【干货】推荐系统中的机器学习算法与评估实战
【导读】推荐系统是机器学习技术在企业中最成功和最广泛的应用之一。本文作者结合MLMU演讲【1】的Slides,对推荐系统的算法、评估和冷启动解决方案做了详细的介绍。
作者 | Pavel Kordík
编译 | 专知
翻译 | Xiaowen

Machine Learning for Recommender systems — Part 1 (algorithms, evaluation and cold start)
引言
你可以在许多用户与项目交互的场景中应用推荐系统。
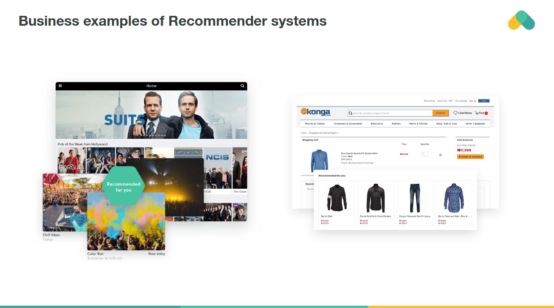
你可以在零售、视频点播或音乐流中找到大型推荐系统。为了开发和维护这样的系统,公司通常需要一群昂贵的数据科学家和工程师。这就是为什么即使是像BBC这样的大公司也决定外包其推荐服务的原因。

我们公司总部设在布拉格,开发了一个通用的自动化推荐引擎,能够适应多个领域的业务需求。我们的引擎已被世界各地的数百家企业使用。

令人惊讶的是,对于媒体的新闻或视频推荐、旅行和零售中的产品推荐或个性化推荐,都可以通过类似的机器学习算法来处理。此外,这些算法还可以在每次推荐请求中使用我们特有的查询语言进行调整。
算法

推荐系统中的机器学习算法通常分为两类:基于内容的推荐方法和协同过滤方法,尽管现代推荐者将这两种方法结合在一起。基于内容的方法是基于项目属性的相似性和协作方法,从交互中计算相似度。下面我们主要讨论协同过滤方法,使用户能够发现与过去查看过的项目不同的新内容。

协同过滤方法与交互矩阵一起工作,当用户提供项目的显式评分时,这种交互矩阵也可以称为评分矩阵。机器学习的任务是学习一个函数,它可以预测项目对每个用户的效果。矩阵通常很大,非常稀疏,而且大多数值都丢失了。

最简单的算法是计算行(用户)或列(项)的余弦或其他相关相似性,并推荐k个最近邻居喜欢的项。
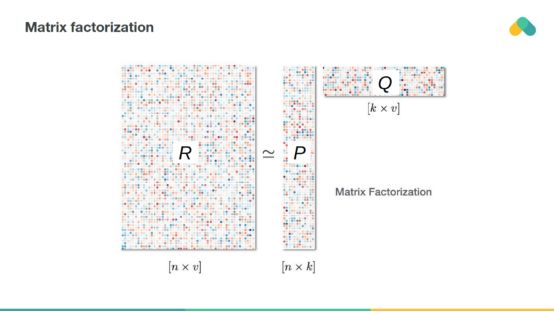
基于矩阵因式分解的方法试图降低相互作用矩阵的维数,并将其近似为两个或多个具有k个潜在分量的小矩阵。

通过将相应的行和列相乘,你可以根据用户预测项目的评分。训练误差可以通过比较非空评分和预测评分来获得。还可以通过增加惩罚项,保持潜在向量的低值来调整训练损失。

最流行的训练算法是随机梯度下降算法,通过对p q矩阵的列和行进行梯度更新,使下降损失最小化。

或者,可以使用交替最小二乘法,通过一般最小二乘步骤迭代优化矩阵p和矩阵q。

关联规则也可用于推荐。经常在一起消费的项目与图形中的边缘相关联。你可以看到一组畅销书(几乎每个人都与之交互的紧密连接的项目)和小的、分离的内容集群。

从交互矩阵中挖掘出的规则至少应该有一些最小的支持度(support)和置信度(confidence)。支持度与发生频率有关,比如畅销书有很高的支持度。高置信度意味着规则不会经常被违反。

