【干货】基于Apache Spark的深度学习
【导读】本文主要介绍了基于Apache Spark的深度学习。我们知道Spark是快速处理海量数据的框架,而深度学习一直以来都非常耗费硬件资源,因此使用在Spark框架上进行深度学习对于提升速度是非常有用的。本文介绍了Apache Spark内部结构和工作原理,以及一些实用Spark的深度学习库,并在最后介绍了相关DL pipelines库。想要学习基于Spark分布式深度学习库的读者可以了解下。
作者 | Favio Vázquez
编译 | 专知
参与 | Fan, Hujun
基于Apache Spark的深度学习
【导读】本文主要介绍了基于Apache Spark的深度学习。我们知道Spark是快速处理海量数据的框架,而深度学习一直以来都非常耗费硬件资源,因此使用在Spark框架上进行深度学习对于提升速度是非常有用的。本文介绍了Apache Spark内部结构和工作原理,以及一些实用Spark的深度学习库,并在最后介绍了相关DL pipelines库。想要学习基于Spark分布式深度学习库的读者可以了解下。
Apache Spark深度学习——第一部分
第一部分主要介绍:什么是Spark,Spark + DL的基础知识以及一些其它相关的内容。

Apache Spark的入门
如果你要在海量数据集上进行工作,那么你很有可能知道Apache Spark是什么。如果你不知道也没事! 我会告诉你它是什么。

由其创建者开发的Spark是用于大规模数据处理的快速且通用的工具。
快速意味着它比之前使用大数据(如经典MapReduce)的方法更快。加速的秘诀在于Spark在内存(RAM)上运行,这使得处理速度比在磁盘上快得多。
通用意味着它可以用于多种用途,如运行分布式SQL,创建数据管道,将数据存入数据库,运行机器学习算法,处理图形、数据流等等。
RDD(弹性分布式数据集)
Apache Spark最抽象和最开始会接触到的是弹性分布式数据集(RDD)。
RDD是可以并行操作的容错元素集合。您可以创建它们来并行化驱动程序中的现有集合,或者在外部存储系统中引用数据集。(例如共享文件系统,HDFS,HBase,或提供Hadoop InputFormat的任何数据源)
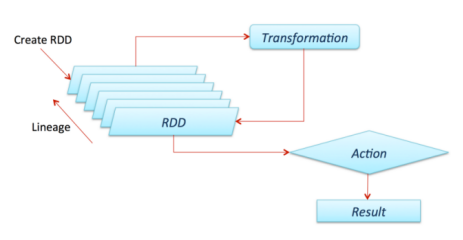
Spark非常重要且需要了解的一点是,所有的变换(我们一会就去定义它)都是懒惰的,这意味着他们不会马上计算结果。相反,他们只记得应用于某些基础数据集(例如,一个文件)的变换。变换仅在有行为需要将结果返回给驱动程序时才进行计算。
默认情况下,每次对其执行操作时,每个已转换的RDD都可能会重新计算。 但是,您也可以使用持久化(或缓存)方法将RDD保留在内存中,在这种情况下,Spark将保留群集中的元素,以便在下次查询时快速访问。还支持在磁盘上保存RDD,或在多个节点上复制RDD。
如果您想更多地了解Spark中RDD的转换和操作,请查看官方文档:
https://spark.apache.org/docs/latest/rdd-programming-guide.html#transformations
Dataframe
自Spark 2.0.0以来,DataFrame是由命名列组成的数据集。它在概念上等同于关系数据库中的表或R / Python中的dataframe,但在引擎盖下具有更丰富的优化。
我们不会在这里讨论数据集,但它们被定义为一个分布式数据集合,可以用JVM对象构建,然后使用功能转换进行操作。 它们仅在Scala和Java中可用(因为它们是键入的)。
DataFrame可以由各种来源构建而成,例如:结构化数据文件,Hive中的表,外部数据库或现有的RDD。
简而言之,Dataframes API是Spark创建者在框架中轻松处理数据的方式。 它们与Pandas Dataframes或R Dataframes非常相似,但有几个优点。当然,首先它们可以跨群集分布,所以它们可以处理大量数据,第二个是优化。
这是community采取的非常重要的一步。 2014年时,Spark与Scala或Java一起使用要快得多。并且由于性能的原因,整个Spark世界转向了Scala(是一种令人敬畏的语言)。 但对于DF API,这已不再是问题,现在您可以在R,Python,Scala或Java中使用spark来获得相同的性能。
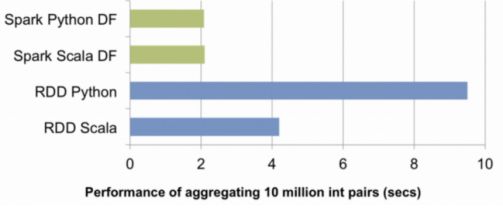
Catalyst负责这种优化。你可以把它想象成一个向导,他会接受你的查询(哦,是的,你可以在Spark中运行类似SQL的查询)和你的行为,并创建一个优化的计划用于分配计算。
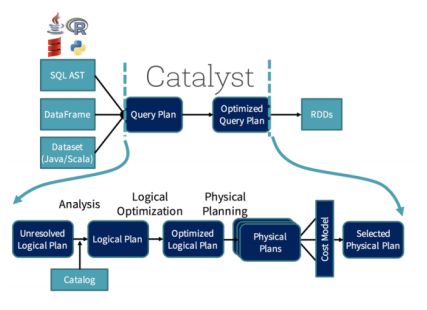
