【论文推荐】最新七篇自注意力机制(Self-attention)相关论文—结构化自注意力、相对位置、混合、句子表达、文本向量
【导读】专知内容组整理了最近七篇自注意力机制(Self-attention)相关文章,为大家进行介绍,欢迎查看!
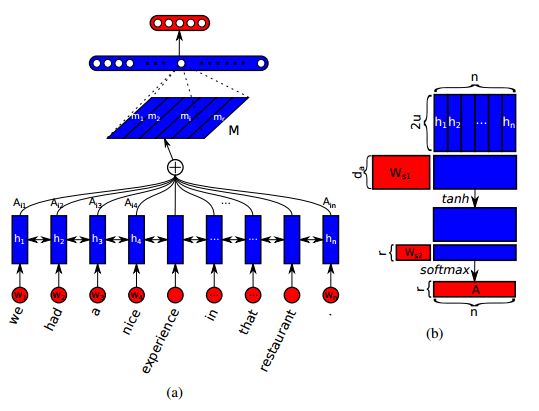
1. A Structured Self-attentive Sentence Embedding(一个结构化的自注意力的句子嵌入)
作者:Zhouhan Lin,Minwei Feng,Cicero Nogueira dos Santos,Mo Yu,Bing Xiang,Bowen Zhou,Yoshua Bengio
机构:Montreal Institute for Learning Algorithms,Universite de Montr ´ eal
摘要:This paper proposes a new model for extracting an interpretable sentence embedding by introducing self-attention. Instead of using a vector, we use a 2-D matrix to represent the embedding, with each row of the matrix attending on a different part of the sentence. We also propose a self-attention mechanism and a special regularization term for the model. As a side effect, the embedding comes with an easy way of visualizing what specific parts of the sentence are encoded into the embedding. We evaluate our model on 3 different tasks: author profiling, sentiment classification, and textual entailment. Results show that our model yields a significant performance gain compared to other sentence embedding methods in all of the 3 tasks.
期刊:arXiv, 2018年3月9日
网址:
http://www.zhuanzhi.ai/document/c5ceb3ae25d3a3be4848bd0182d210c4
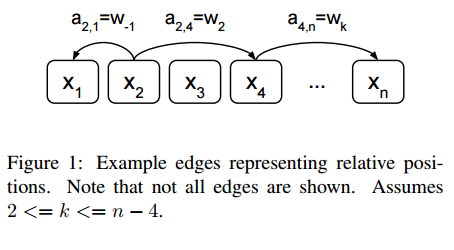
2. Self-Attention with Relative Position Representations(基于相对位置表示的子注意力模型)
作者:Peter Shaw,Jakob Uszkoreit,Ashish Vaswani
机构:Google Brain
摘要:Relying entirely on an attention mechanism, the Transformer introduced by Vaswani et al. (2017) achieves state-of-the-art results for machine translation. In contrast to recurrent and convolutional neural networks, it does not explicitly model relative or absolute position information in its structure. Instead, it requires adding representations of absolute positions to its inputs. In this work we present an alternative approach, extending the self-attention mechanism to efficiently consider representations of the relative positions, or distances between sequence elements. On the WMT 2014 English-to-German and English-to-French translation tasks, this approach yields improvements of 1.3 BLEU and 0.3 BLEU over absolute position representations, respectively. Notably, we observe that combining relative and absolute position representations yields no further improvement in translation quality. We describe an efficient implementation of our method and cast it as an instance of relation-aware self-attention mechanisms that can generalize to arbitrary graph-labeled inputs.