挖掘规则的规模不大,先验算法探索了可能的频繁项集的状态空间,消除了搜索空间中不频繁的分支。
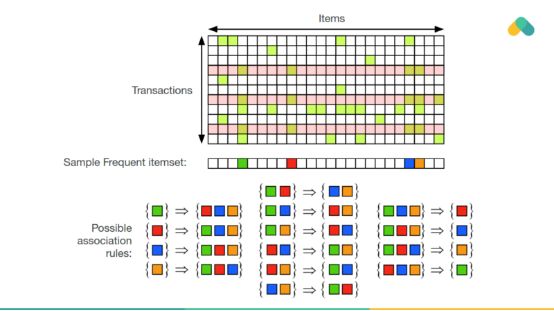
频繁项集用于生成规则,这些规则产生推荐。

例如,我们展示了从捷克共和国的银行交易中提取的规则。节点(交互)是终端,边缘是频繁的交易。你可以根据过去的取款/付款推荐相关的银行终端。
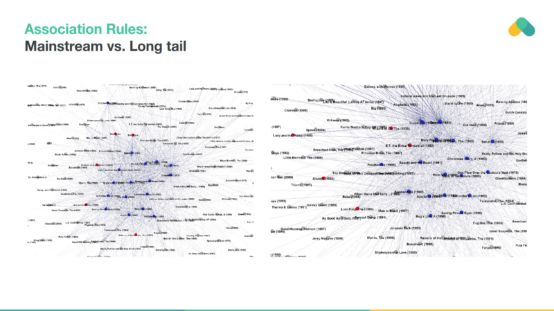
惩罚受欢迎的项目和提取支持度较低的长尾规则会产生有趣的规则,使推荐多样化并有助于发现新的内容。
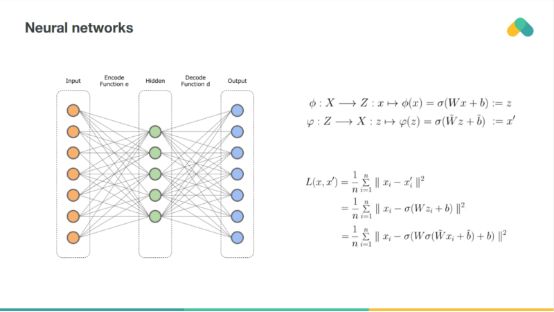
评分矩阵也可以用神经网络进行压缩,所谓的自编码器与矩阵分解非常相似,具有多个隐藏层和非线性的深层自编码器更强大,但更难训练。神经网络也可以用来预处理项属性,这样就可以将基于内容的方法和协同过滤方法结合起来。

上面给出了user-KNN Top-N推荐伪代码。

关联规则可以通过多种不同的算法来挖掘。这里我们给出了最佳规则推荐(Best-Rule recommendations)的伪代码。

上面给出了矩阵因式分解的伪代码。

在协同深度学习中,结合项目属性与自编码器同时训练矩阵因式分解,当然还有更多的算法可用于推荐,本文的下一部分介绍了一些基于深度学习和强化学习的方法。
推荐系统的评估
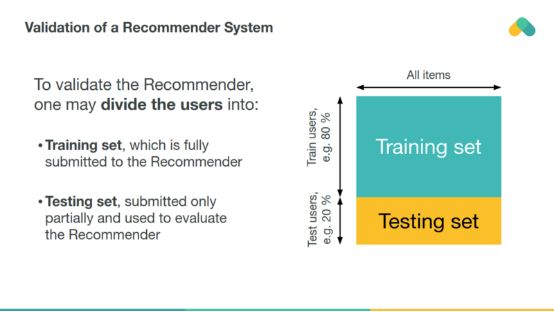
推荐者可以与历史数据上的经典机器学习模型(离线评估)进行类似的评估。

