三个条件可视x1为专有名词:(1)不是x2的子字符串,(2)x2是x1的一种类型,(3)x2属于专有名词(人名,地方,组织)。如果识别出为专有名词,则KGIS会丢弃该术语与其他术语相关联的边。
预处理的下一步就是扩展图中的术语对,即使用尚未提取的成对嵌套术语类型和超级术语对。嵌套术语如下:“银行”是“中国银行”,“建设银行”的嵌套术语。KGIS使用剩余的is-a对列表构建嵌套术语搜索索引。
基于语义网的方法
wikidata是使用RDF和OWL语义表示的一个全面的知识源,它包含大量包含关系的分类信息。在KGIS中,基于语义网的候选生成方法包括:将识别的术语链接到wikidata实体并发现is-a关系。通过将术语与wikidata实体的标签与别名进行相似度匹配来完成链接。
提取is-a关系之后,接下来就是进行过滤,来消除错误的关系。这部分是通过type相似性与成对实例的相似性与阈值进行比较来完成的。(具体通过type模型来实现)
基于神经网络的方法
is-a关系是自上而下和传递的,因此利用顺序理论,开发出STRICT PARTIAL ORDER NETWORKS (SPON),该架构由非负激活函数和残差网络组成。
SPON分为三个阶段,第一阶段是对提取的is-a关系建模。旨在为每个is-a对提供分数;第二阶段,对所有提取的术语进行排序;最后根据用户的特定标准对前边步骤中生成的is-a关系进行排名,并呈现给用户。
第一阶段:此步骤是为了给现有的is-a关系进行评分。此阶段假设一个正确的is-a关系更可能被正确推断,相反,当评估与SPON模型训练出来的相反则被认为是错误的关系。依据假设,现存的is-a关系分别从基于模式与基于语义网这两种方法中获取的。这个关系被分为K部分,然后对这K部分is-a关系独立进行SPON过程,每个过程训练K-2次,k-1次进行评估,最后生成第k次分数。将每个fold的结果连接在一起,以生成第一阶段的输出O1。
第二阶段:此阶段的目的是为了对获取的类型术语进行排序。按照第一阶段的方法,将现有的is-a关系分为k部分,其他与第一阶段相同。
所有的SPON流程结束,我们将获得每个术语的K个不同的类型排序列表,然后对这些排名取平均值,以获得每个术语类型的单个排名列表,此输出作为第二部分输出O2。
第三阶段:将先前阶段的结果O1与O2合并,获得每个类型的排序实例的扩展列表。然后,此阶段分为两步骤进行,第一步是删除分数小于阈值的给定类型的所有实例;第二步,按类型的前m个实例的平均得分对类型进行排。参数 θ与m由用户输入,最后即为KGIS的SPON组件的最终输出结果。
SSS中的单元格对应KG中的节点,此外SSS中的第一行为类型,每列表示相对应类型的术语。在功能上,SSS可以完成术语名称自行导入;类型,以帮助用户为一组实例分配一种类型,并根据现有的术语关联先关的术语。
每次创建新的分类法,就会另存为一个新的SSS,以便用户对其进行修改。首先,用户给定的一组较少术语列表,SSS可以使用以下三个选项生成同一类型的其他术语。
种子填充:将用户输入的术语的嵌入进行平均计算得到一个质心向量,然后对所有术语进行最近邻算法,以获取同一类型的其他术语
KG类型填充:仅当用户从语义web中找到匹配类型时,此选项才可以用。它使用户可以在目标KG中获取此类型的实例,并且该实例也出现在语料库中。
远距离监督,KG填充:此选项也需要选定的KG类型,并且是前两种技术的组合。从KG中检索更多给定类型的实例,从而获得更多的与给定实例含有相同语义的术语。
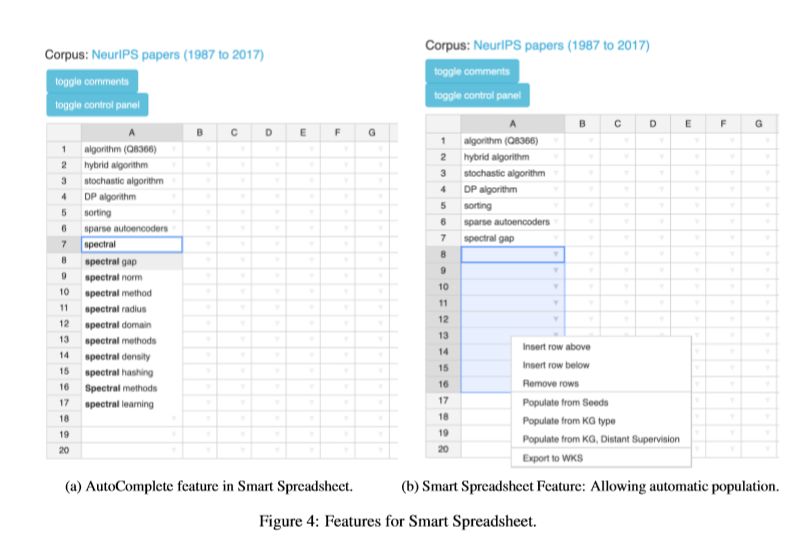
图4b显示了KGIS系统的一张截图,在此示例中,用户输入一些算法名称作为实例,改组的类型名为“algorithm”,选择一些单元格并单击右键以填充单元格。另外,SSS提供了自动完成功能。例如,在图4a中,只要用户输入频谱术语,系统就会根据输入语料库自动完成填充任务。

系统对英文数据集中的8个术语进行测试,SPON预测的结果加粗,下划线表示的是人为认为应该正确预测的,但SPON却丢失了的预测结果。我们使用的KGIS是一个端到端的归纳系统。通过使用智能电子表来达到自动分类的效果,并且该表格允许用户根据自己的意愿进行更改。KGIS框架减少了对人工注释的需求,但又可以允许人工进行交互,从而确保用户可以始终拥有发言权。
更多关于“知识图谱”的论文知识资料,请登录专知网站www.zhuanzhi.ai查看,或者点击“阅读原文”查看:
https://www.zhuanzhi.ai/topic/2001005380553956/awesome



展开全文