期刊:arXiv, 2018年3月6日
网址:
http://www.zhuanzhi.ai/document/b5f7daac1262e2172682b9146b2dc6d3
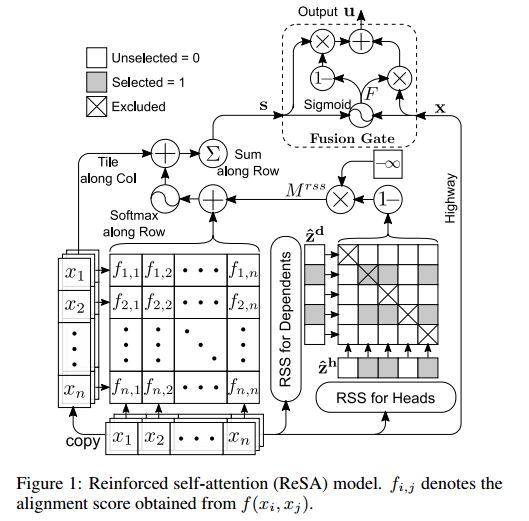
3. Reinforced Self-Attention Network: a Hybrid of Hard and Soft Attention for Sequence Modeling(增强的自注意力网络:一种对序列建模的硬和软注意力的混合)
作者:Tao Shen,Tianyi Zhou,Guodong Long,Jing Jiang,Sen Wang,Chengqi Zhang
机构:University of Technology Sydney,University of Washington,Griffith University
摘要:Many natural language processing tasks solely rely on sparse dependencies between a few tokens in a sentence. Soft attention mechanisms show promising performance in modeling local/global dependencies by soft probabilities between every two tokens, but they are not effective and efficient when applied to long sentences. By contrast, hard attention mechanisms directly select a subset of tokens but are difficult and inefficient to train due to their combinatorial nature. In this paper, we integrate both soft and hard attention into one context fusion model, "reinforced self-attention (ReSA)", for the mutual benefit of each other. In ReSA, a hard attention trims a sequence for a soft self-attention to process, while the soft attention feeds reward signals back to facilitate the training of the hard one. For this purpose, we develop a novel hard attention called "reinforced sequence sampling (RSS)", selecting tokens in parallel and trained via policy gradient. Using two RSS modules, ReSA efficiently extracts the sparse dependencies between each pair of selected tokens. We finally propose an RNN/CNN-free sentence-encoding model, "reinforced self-attention network (ReSAN)", solely based on ReSA. It achieves state-of-the-art performance on both Stanford Natural Language Inference (SNLI) and Sentences Involving Compositional Knowledge (SICK) datasets.
期刊:arXiv, 2018年1月31日
网址:
http://www.zhuanzhi.ai/document/e51e2566ca96c1a0e754df04a648eeb0
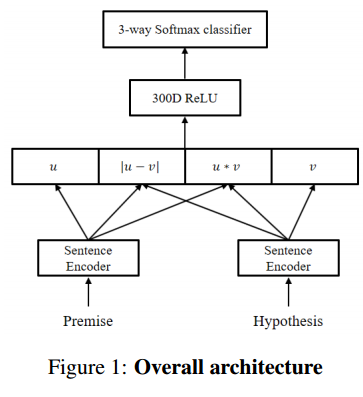
4. Distance-based Self-Attention Network for Natural Language Inference(基于距离的自注意力网络的自然语言推理)
作者:Jinbae Im,Sungzoon Cho
机构:Seoul National University
摘要:Attention mechanism has been used as an ancillary means to help RNN or CNN. However, the Transformer (Vaswani et al., 2017) recently recorded the state-of-the-art performance in machine translation with a dramatic reduction in training time by solely using attention. Motivated by the Transformer, Directional Self Attention Network (Shen et al., 2017), a fully attention-based sentence encoder, was proposed. It showed good performance with various data by using forward and backward directional information in a sentence. But in their study, not considered at all was the distance between words, an important feature when learning the local dependency to help understand the context of input text. We propose Distance-based Self-Attention Network, which considers the word distance by using a simple distance mask in order to model the local dependency without losing the ability of modeling global dependency which attention has inherent. Our model shows good performance with NLI data, and it records the new state-of-the-art result with SNLI data. Additionally, we show that our model has a strength in long sentences or documents.
期刊:arXiv, 2017年12月6日
网址:
http://www.zhuanzhi.ai/document/78436b0cb7b3f288ed5b0a4dbe516896
5. Improving Visually Grounded Sentence Representations with Self-Attention(以自注意力的方式提高基于视觉的句子表达)
作者:Kang Min Yoo,Youhyun Shin,Sang-goo Lee
机构:Seoul National University
摘要:Sentence representation models trained only on language could potentially suffer from the grounding problem. Recent work has shown promising results in improving the qualities of sentence representations by jointly training them with associated image features. However, the grounding capability is limited due to distant connection between input sentences and image features by the design of the architecture. In order to further close the gap, we propose applying self-attention mechanism to the sentence encoder to deepen the grounding effect. Our results on transfer tasks show that self-attentive encoders are better for visual grounding, as they exploit specific words with strong visual associations.

