CNN神经网络内部知识表达的“黑”与“白“
点击上方“专知”关注获取专业AI知识!
https://zhuanlan.zhihu.com/p/31365150
▌前言
关于神经网络内部的知识表达,深究下去是个很复杂的问题,我很难给出一个面面俱到的答案。所以在这篇知乎里,我从自己两篇AAAI 2018的论文说起,只是希望提出问题,抛砖引玉。
文题中的“黑”与“白”指的是神经网络的black-box的知识表达和我希望的white-box的可解释性模型。作为博后研究员,我在UCLA带领几个学生探索一种语义层面可解释的神经网络特征表达,或者把black-box网络特征表达转化成white-box图模型。
文章第一部分主要介绍了神经网络特征表达中可能存在的bias,第二部分,我讨论了如何把一个训练好的神经网络的特征表达转化成一个可解释性的图模型。
▌Potential representation bias
近年来神经网络已经充分显示出强大的flexibility和classification accuracy。那么,在测试样本上的很高的精确度,能否证明模型表达的正确性呢?这难道这不是不言而喻的吗?"Examining CNN Representations with respect to Dataset Bias" in AAAI2018一文分析了Convolutional Network中可能的biased representations。

比如在上图中,我们用一个Convolutional Network去判断一个人是否涂了口红(口红这一属性的分类正确率应该在90%以上)。然而,当我们人为遮住嘴巴的部分或者ps上另一张嘴时,我们发现神经网络的分类值并没有出现预想中的大幅度的变化。进一步,当我们把某个conv-layer上的对口红属性敏感的feature map区域显示出来,我们发现Network其实很大程度上在用眼睛和鼻子区域的特征对口红属性进行判断。因为在训练样本中,口红往往与精致打扮的眼睛、眉毛、鼻子同时出现,而神经网络使用了co-appearing, but unreliable contexts去建模对应的属性。当然了,很多contextual information是有意义的,甚至是必不可少的,而另一部分contexts是有问题的。
因为测试样本往往具有与训练数据相似的data collection bias,所以在测试样本上的高正确率无法反应这种representation bias。
怎样在少量人工标注的前提下,自动分辨correct和biased representations?“Examining CNN Representations with respect to Dataset Bias”一文提出了一种间接检测representation bias的方法。我们仅仅需要标注一些ground-truth属性关系,比如口红属性与头发颜色没有关系,而是否涂口红与“浓妆艳摸”属性有正相关性,与“男性”属性有负相关性(属性层面的标注数量一般远远少于训练样本数量)。然后,我们提取神经网络中每个属性与中层conv-layer的feature maps上触发单元的对应关系。进一步,基于这种对应关系,我们可以计算出各个属性在神经网络中层表达上的相关性(哪些属性相互正相关,负相关,或不相关)。这样我们可以通过计算KL divergence of 标注的ground-truth属性关系和算法挖掘出来的属性关系,来判断biased representations。这些biased representations,包括blind spots(网络没有学习到一些本应改建模的特征)和failure modes(在哪类样本上可能做出错误的判断)。
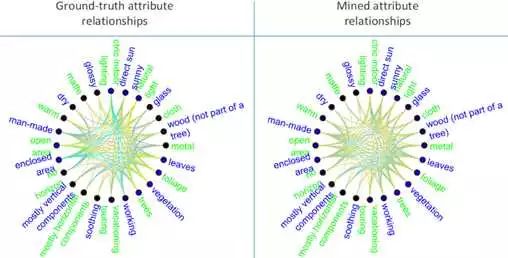
▌Disentangling CNN representations into graphical models
其实在black-box表达中,之前提到的representation bias是很难避免的。相比之下,传统的white-box图模型往往不存在这样的问题。因为传统图模型中,每个节点本身往往具有某种语义。即使模型学到了某种biased representations,图模型本身的语义结构也会帮助人们很快找到表达的错误。甚至很多情况下,图模型的结构就是人为手动设定的,这种设计保证了特征的正确性。但是让人尴尬的是,恰恰是神经网络black-box表达保证了特征提取的flexibility和信息表达的效率(见information bottleneck理论)。
那么,我们在white-box表达和模型的performance上如何取舍呢?没有答案。对于工业界来说,这个问题很简单,毋庸置疑算法的效果决定一切。
然而对于学术研究来说,梦想总是还要有的。如何能够找到一种white-box的表达方式,同时又具有神经网络表达的flexibility和信息效率,这是一个很难的问题。很多人说这是不可能的,给出不少理由,而且很多理由是很有道理的。但是做研究就是要发现新的问题、找到新的解法,如果遇到困难就一帮子打死,那还是不要做研究了。目前我们团队提出了几个想法,但是距问题的彻底解决还离得很远。
"Interpreting CNN Knowledge via an Explanatory Graph" in AAAI, 2018一文提出了用一个graphical model,namely explanatory graph去解释一个Pre-trained Convolutional Network的conv-layers上的中层表达结构 (semantic hierarchy hidden inside a pre-trained CNN)。

