如何构建多模态BERT? 这份UNC76页《LXMERT: 从Transformer学习跨模态编码表示》PPT告诉您,附论文代码
【导读】BERT自问世以来,几乎刷新了各种NLP的任务榜,基于BERT的变种也层出不穷。19年来,很多研究人员都尝试融合视觉音频等模态信息进行构建预训练语言模型。本文介绍了EMNLP2019来自UNC-北卡罗来纳大学教堂山分校的Hao Tan的工作。构建LXMERT(从Transformers中学习跨模态编码器表示)框架来学习这些视觉和语言的语义联系。作者这份76页PPT详细介绍了语言和视觉任务的概况以及如何构建多模态BERT。


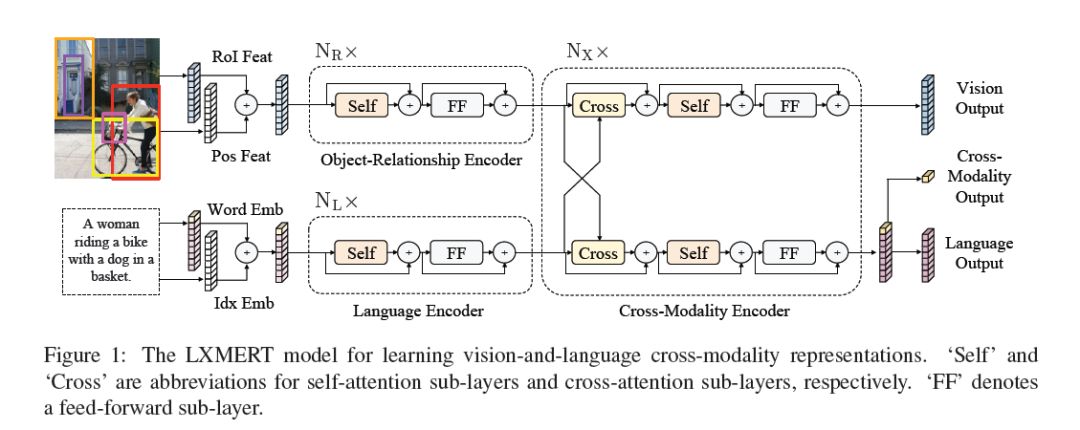
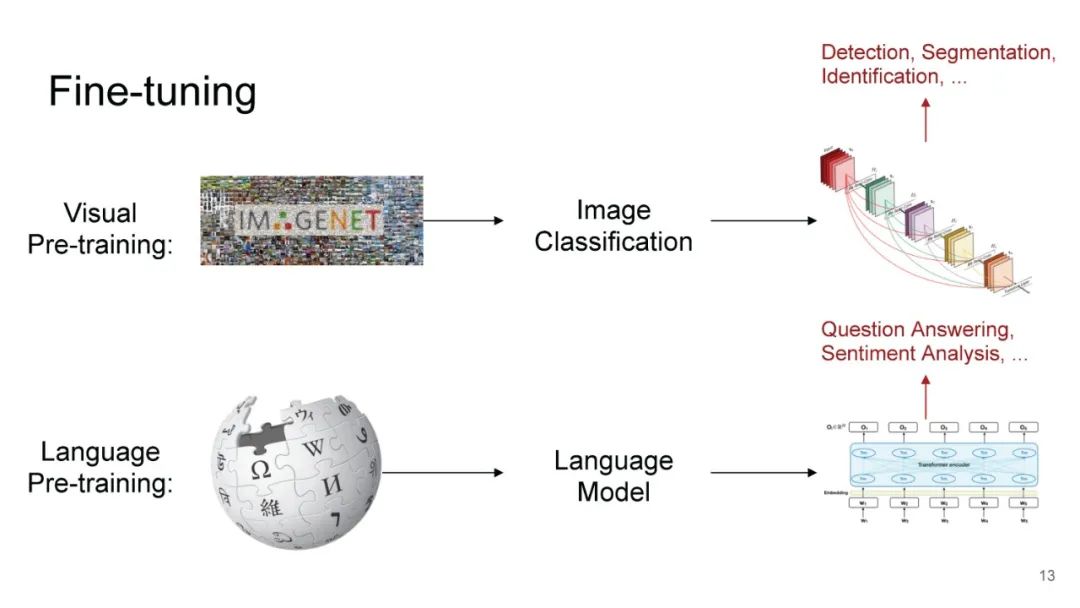
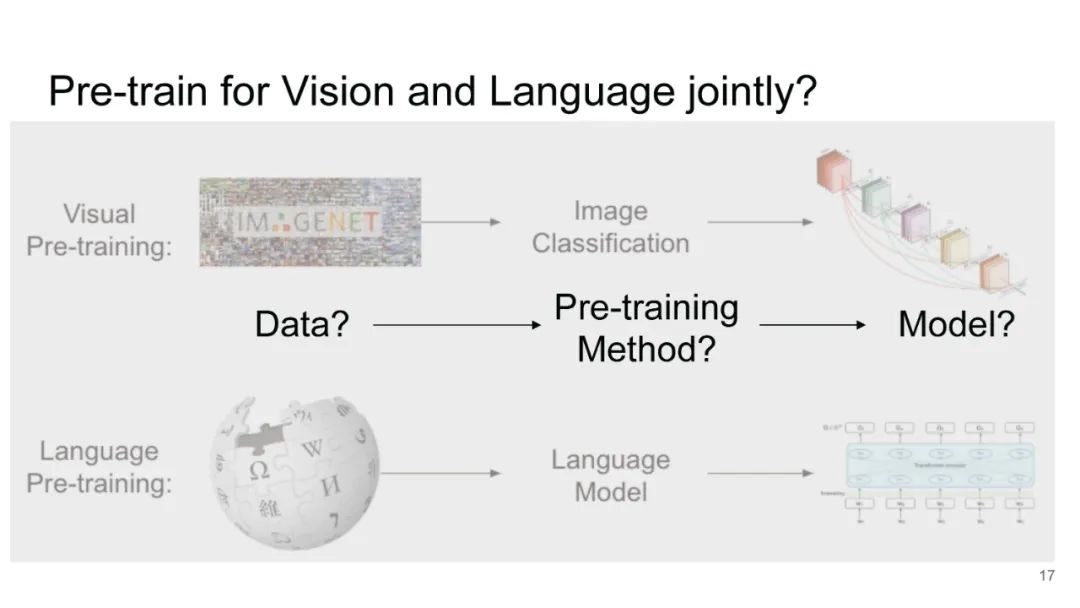
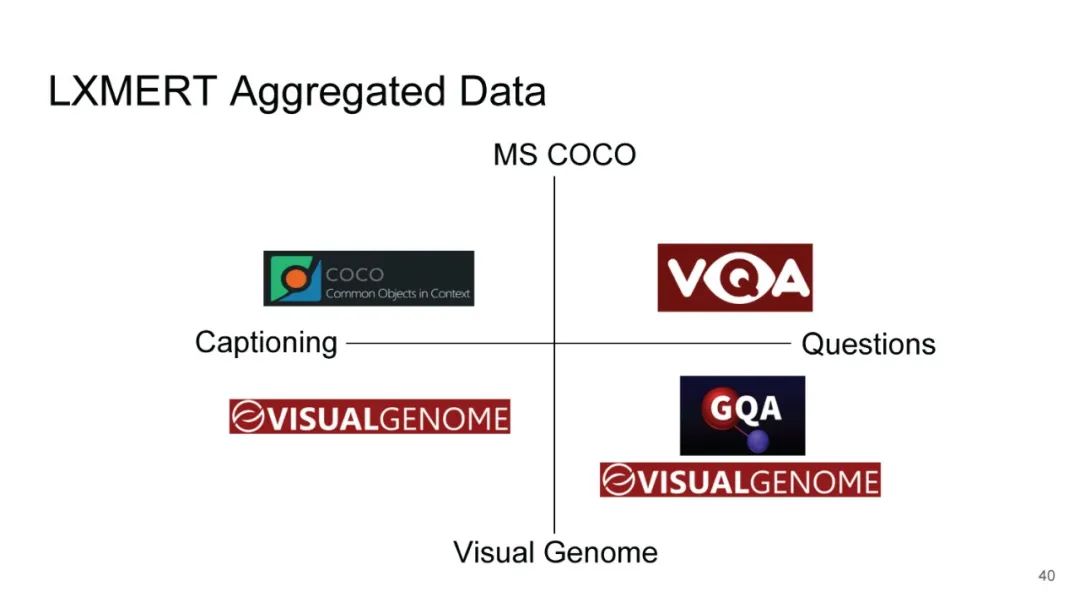
