图卷积神经网络(GCN)文本分类详述
【导读】近年来,图卷积神经网络(GCN)将深度神经网络应用于图结构数据上,取得了可喜的成果,已成为当下火热的研究方向。本文对图卷积神经网络在文本分类的应用进行的详细阐述。
基于图卷积网络的文本分类算法
原文: https://arxiv.org/pdf/1809.05679.pdf
Liang Yao, Chengsheng Mao, Yuan Luo∗
Northwestern University
Chicago IL 60611
{liang.yao, chengsheng.mao, yuan.luo}@northwestern.edu
摘要
文本分类是自然语言处理中一个重要的经典问题。如今有很多基于卷积神经网络的分类研究(规则网格的卷积,例如序列)。 然而,只有有限数量的研究探索了更多灵活的图卷积神经网络(非网格结构的卷积,例如任意图形)。在这项工作中,我们建议使用图卷积网络进行文本分类。我们基于词汇共现和文档和词的关系为语料库构建单个文本图,然后为语料库学习文本图卷积网络(Text Graph Convolutional Network, Text GCN)。我们的 Text GCN 为单词和文档进行 One-Hot 编码初始化,然后它共同学习单词和文档的嵌入,由已知文档的类标签进行监督。我们在多个基准数据集上的实验结果证明了一个没有任何外部词嵌入的普通 Text GCN 优于目前文本分类最先进的 方法。另一方面,Text GCN 也学习了预测词和文档的嵌入。此外,实验结果表明,因为我们降低了训练数据的百分比,Text GCN 相对于最先进比较方法的改进变得更加突出,也表明了Text GCN 在文本分类中减少训练数据情况下具有较好的鲁棒性。
介绍
文本分类是自然语言处理(Natural Language Processing,NLP)中的基本问题。文本分类有许多应用,例如文章组织,新闻过滤,垃圾邮件检测,意见挖掘和计算表型分析(Aggarwal and Zhai 2012; Zeng et all.2018)。文本分类的基本中间步骤是文本表示。传统方法用手工制作的的特征表示文本,例如稀疏词汇特征(例如词袋和n-grams)。最近,深度学习模型被广泛用于学习文本表示,包括卷积神经网络(CNN) (Kim 2014)和循环神经网络(RNN),如长短时记忆(LSTM) (Hochreiter和Schmidhuber 1997)。因为CNN和RNN优先考虑局部性和序列性(Battaglia et al.2018),这些深度学习模型可以较好地捕捉局部连续词序列的语义和句法信息,但是可能会忽略语料库中具有非连续和长距离语义的全局词汇的共现(Peng et al. 2018)。
最近,一个叫做图神经网络或图嵌入的新型研究方向引起了广泛的关注(Battaglia et al. 2018; Cai, Zheng, and Chang 2018)。图神经网络能够有效地处理具有丰富关系结构的任务,并在图嵌入中保持图的全局结构信息。
本文提出了一种新的基于图神经网络的文本分类方法。我们从整个语料库中构造一个大型图,其中包含作为节点的单词和文档。我们使用图卷积网络(GCN) (Kipf和Welling 2017)对图进行建模,GCN是一种简单有效的图神经网络,能够捕捉高阶邻域信息。两个词节点之间的边由词的共现信息构建,一个词节点与文档节点之间的边由词的频率和词的文档频率构建。然后将文本分类问题转化为节点分类问题。该方法能在少量标注文档的情况下实现较强的分类性能,并能可解释地学习单词和文档节点嵌入。
我们的源代码在:
https://github.com/yao8839836/text_gcn
总而言之,我们的贡献如下:
提出了一种新的基于图神经网络的文本分类方法。据我们所知,这是首次将整个语料库建模为异构图,并结合图神经网络学习单词和文档嵌入。
在几个基准数据集上的结果表明,我们的方法优于现有的文本分类方法,无需使用预先训练的词嵌入或外部知识。我们的方法还可以自动学习预测词和文档嵌入。
相关工作
传统文本分类
