【卡内基梅隆大学-CMU】机器学习中的公平性,Learning Fair Representations
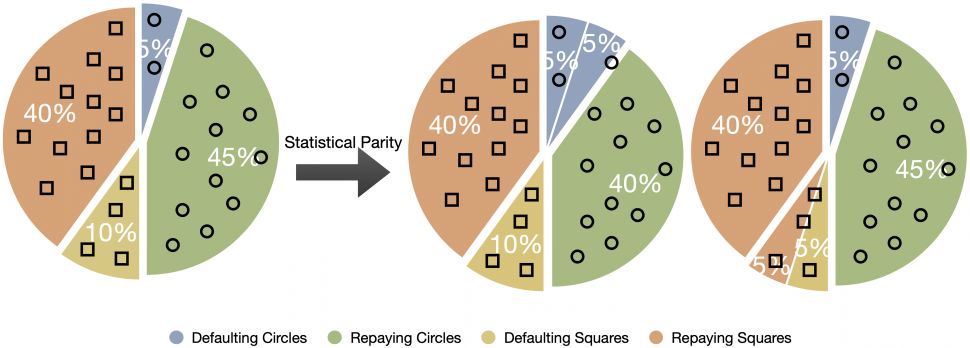
图1所示 统计奇偶性与最优决策的权衡。在本例中,由于圆圈组和正方形组之间的人口水平偿还率不同,为了遵守统计上的均等性,决策者必须拒绝向一些偿还圆圈组的申请人提供贷款(左),或者向一些违约的正方形组的申请人提供贷款(右)。例子调整从书“道德算法”。
机器学习应用在高风险领域(如刑事判决、医学测试、在线广告等)的流行,至关重要的是要确保这些决策支持系统不会传播历史数据中可能存在的现有偏见或歧视。一般来说,在算法公平文献中有两个关于公平的中心概念。第一个是个体公平,它要求公平的算法以相似的方式对待相似的个体。然而,在实践中,通常很难找到或设计一个社会可接受的距离度量来捕获个体之间关于特定任务的相似性。相反,在这篇博客文章中,我们关注的是公平的第二个概念,群体公平,更具体地说是统计上的平等,这本质上要求预测器的结果在不同的子群体中是平等的。
地址:
https://blog.ml.cmu.edu/2020/02/28/inherent-tradeoffs-in-learning-fair-representations/
Inherent Tradeoffs in Learning Fair Representations
H. Zhao and G. Gordon
In Proceedings of the 33rd Advances in Neural Information Processing Systems (NeurIPS 2019)
https://arxiv.org/pdf/1906.08386.pdf
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“MLF” 就可以获取《机器学习中的公平性,Learning Fair Representations》专知下载链接



展开全文