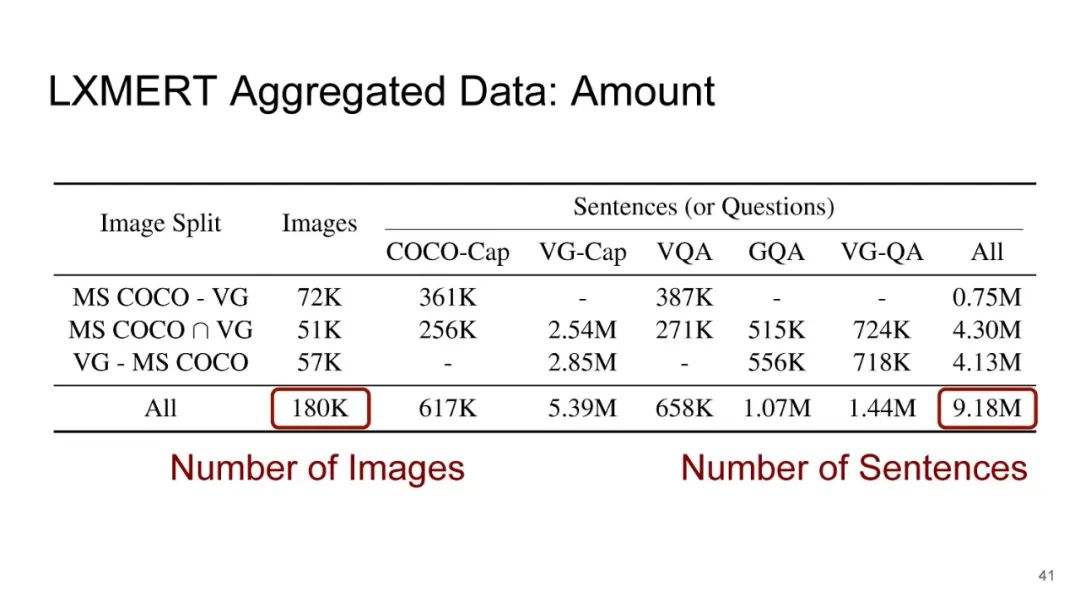
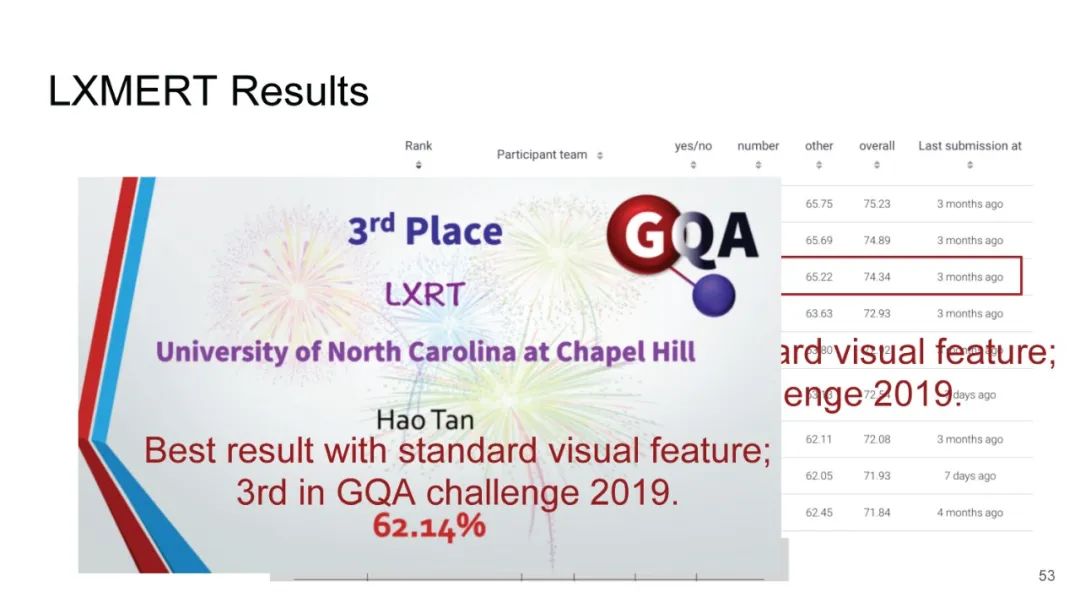
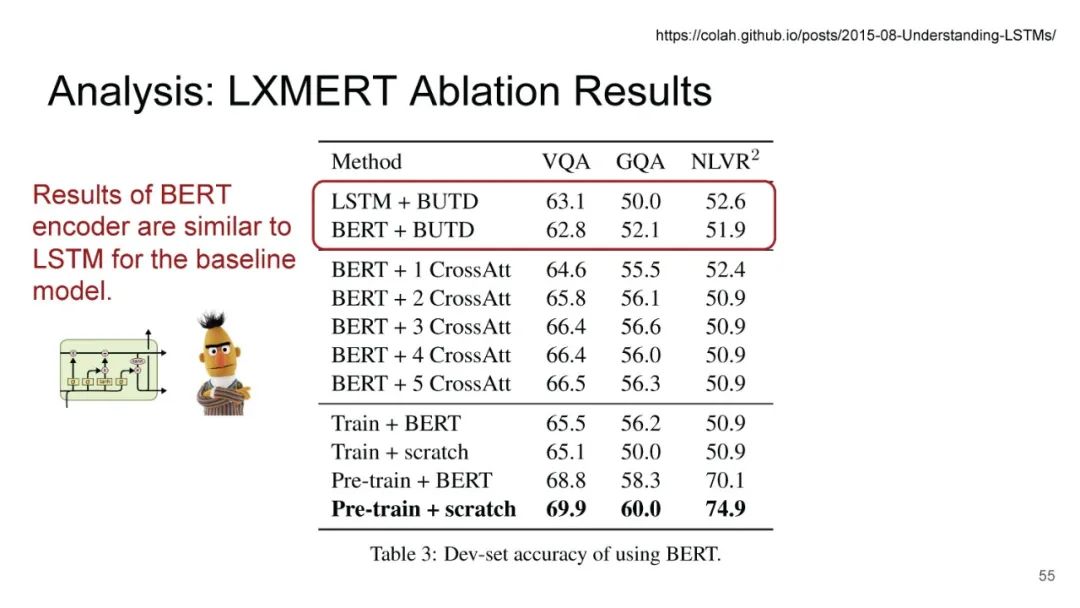
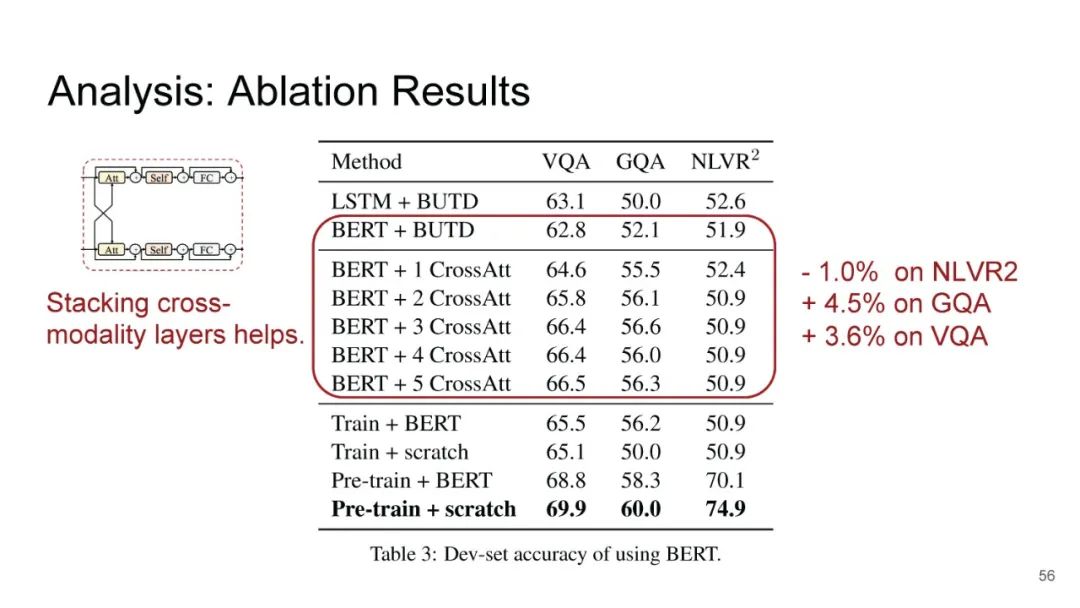
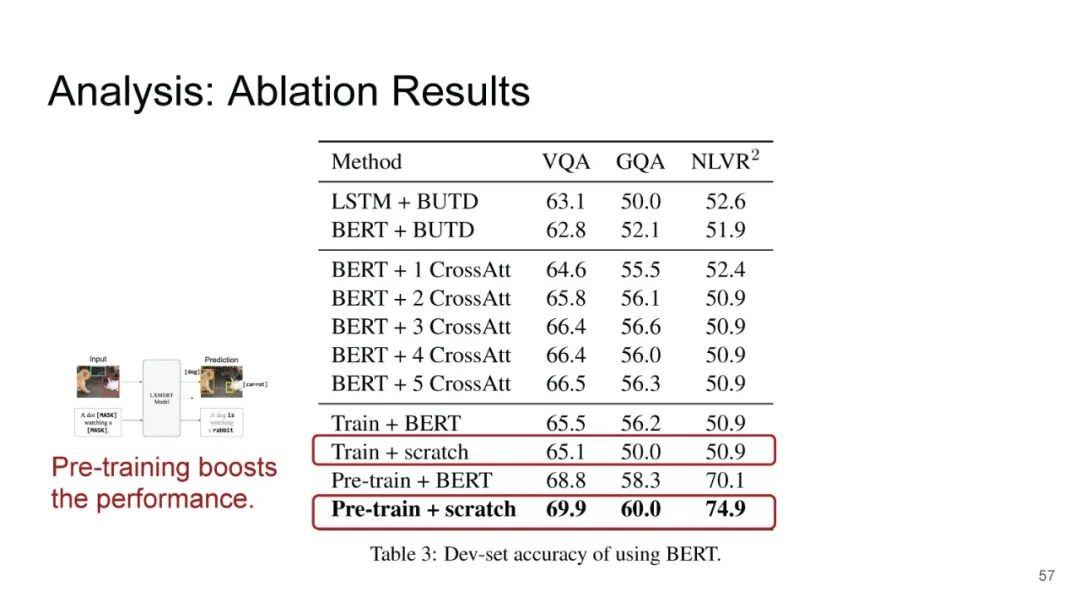