随机选择的测试用户之间的交互作用被交叉验证,以估计推荐者在未见的评级上的性能。

尽管许多研究表明,均方误差(RMES)对在线性能的估计能力较差,但它仍得到了广泛的应用。

更实用的离线评估措施是召回率(Recall)或准确率(Precision)评估正确推荐项目的百分比(不包括推荐项目或相关项目)。DCG还考虑到了假设项目的相关性对数下降时的位置。
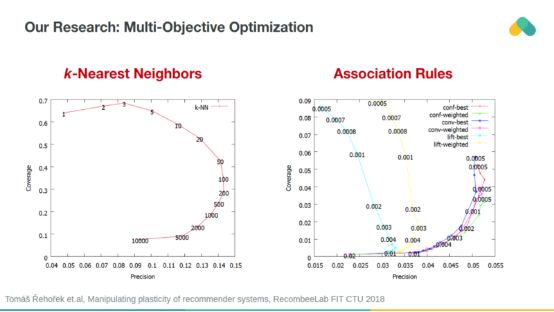
我们可以使用对离线数据偏差不太敏感的附加度量。Catalog coverage以及Recall或Precision可以用于多目标优化。我们在所有算法中引入正则化参数,允许对它们的可塑性进行操作,并惩罚对流行项的推荐。
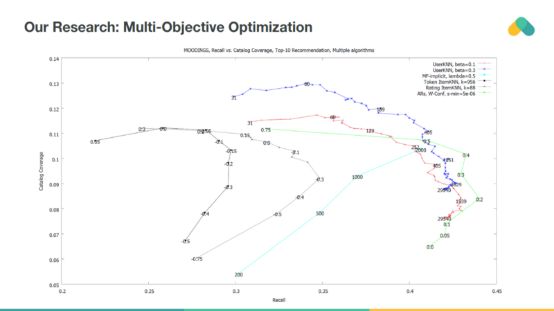
Recall和coverage都应该最大化,因此推动推荐系统向准确和多样化发展,使用户能够探索新的内容。
冷启动和基于内容的推荐

交互有时会丢失。冷启动产品或冷启动用户没有足够的交互来可靠地度量其交互相似性,因此协同过滤方法无法产生推荐。
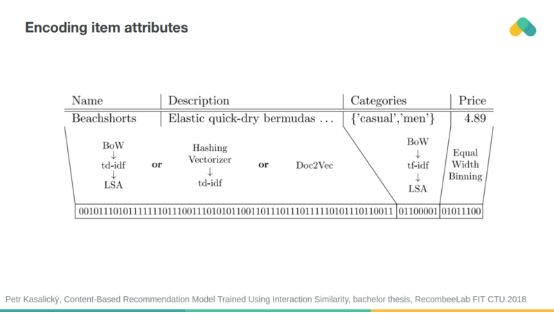
当考虑到属性相似性时,冷启动问题可以减少。你可以将属性编码成二进制向量,并提供系统进行推荐。
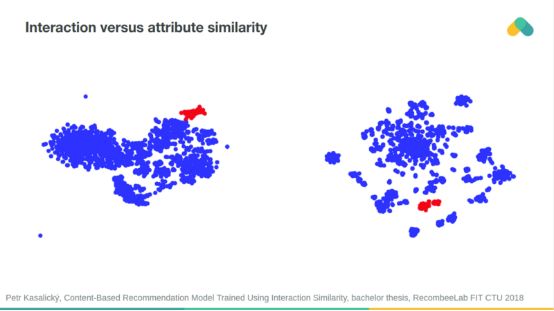
基于交互相似性和属性相似性的项目聚类往往是对齐的。
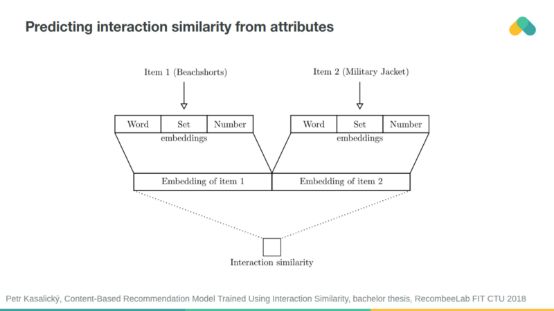
你可以使用神经网络从属性相似性预测交互相似性,反之亦然。

有很多其他方法使我们能够减少冷启动问题,提高推荐质量。在第二部分中,我们将会讨论基于会话(session based)的推荐技术、深度推荐、集成算法和自动化,使我们能够在生产中运行和优化数千种不同的推荐算法。
参考链接:
1.https://www.meetup.com/Prague-Machine-Learning/events/250915214/
原文链接:
https://medium.com/recombee-blog/machine-learning-for-recommender-systems-part-1-algorithms-evaluation-and-cold-start-6f696683d0ed
-END-
专 · 知
人工智能领域主题知识资料查看与加入专知人工智能服务群:
【专知AI服务计划】专知AI知识技术服务会员群加入与人工智能领域26个主题知识资料全集获取。欢迎微信扫一扫加入专知人工智能知识星球群,获取专业知识教程视频资料和与专家交流咨询!

请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请加专知小助手微信(扫一扫如下二维码添加),加入专知主题群(请备注主题类型:AI、NLP、CV、 KG等)交流~

请关注专知公众号,获取人工智能的专业知识!
点击“阅读原文”,使用专知
展开全文