这个过程并不那么简单,但作为一名程序员你甚至不会注意到它。 现在,它一直在帮助你。
深度学习和Apache Spark
如果您想深入了解深度学习,请继续阅读以下文章:
https://towardsdatascience.com/a-weird-introduction-to-deep-learning-7828803693b0
https://towardsdatascience.com/my-journey-into-deep-learning-c66e6ef2a317
为什么想在Apache Spark做深度学习?
这是我在开始研究这个问题之前自问的问题。 答案分为两部分:
1、 Apache Spark是一个以简单和陈述的方式在集群中分布计算的框架。正在成为各行各业的标准,因此将深度学习的惊人进步加入其中将是一件好事。
2、 深度学习的有些部分计算量很大,很重! 而分配这些进程可能是解决这个问题的又一个问题,Apache Spark是我可以想到分发它们的最简单方法。
这里有几种可以使用Apache Spark进行深度学习的方法,我在此列出它们:
1、 Elephas:基于Keras和PySpark的分布式深度学习框架
https://github.com/maxpumperla/elephas
2、 Yahoo! Inc.: TensorFlowOnSpark:
https://github.com/yahoo/TensorFlowOnSpark
3、 CERN分布式Keras(Distributed Keras) (Keras + Spark) :
https://github.com/cerndb/dist-keras
4、 Qubole (tutorial Keras + Spark):
https://www.qubole.com/blog/distributed-deep-learning-keras-apache-spark/
5、 Intel Corporation: BigDL(Apache Spark的分布式深度学习库):
https://github.com/intel-analytics/BigDL
Deep Learning Pipeline
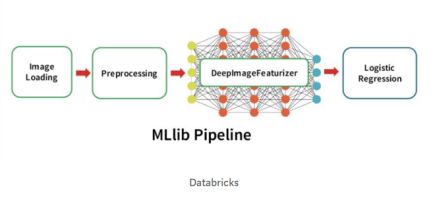
但是我将关注的这些文章的是Deep Learning Pipelines。
https://github.com/databricks/spark-deep-learning
Deep Learning Pipelines是由Databricks创建的开源代码库,提供高级API以便使用Apache Spark对Python进行可伸缩深度学习。
这是一项非常棒的工作,在合并到官方API中之前不会很长时间,所以值得一看。
与我之前列出的相比,这个库的一些优点是:
1、 延续Spark和Spark MLlib的精神,它提供了易于使用的API,通过几行代码,就可以进行深度学习。
2、 它侧重于易用性和集成性,但不牺牲性能。
3、 它由Apache Spark(也是主要贡献者)的创建者构建,因此它更有可能被合并为官方API。
4、 它是用Python编写的,因此它将与所有着名的库集成在一起,现在它使用TensorFlow和Keras这两个主要的库来做DL
在下一篇文章中,我将全面关注DL pipelines库以及如何从头开始使用它。您将看到的一件事情就是在简单的Pipeline上进行Transfer Learning,如何使用预先训练好的模型来处理“少量”数据,并能够预测事情,以及如何通过使您创建的深度学习模型可用于SQL等等,从而为您公司中的每个人提供支持。
此外,我还将在Deep Cognition Platform上创建一个环境,从而可以在笔记本上使用此库工作,以便测试所有内容。 如果您没有一个可用的帐户,请创建一个免费帐户:
http://deepcognition.ai/
关于Spark上的pipelines简要介绍,请看:
https://spark.apache.org/docs/latest/ml-pipeline.html

参考链接:
https://towardsdatascience.com/deep-learning-with-apache-spark-part-1-6d397c16abd
-END-
专 · 知
人工智能领域主题知识资料查看获取:【专知荟萃】人工智能领域26个主题知识资料全集(入门/进阶/论文/综述/视频/专家等)
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

请加专知小助手微信(Rancho_Fang),加入专知主题人工智能群交流!加入专知主题群(请备注主题类型:AI、NLP、CV、 KG等)交流~
点击“阅读原文”,使用专知
展开全文