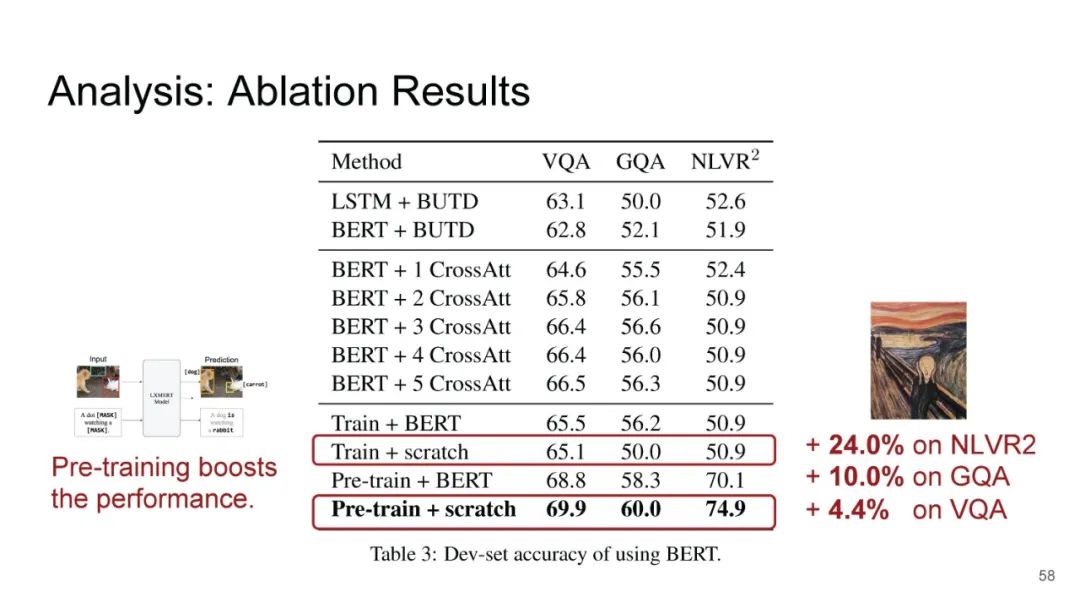
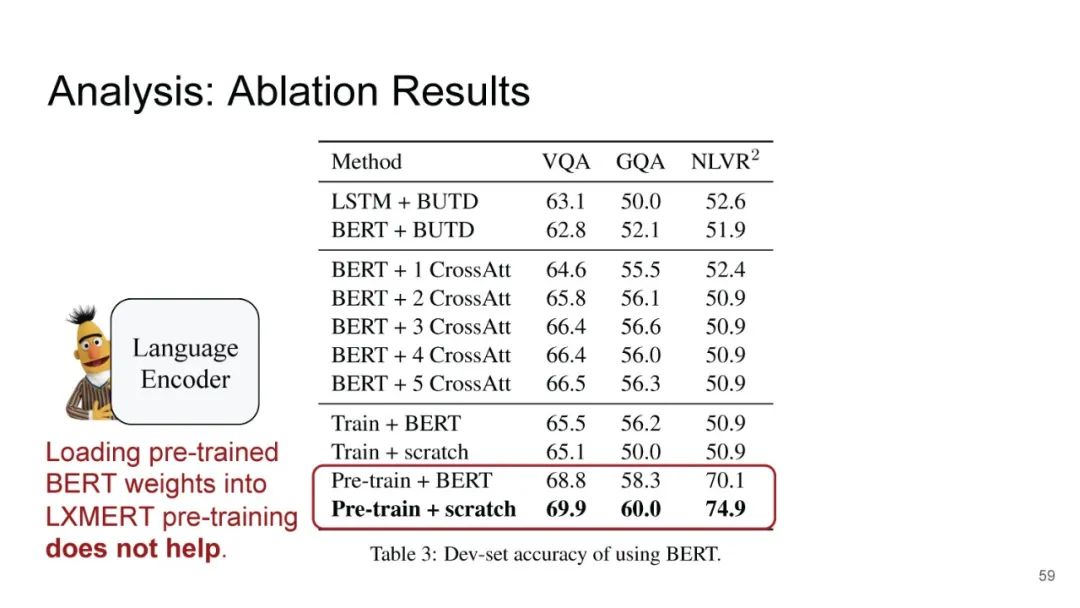
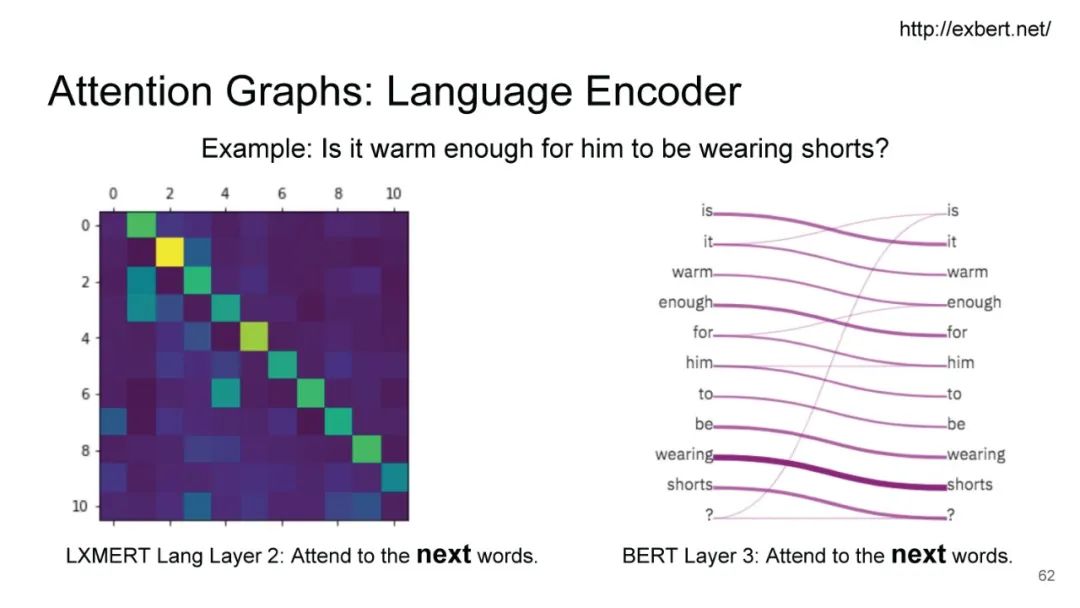
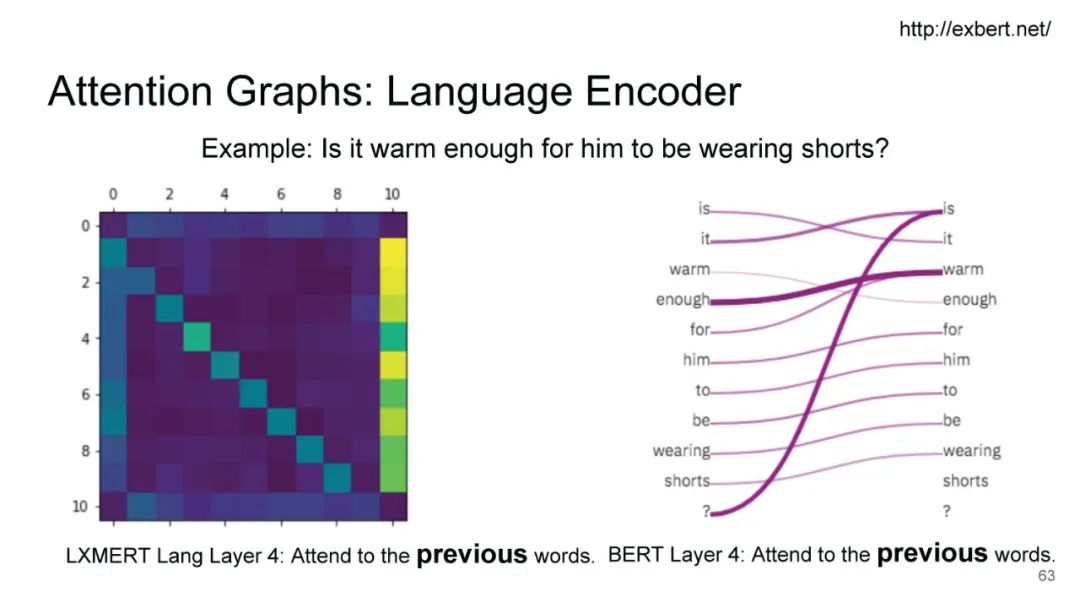
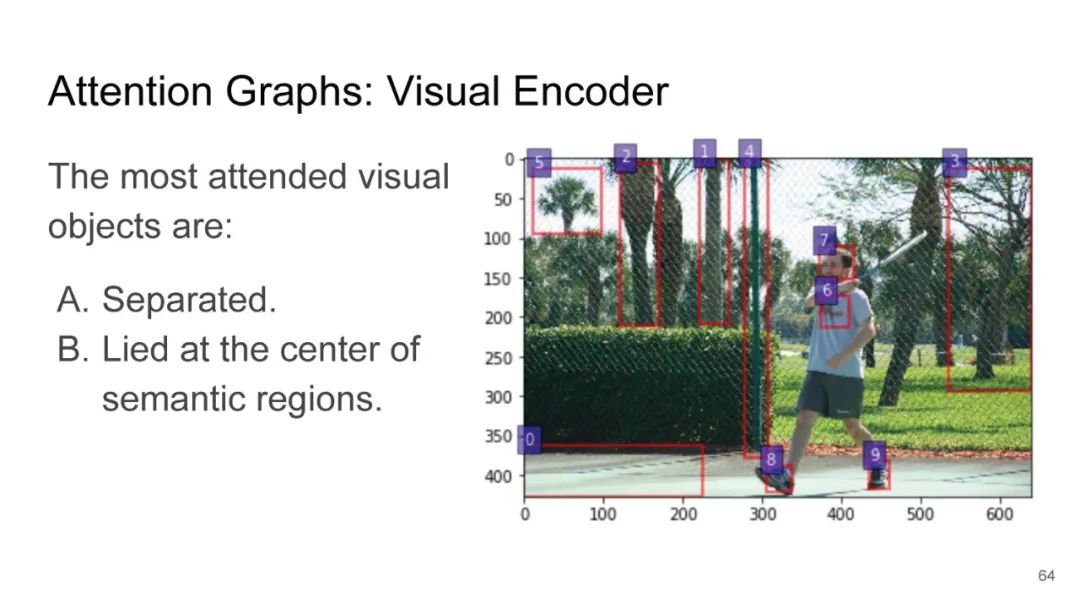