期刊:arXiv, 2017年12月2日
网址:
http://www.zhuanzhi.ai/document/e6830a90f7825e921218c1344c74224d
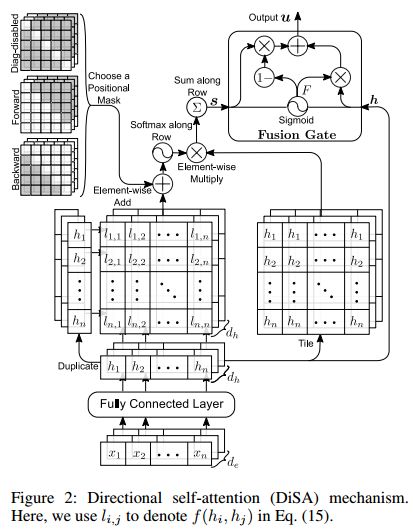
6. DiSAN: Directional Self-Attention Network for RNN/CNN-Free Language Understanding(DiSAN:RNN/CNN-free语言理解的方向的双向自注意网络)
作者:Tao Shen,Tianyi Zhou,Guodong Long,Jing Jiang,Shirui Pan,Chengqi Zhang
机构:University of Technology Sydney,University of Washington
摘要:Recurrent neural nets (RNN) and convolutional neural nets (CNN) are widely used on NLP tasks to capture the long-term and local dependencies, respectively. Attention mechanisms have recently attracted enormous interest due to their highly parallelizable computation, significantly less training time, and flexibility in modeling dependencies. We propose a novel attention mechanism in which the attention between elements from input sequence(s) is directional and multi-dimensional (i.e., feature-wise). A light-weight neural net, "Directional Self-Attention Network (DiSAN)", is then proposed to learn sentence embedding, based solely on the proposed attention without any RNN/CNN structure. DiSAN is only composed of a directional self-attention with temporal order encoded, followed by a multi-dimensional attention that compresses the sequence into a vector representation. Despite its simple form, DiSAN outperforms complicated RNN models on both prediction quality and time efficiency. It achieves the best test accuracy among all sentence encoding methods and improves the most recent best result by 1.02% on the Stanford Natural Language Inference (SNLI) dataset, and shows state-of-the-art test accuracy on the Stanford Sentiment Treebank (SST), Multi-Genre natural language inference (MultiNLI), Sentences Involving Compositional Knowledge (SICK), Customer Review, MPQA, TREC question-type classification and Subjectivity (SUBJ) datasets.
期刊:arXiv, 2017年11月21日
网址:
http://www.zhuanzhi.ai/document/ffba9961c35cae407f5390dca0a3c627
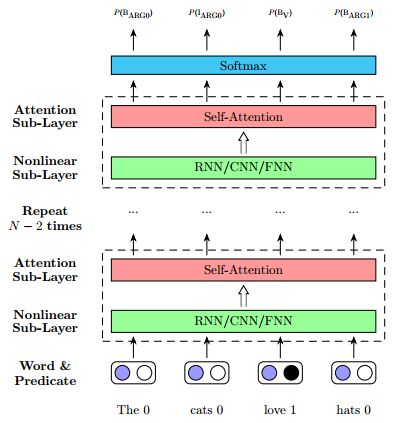
7. Deep Semantic Role Labeling with Self-Attention(基于子注意力机制的深度语义角色标注)
作者:Zhixing Tan,Mingxuan Wang,Jun Xie,Yidong Chen,Xiaodong Shi
机构:Xiamen University,Tencent Technology Co
摘要:Semantic Role Labeling (SRL) is believed to be a crucial step towards natural language understanding and has been widely studied. Recent years, end-to-end SRL with recurrent neural networks (RNN) has gained increasing attention. However, it remains a major challenge for RNNs to handle structural information and long range dependencies. In this paper, we present a simple and effective architecture for SRL which aims to address these problems. Our model is based on self-attention which can directly capture the relationships between two tokens regardless of their distance. Our single model achieves F$_1=83.4$ on the CoNLL-2005 shared task dataset and F$_1=82.7$ on the CoNLL-2012 shared task dataset, which outperforms the previous state-of-the-art results by $1.8$ and $1.0$ F$_1$ score respectively. Besides, our model is computationally efficient, and the parsing speed is 50K tokens per second on a single Titan X GPU.
期刊:arXiv, 2017年12月5日
网址:
http://www.zhuanzhi.ai/document/dabd379090a1173822f3f0745ae90717
-END-
专 · 知
人工智能领域主题知识资料查看获取:【专知荟萃】人工智能领域26个主题知识资料全集(入门/进阶/论文/综述/视频/专家等)
同时欢迎各位用户进行专知投稿,详情请点击:
【诚邀】专知诚挚邀请各位专业者加入AI创作者计划!了解使用专知!
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

请加专知小助手微信(Rancho_Fang),加入专知主题人工智能群交流!
点击“阅读原文”,使用专知!
展开全文