传统的文本分类研究主要集中在特征工程和分类算法上。对于功能工程,最常用的功能是词袋功能。此外,还设计了一些更复杂的功能,如n-grams (Wang and Manning 2012)和本体中的实体(Chenthamarakshan et al.2011)。也有将文本转换为图的研究,并对图和子图进行特征工程(Luo, Uzuner, and Szolovits 2016; Rousseau, Kiagias, and Vazirgia- nnis 2015; Skianis, Rousseau, and Vazirgiannis 2016; Luo et al. 2014;Luo et al. 2015)。与这些方法不同,我们的方法可以自动学习作为节点嵌入的文本表示。
基于文本分类的深度学习
深度学习的文本分类研究可以分为两组。一组研究侧重于基于词嵌入的模型(Mikolov et al. 2013; Pennington, Socher, and Manning2014)。最近的几项研究表明,文本分类深度学习的成功在很大程度上取决于嵌入词的有效性(Shen et al. 2018; Joulin et al. 2017; Wang et al. 2018)。一些作者将无监督词嵌入聚合为文档嵌入,然后将这些文档嵌入输入分类器(Le and Mikolov 2014; Joulin et al. 2017)。其他共同学习词/文档和文档标签嵌入(Tang, Qu, and Mei 2015;Wang et al. 2018)。我们的工作是与这些方法相联系的,主要的区别是这些方法是在学习单词嵌入之后构建文本表示,而我们同时学习单词和文档嵌入来进行文本分类。
另一组研究使用了深度神经网络。两个有代表性的深度网络是CNN和RNN。(Kim 2014)使用CNN进行句子分类。该体系结构是计算机视觉中使用的CNNs的直接应用,但具有一维卷积。(Zhang, Zhao, and LeCun 2015)和(Conneau et al. 2017)设计了字符级CNNs,并取得了很好的效果。(Tai, Socher, and Manning 2015), (Liu, Qiu, and Huang 2016)和(Luo 2017)使用LSTM,一种特定类型的RNN,可以学习文本表示。为了进一步提高这些模型的表示灵活性,将注意机制引入到文本分类模型中(Yang et al. 2016;Wang et al.2016)。虽然这些方法有效且应用广泛,主要集中在局部连续词序列上,但没有明确使用语料库中全局词共现信息。
图神经网络
图神经网络这一课题近年来受到越来越多的关注(Cai, Zheng, and Chang 2018; Battaglia et al. 2018)。许多作者将CNN等成熟的神经网络模型推广到规则网格结构(二维网格或一维序列)上,以处理任意结构的图(Bruna et al. 2014; Henaff, Bruna, and LeCun 2015; Deffer-rard, Bresson, and Vandergheynst 2016; Kipf andWelling 2017)。Kipf和Welling在他们的开创性工作中提出了一种简化的图神经网络模型——图卷积网络(GCN),该模型在一系列基准图数据集(Kipf和Welling2017)上取得了最先进的分类结果。GCN还在语义角色标注(Marcheggianiand Titov 2017)、关系分类(Li,Jin, and Luo 2018)和机器翻译(Bastings et al. 2017)等NLP任务中进行了探索,其中GCN用于对句子的句法结构进行编码。最近的一些研究探索了用于文本分类的图神经网络(Henaff,Bruna, and LeCun 2015;Defferrard, Bresson and Vanderg- heynst 2016; Kipf and Welling2017;Penget al. 2018; Zhang, Liu, and Song 2018)。然而, 他们或是将文档或句子视为单词节点的图表(Defferrard,Bresson, and Vander-gheynst 2016;Peng et al. 2018; Zhang, Liu, and Song 2018);或是依赖于不常见的文献引用关系构建图表(Kipf和Welling2017)。相反,在构建语料库图时,我们将文档和单词视为节点(因此是异构图),不需要文档间的关系。