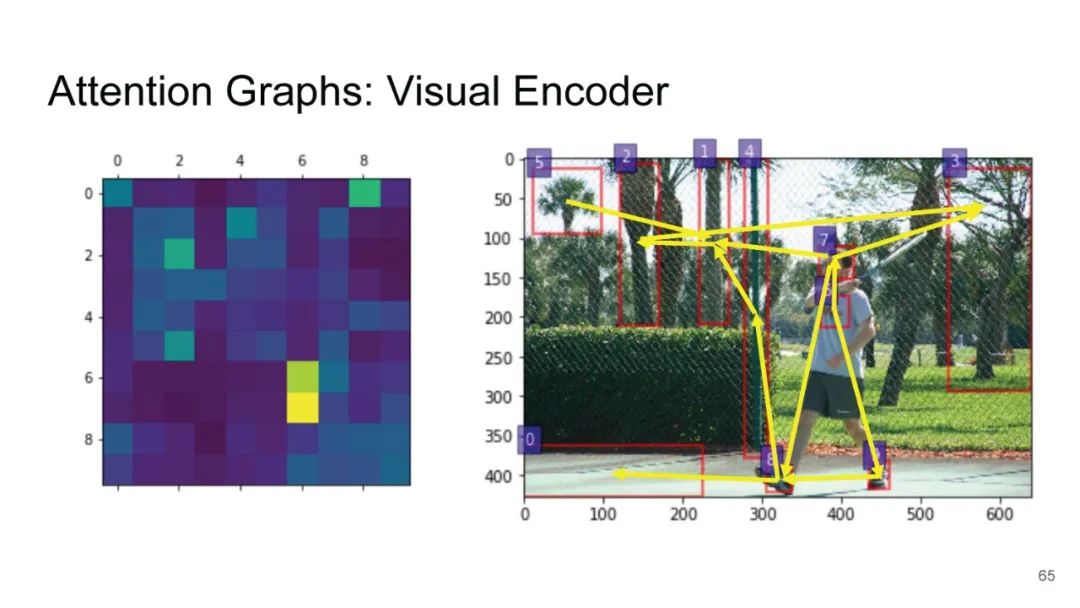
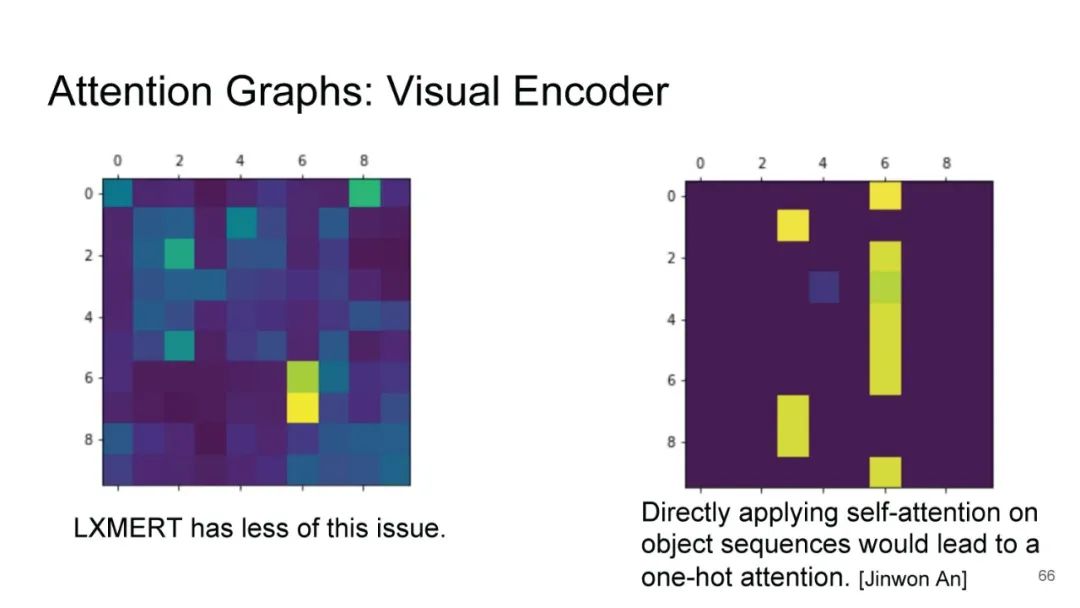
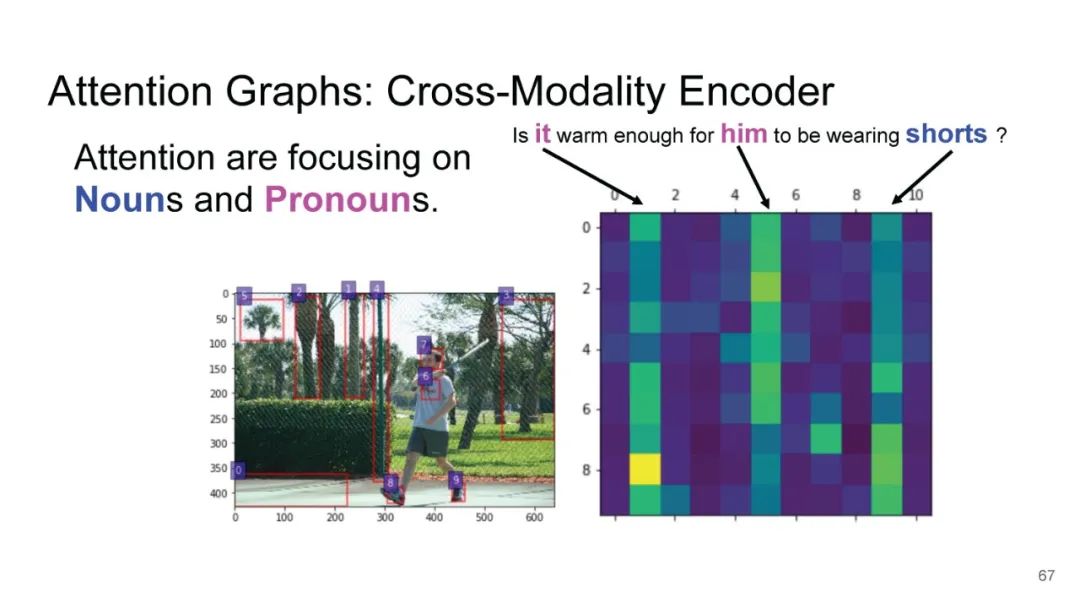
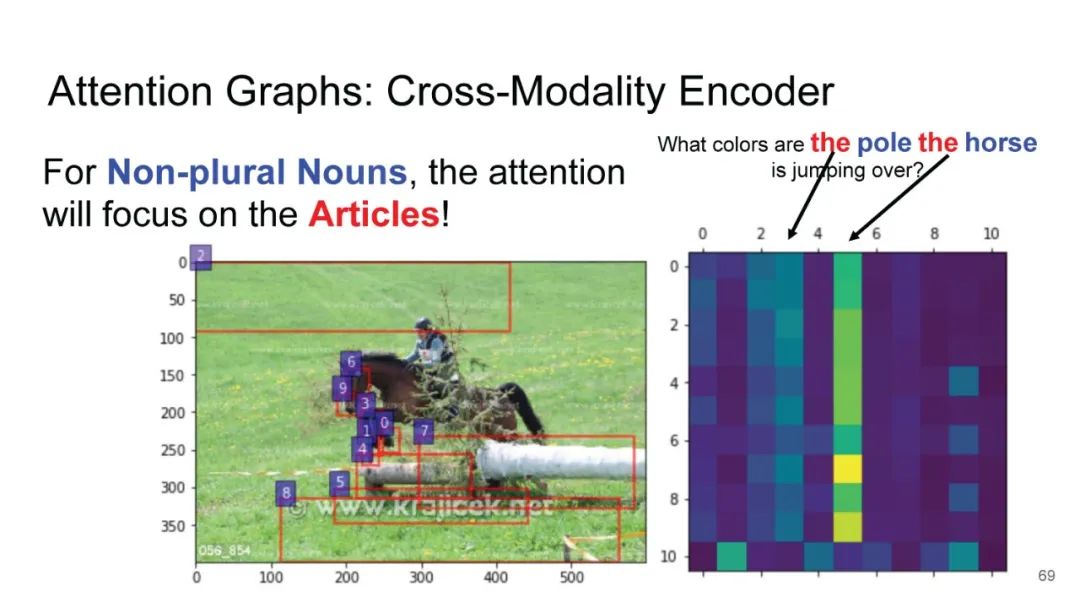
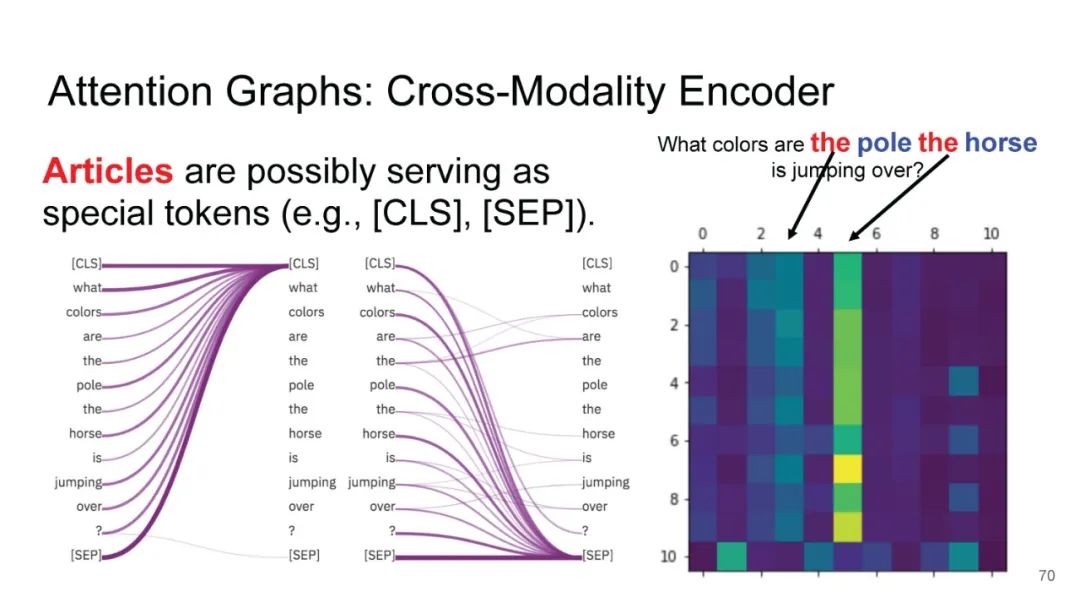