上图充分显示了一个神经网络某个高层conv-layer的混乱的知识表达。图中,我们列出了四个不同的filters,在不同图像上的feature map的触发分布状态。我们可以看到,同一个filter,在第一幅图上被尾巴和脚触发,在第二张图像上却表示了头部。这样,given the feature map of a specific filter of a certain conv-layer,我们很难从feature map上看出来每个触发单元所表示的object parts。我们要做的工作就是把高层conv-layer中这种混杂的表达拆分开来,表示成一个个子pattern。
这个filter到底表示了多少种不同的patterns of object parts?
哪些filters的哪些patterns是同时触发的?
这些同时触发的patterns具有怎样的空间结构呢?
进一步,Given a feature map,请告诉我每个神经触发的背后对应哪个object part?
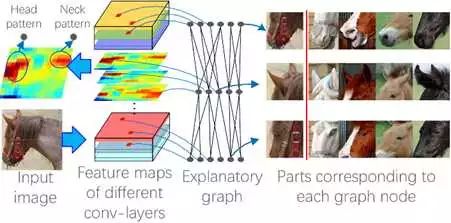
如上图所示:
一个explanatory graph有很多层,分别对应Convolutional Network的不同conv-layer。
神经网络的某个conv-layer的某个filter,可能建模了不同object parts的特征。算法自动disentangle the mixture of patterns from each filter,然后用不同的node去表示这个filter上对应的不同的parts。
explanatory graph中每一个node,表示某个特定的object part。只要这个node被触发,那么代表这个这个node对应的filter检测到了这个object part。这个node需要在空间上去鲁棒物体的shape deformation或pose的变化,在不同物体上把对应的part检测出来。
explanatory graph中每一条edge,表示相邻两个conv-layer上的两个node/pattern的co-activation关系和空间关系。
我们可以认为这个explanatory graph是对神经网络各个conv-layer层的feature map信息的高度压缩。一个神经网络有很多conv-layer,每个conv-layer有几百个filter,每个filter输出一个很大的feature map。我们把这千千万万个feature maps上的千千万万输出单元的信息,用几千个nodes表达出来。即,这些feature maps表达了那些part patterns (nodes)?这些part patterns分别对应了feature map的哪些区域?
一个explanatory graph的每一层有几千个nodes,这些nodes可以看作一个字典。任意给定一张输入图像,神经网络可能仅仅触发了explanatory graph中的一小部分nodes。

上图显示了利用每个graph node在各个图像上做inference的结果。每个node只对应一个feature map上的某个activation peak,而在不同图像上这个peak往往对应相同的语义。比如第一个node,表示头部,第二个node表示脚部。
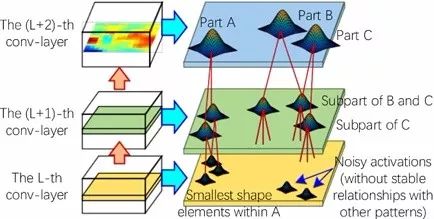
算法:简单的来说,我们假设每个filter包含了N个patterns(nodes),就像GMM一样,我们用mixture of patterns去拟合对应的feature maps。同时我们要建模不同conv-layer间patterns的空间关系。即,本conv-layer层的patterns的位置不但要充分的拟合出当前的feature map形状,而且要与上一层相关的patterns保持特定的空间关系。算法的核心就是去学习patterns之间的相关性,去学习每个pattern与上层patterns的空间关系。我们用这种空间关系去disentangle feature maps of conv-layers。
算法本身很简单。我们从标准GMM公式中衍生出三、四个新公式,去建模pattern的空间关系。这里我就不赘述算法细节了。
这个算法隐含了某个前提假设。即,如果一个pattern可以在上一个conv-layer找到数十个共同触发的patterns,并且这些patterns在各个图像中都保持稳定的空间关系。那么这一组patterns往往都表示某种特定的object part。
Evaluation metric
我们希望把Convolutional Network转化成一个interpretable graphical model,那么如何去评价一个特征表达的interpretability是一个很重要的问题。周博磊在CVPR17提出了一种评价方法。我们在AAAI18中提出了另一种评价标准,即location instability,用来评价某个object-part pattern的interpretability。

我们假设,如果一个pattern在各个图像中,都表示相同的object part,那么这个pattern在不同图像上的检测位置与物体上某些ground-truth landmarks的相对距离应该保持相对稳定。比如,这个pattern总是被身体和尾巴的连接处触发,那么在不同图像上,pattern的检测位置和尾尖landmark的相对距离应该保持相对稳定(我不考虑蛇等特殊物体类别)。这样,我们就可以用这些相对距离在不同图像上的标准差,去评价这个pattern的location instability。我们可以设定多个landmarks,计算得到关于各个landmark的location instability的平均值。实验中Nodes in the explanatory graph的location instability远远低于各个baselines。
Potential applications
Explanatory graph可以作为一个事先训练好的视觉字典。当我们成功训练了一个神经网络去做某个类别的分类时,我们相信这个神经网络的conv-layers已经建模了大量的object part特征。我们的explanatory graph就是把这些混杂在一起的特征表达,一一拆分出来。每个node表示了千百个同类物体的共有的part特征,所以这些node有很高的transferability。
这些nodes可以用在one/multi-shot part localization上。当我标注一个bounding box of an object part,我可以用这一个bounding box从explanatory graph中提取数百个相关的node去表示这个part,从而在新的图像中去定位这个object part。比起传统的方法,我们的方法降低了约1/3 localization errors。
作者介绍:
加州大学洛杉矶分校 ( UCLA ) · 博士后
Qs.Zhang张拳石,加州大学洛杉矶分校UCLA博士后,研究方向包括机器学习,计算机视觉。个人主页:https://sites.google.com/site/quanshizhang/
-END-
专 · 知
人工智能领域主题知识资料查看获取:【专知荟萃】人工智能领域22个主题知识资料全集(入门/进阶/论文/综述/视频/专家等)
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!
请关注我们的公众号,获取人工智能的专业知识。扫一扫关注我们的微信公众号。


点击“阅读原文”,使用专知!
展开全文



