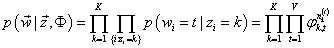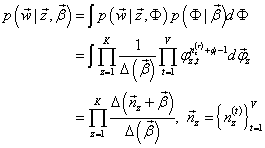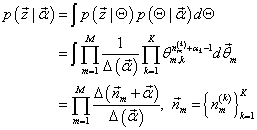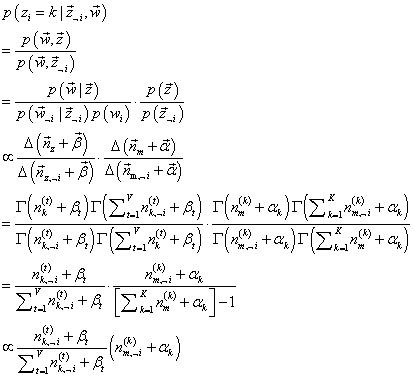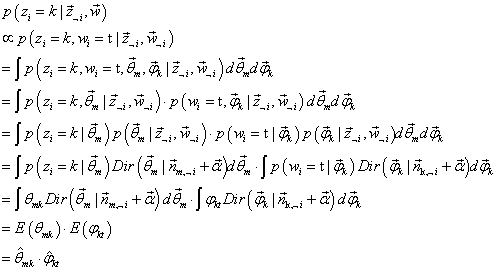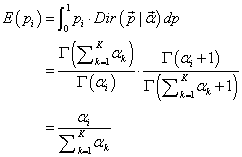3、Gibbs采样
Blei的LDA原始论文(Latent Dirichlet
Allocation)中给出隐变量的后验分布如下图,核心问题是给出一篇文档,如何推断隐变量:
p(θ,z∣w,α,β)=p(w∣α,β)p(θ,z,w∣α,β)
其中,由于文档生成过程可写为:
p(θ,z,w∣α,β)=p(θ∣α)n=1∏Np(zn∣θ)p(wn∣zn,β)
对隐变量积分可得:
p(w∣α,β)=∏iΓ(αi)Γ(∑iαi)∫(i=1∏kθiαi−1)(n=1∏Ni=1∑kj=1∏V(θiβij)wnj)dθ
由于
θ和
β之间的耦合,导致上述隐变量的推断通常是难以直接计算的,因此引入各种近似计算方法,比如变分法和Gibbs Sampling方法。
类似于PLSA,LDA的原始论文中是用的变分+EM算法估计未知参数,后来发现另一种估计LDA未知参数的方法更直观,更容易理解,这种方法就是:Gibbs Sampling,有时叫Gibbs采样或Gibbs抽样,都一个意思。Gibbs抽样是马尔可夫链蒙特卡尔理论(MCMC)中用来获取一系列近似等于指定多维概率分布(比如2个或者多个随机变量的联合概率分布)观察样本的算法。
OK,给定一个文档集合,w是可以观察到的已知变量,
α和
β是根据经验给定的先验参数,其他的变量z,θ和φ都是未知的隐含变量,需要根据观察到的变量来学习估计的。根据LDA的图模型,可以写出所有变量的联合分布:
p(w⃗m,z⃗m,θ⃗m,Φ∣α⃗,β⃗)=n=1∏Nmp(wm,n∣φ⃗zm,n)p(zm,n∣θ⃗m)⋅p(θ⃗m∣α⃗)⋅p(Φ∣β⃗)
注:上述公式中及下文中,
zm,n等价上文中定义的
zi,j,
wm,n等价于上文中定义的
wi,j,
φ⃗zm,n等价于上文中定义的
ϕzi,j,
θm等价于上文中定义的
θi。
因为
α是文档-主题分布的狄利克雷先验参数,文档-主题分布
Θ确定具体主题,且
β是主题-词分布的狄利克雷先验参数、主题-词分布
Φ确定具体词。对上式进行积分,在Collapsed LDA Gibbs sampler中(参照Parameter estimation for text analysis_Gibbs sampling)。将
zm,n视为隐变量(视为马尔科夫链的状态变量),
wi,j为观测值,将参数
Θ和
Φ解释为观测值和隐变量的统计量。将其中的参数
Θ和
Φ整合,即把这两个变量积分掉了,从而简化联合分布的写法,这种方法被称为“collapsed”。所以上述式子等价于下述式子所表达的联合概率分布:
p(w⃗m,z⃗m,θ⃗m,Φ∣α⃗,β⃗)=n=1∏Nmp(wm,n∣φ⃗zm,n)p(zm,n∣θ⃗m)⋅p(θ⃗m∣α⃗)⋅p(Φ∣β⃗)
其中,第一项因子
p(w⃗∣z⃗,β⃗)表示的是根据确定的主题
z⃗和主题-词分布的先验分布参数
β采样词的过程,第二项因子
p(z⃗∣α⃗)是根据文档-主题分布的先验分布参数
α采样主题的过程,这两项因子是需要计算的两个未知参数。
由于这两个过程是独立的,所以下面可以分别处理,各个击破。
第一个因子
p(w⃗∣z⃗,β⃗),可以根据确定的主题
z⃗和从先验分布
β取样得到的主题-词分布
Φ产生:
p(w⃗∣z⃗,Φ)=i=1∏Wp(wi∣zi)=i=1∏Wφzi,wi
由于样本中的词服从参数为主题
zi的独立多项分布,这意味着可以把上面对词的乘积分解成分别对主题和对词的两层乘积:
其中,
nk(t)是词 t 在主题 k 中出现的次数。
回到第一个因子上来。目标分布
p(w⃗∣z⃗,β⃗)需要对主题-词分布Φ积分,且结合我们之前定义的Dirichlet分布的归一化系数
Δ(α⃗)的公式
Δ(α⃗)=∫k=1∏Vpkαk−1dp⃗
可得:
这个结果可以看作K个Dirichlet-Multinomial模型的乘积。
现在开始求第二个因子
p(z⃗∣α⃗)。类似于
p(w⃗∣z⃗,β⃗)的步骤,先写出条件分布,然后分解成两部分的乘积:
p(z⃗∣Θ)=i=1∏Wp(zi∣di)=m=1∏Mk=1∏Kp(zi=k∣di=m)=m=1∏Mk=1∏Kθm,knm(k)
其中,
di表示的单词 i 所属的文档,
nm(t)是主题 k 在文章 m 中出现的次数。
对文档-主题分布Θ积分可得:
综合第一个因子和第二个因子的结果,得到
p(w⃗,z⃗)的联合分布结果为:
p(z⃗,w⃗∣α⃗,β⃗)=z=1∏KΔ(β⃗)Δ(n⃗z+β⃗)m=1∏MΔ(α⃗)Δ(n⃗m+α⃗)
接下来,有了联合分布
p(w⃗,z⃗),咱们便可以通过联合分布来计算在给定可观测变量 w下的隐变量z的条件分布(后验分布)
p(z⃗∣w⃗)来进行贝叶斯分析。
换言之,有了这个联合分布后,要求解第m篇文档中的第n个词(下标为
i=(m,n)的词)的全部条件概率就好求了。
先定义几个变量。
¬i表示除去
i的词,
w⃗={wi=t,w⃗¬i},
z⃗={zi=k,z⃗¬i}。然后,排除当前词的主题分配,即根据其他词的主题分配和观察到的单词来计算当前词主题的概率公式为:
且有:
最后一步,便是根据Markov链的状态
zi获取文档-主题分布的参数Θ和主题-词分布的参数Φ。
换言之根据贝叶斯法则和Dirichlet先验,以及上文中得到的
p(w⃗∣z⃗,Φ)和
p(z⃗∣Φ)各自被分解成两部分乘积的结果,可以计算得到每个文档上Topic的后验分布和每个Topic下的词的后验分布分别如下(据上文可知:其后验分布跟它们的先验分布一样,也都是Dirichlet
分布):
p(φ⃗k∣z⃗m,α⃗)=Zφk1n=1∏Nmp(zm,n∣θ⃗m)⋅p(φ⃗k∣α⃗)=Dir(φ⃗k∣n⃗m+α⃗)
p(φ⃗k∣z⃗,w⃗,β⃗)=Zφk1{i:zi−k}∏p(wi∣φ⃗k)⋅p(φ⃗k∣β⃗)=Dir(φ⃗k∣n⃗k+β⃗)
其中,
n⃗m是构成文档m的主题数向量,
n⃗k是构成主题k的词项数向量。
此外,别忘了上文中所述的Dirichlet的一个性质,如下:
如果
p⃗∼Dir(t⃗∣α⃗),同样可以证明有下述结论成立:
E(pi)=(∑i=1Kαiα1,∑i=1Kαiα2,...,∑i=1KαiαK)
即:如果
p⃗∼Dir(p⃗∣α⃗),则
p⃗中的任一元素的期望是:
可以看出,超参数
αk的直观意义就是事件先验的伪计数(prior pseudo-count)。所以,最终求解的两个Dirichlet 后验分布期望为:
θm,k=∑k=1Knm(k)+αknm(k)+αk
φk,t=∑t=1Vnk(t)+βtnk(t)+βt
然后将
φk,t和
θm,k的结果代入之前得到的
p(zi=k∣z⃗¬i,w⃗)∝p(zi=k,wi=t∣z⃗¬i,w⃗¬i)的结果中,可得:
p(zi=k∣z⃗¬i,w⃗)∝∑k=1Knm,¬i(k)+αknm,¬i(k)+αk⋅∑t=1Vnk,¬i(t)+βtnk,¬i(t)+βt
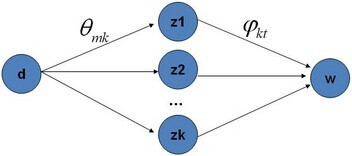
仔细观察上述结果,可以发现,式子的右半部分便是
p(topic∣doc)⋅p(word∣topic),这个概率的值对应着
doc→topic→word的路径概率。如此,K个topic 对应着K条路径,Gibbs Sampling 便在这K 条路径中进行采样,如下图所示:
就这样,Gibbs Sampling通过求解出文档-主题分布和主题-词分布的后验分布,从而成功解决文档-主题分布和主题-词分布这两参数未知的问题。
参考文献
-
http://www.arbylon.net/publications/text-est.pdf —《Parameter estimation for text analysis》
-
rickjin的LDA数学八卦—http://vdisk.weibo.com/s/q0sGh/1360334108?utm_source=weibolife
-
马晨的LDA算法漫游指南—https://yuedu.baidu.com/ebook/d0b441a8ccbff121dd36839a.html