LXMERT同样是两路输入,在视觉侧关注单图,和上文很多方案类似,图像经过目标检测模型得到区域块的特征序列,并经过Transformer进一步编码;文本侧通过BERT结构得到文本的特征序列,最后两者做交叉的Transformer做Attention,进行多任务的预训练。不同于其他工作,LXMERT的预训练任务可以说是巨多,包括masked图像特征的预测、图像label的预测(猫、狗等)、VQA、图文是否匹配以及masked语言模型。
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“LXMERT” 就可以获取《UNC76页《LXMERT: 从Transformer学习跨模态编码表示》PPT》专知下载链接












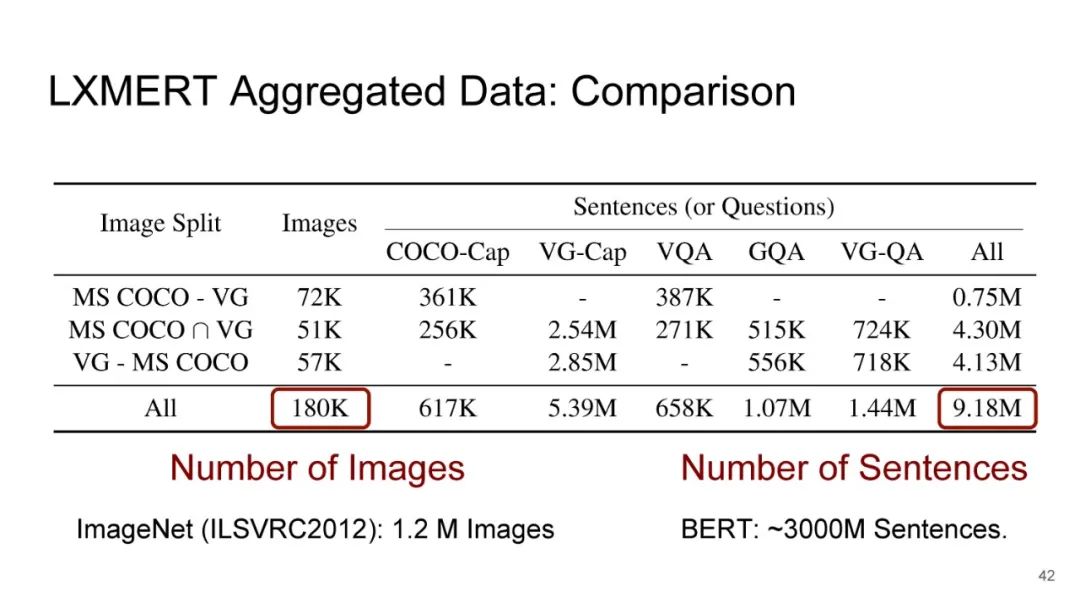




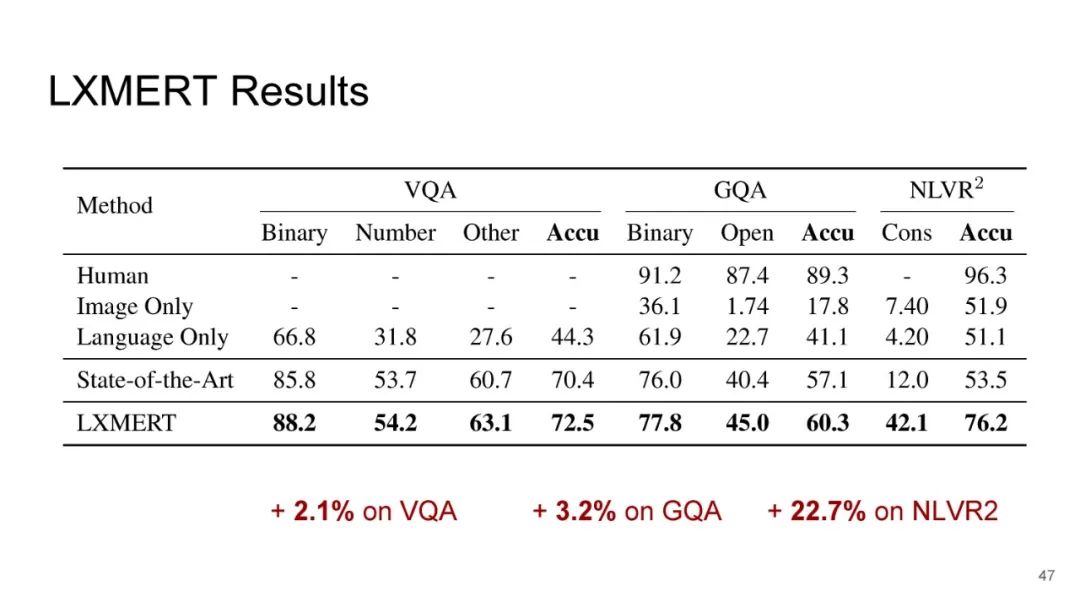
