Google&CMU新论文-用视觉进行神经语言建模
【导读】谷歌近日在arxiv上公开了一个新工作(一作CMU作者在谷歌实习),通过扩展标准的递归神经网络RNN,利用视觉特征进行神经语言建模。文中实验表明,将视觉和文本特征在中层进行融合(Middle Fusion)的结果最好。

论文地址:
https://arxiv.org/pdf/1903.02930.pdf
多模态语言模型试图将非语言特征纳入语言建模任务。在这项工作中,我们扩展了一个标准的递归神经网络(RNN)语言模型,它的特征来自于视频。我们在数据比现有工作中使用的数据集更大两个数量级的新数据上训练我们的模型,并且对模型体系结构进行了深入的探索,以结合视觉和文本特征。我们对两个语料库((YouCookII 和 20bn-somethingsomething-v2)的实验表明,表现最好的结构由视觉和文本特征的中层融合组成,perplexity减少超过25%。本文中我们分析了我们的多模态语言模型在标准RNN语言模型中得到改进的原因。
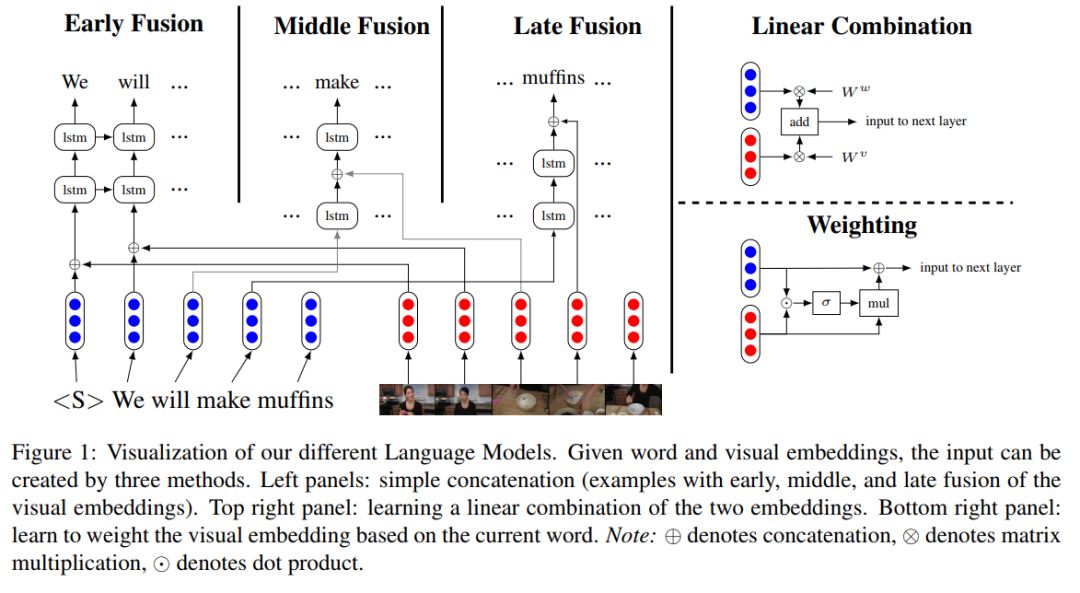
不同语言模型一览
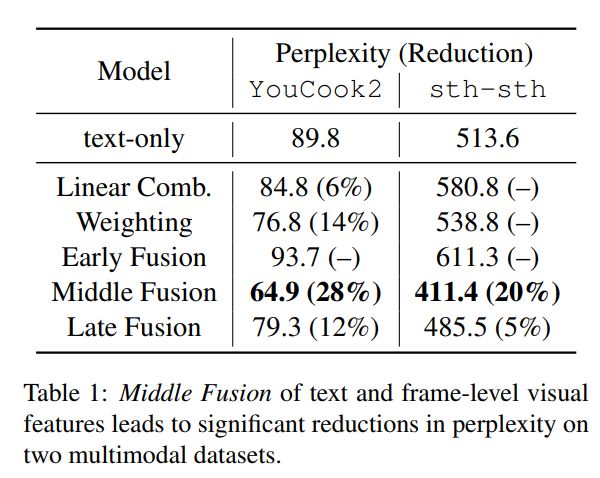
部分结果展示
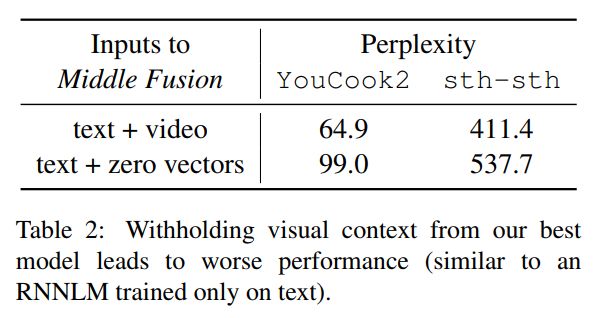
部分结果展示
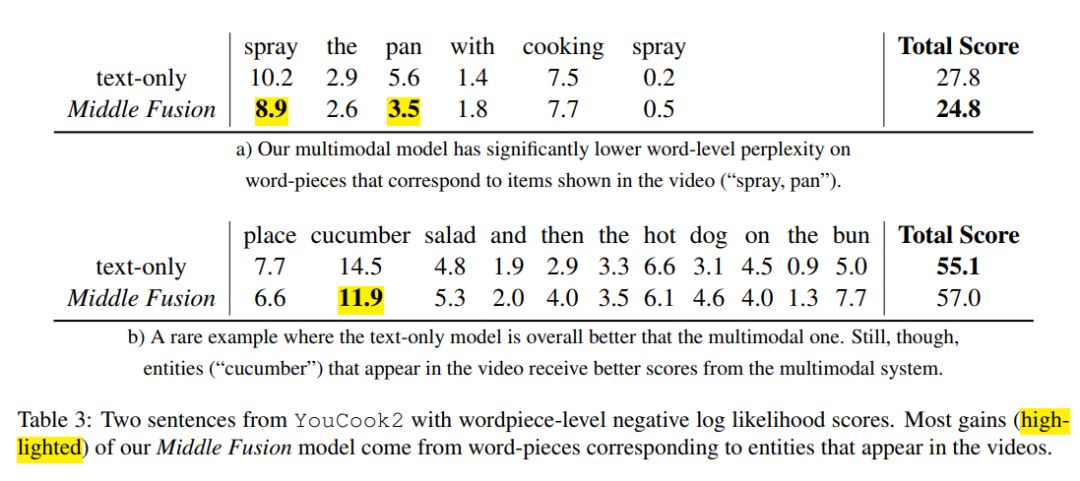
部分结果展示



《深度学习:算法到实战》课程
中科院自动化所教授博士主讲
2019
专知出品
【专知人工智能知识星球】

长按扫码加入【专知人工智能知识星球】,获取最新AI专业干货知识教程视频资料和与专家交流咨询!
【专知小助手】

长按扫码添加专知小助手微信,加入专知人工智能主题群,咨询《深度学习:算法到实战》课程,咨询技术商务合作。
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

点击“阅读原文”,了解报名专知《深度学习:算法到实战》课程

展开全文