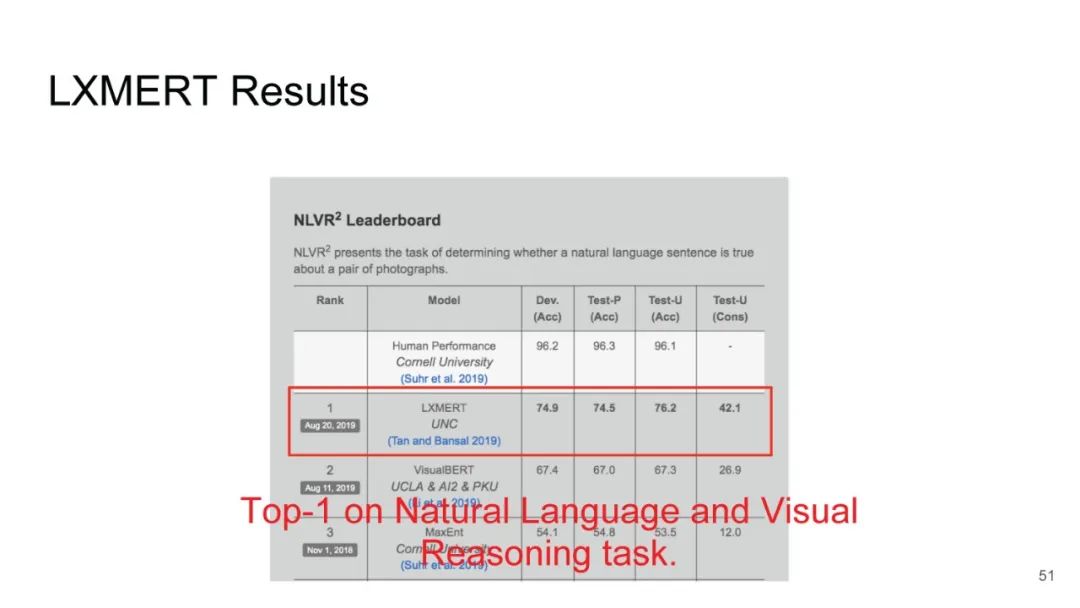
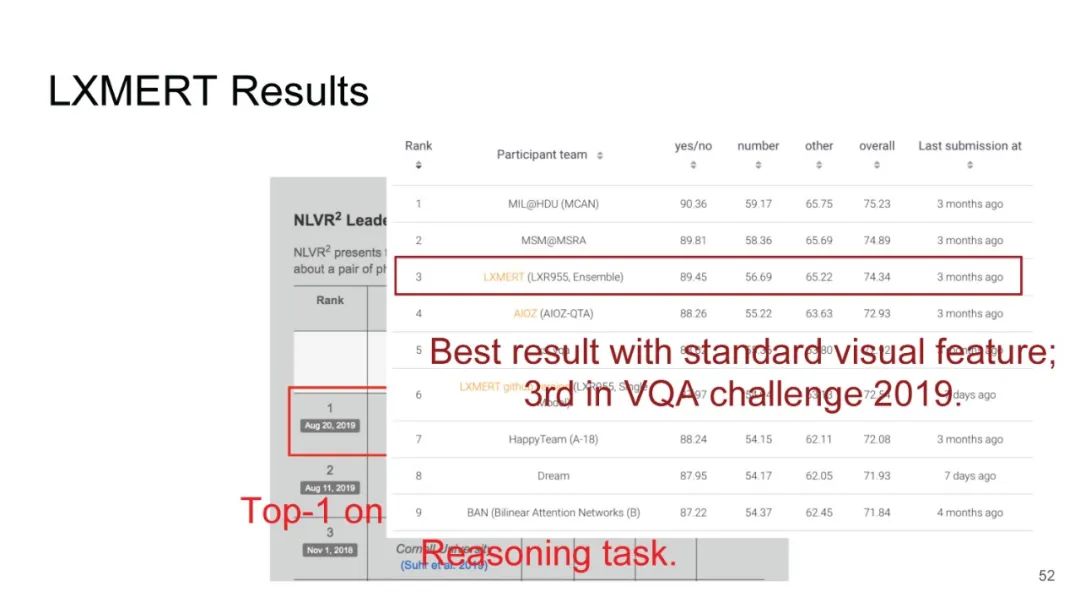






专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“LXMERT” 就可以获取《UNC76页《LXMERT: 从Transformer学习跨模态编码表示》PPT》专知下载链接



展开全文