方法
图卷积网络(GCN)
GCN (Kipf Welling2017)是一种多层神经网络,它直接在图上运行,根据节点的邻域属性来诱导节点的嵌入向量。形式上,考虑一个图 G = (V,E),其中V (|V| = n) 和 E 分别是节点和边的集合。假设每个节点都与自身相连,即对任何v,都有(v,v) ∈ E 。让X ∈R^(n×m) 矩阵包含n个节点的所有特性,m是特征向量的维数,每一行 x_v ∈ R^m 都是v的特征向量。我们引入G的邻接矩阵A,及其度矩阵D,其中D_ii =∑_j A_ij,由于自循环,A的对角线元素被设置为1。GCN只能通过一层卷积捕获关于近邻的信息。当多个GCN层堆叠在一起时,有关较大邻域的信息就会被集成。对于单层GCN,新的k维节点特征矩阵L^(1) ∈R^(n×k) 可以计算成:

其中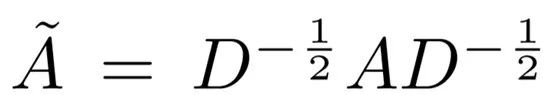
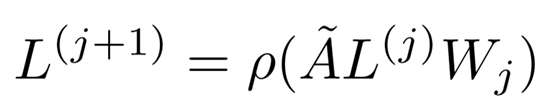
其中,j表示层数,L^(0)=X 。
文本图卷积网络(Text GCN)
我们构建了一个包含单词节点和文档节点的大型异构文本图,这样可以明确地对全局单词共现进行建模,并且可以很容易地调整图卷积,如图1 所示。文本图|V |中的节点数是文档的数量(语料库大小)加上语料库中唯一单词的数量(词汇表大小)。我们简单地将特征矩阵 X = I 设置为一个单位矩阵,这意味着每个单词或文档都表示为One-Hot向量作为TextGCN的输入。我们基于文档中单词共现(document-word edges)和整个语料库中单词共现(word-word edges)在节点之间构建边。文档节点之间的边的重量和一个单词节点是文档中这个词的词频-逆文档频率(TF-IDF),其中词频是在文档中单词出现的次数,逆文档频率是包含这个词的文档数量的倒数的对数。我们发现使用TF-IDF权重比只使用词频更好。为了利用全局词的共现信息,我们对语料库中的所有文档使用一个固定大小的滑动窗口来收集共现统计信息。我们使用点互信息(PMI),一种测量单词关联性的流行方法,来计算两个单词节点之间的权重。在我们的初步实验中,我们也发现使用PMI比使用单词共现计数得到更好的结果。形式上,节点i与节点j之间的边的权值定义为:

一对单词i, j的PMI值的计算公式为:
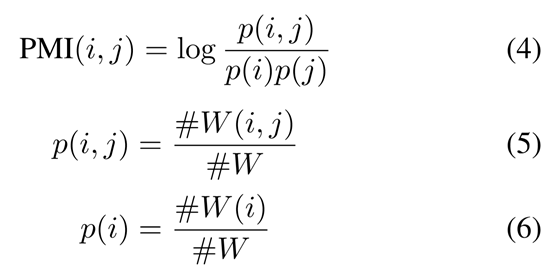
其中,#W( i ) 是语料库中包含单词 i 的滑动窗口的数量,#W( i, j )是包含单词 i 和 j 的滑动窗口的数量,#W 是语料库中滑动窗口的总数。PMI为正值时,语料库中词语的语义关联度较高;PMI为负值时,语料库中词语的语义关联度较低或为零。因此,我们只在PMI为正值的词对之间添加边。
构建文本图后,我们将图送入一个简单的两层GCN中(Kipf and Welling 2017),第二层(单词/文档)节点嵌入与标签集大小相同,并送入一个softmax分类器:

其中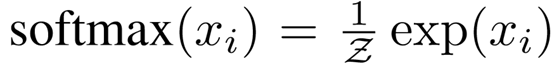
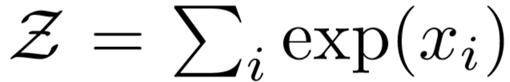
损失函数定义为所有已标记文档的交叉熵误差:
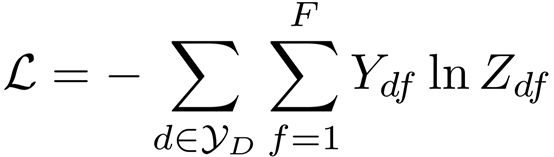
其中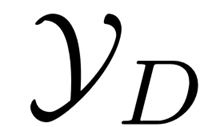
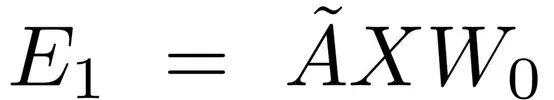
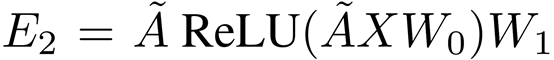
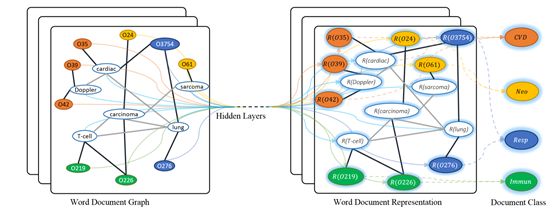
图1: TextGCN示意图。例子取自Ohsumed语料库。以“O”开头的节点是文档节点,其他节点是单词节点。黑色粗体边是文档和单词的边,灰色细边是单词和单词的边。R(x)表示x的表示(嵌入)。不同的颜色表示不同的文档类别(只显示了4个类别示例以避免混乱)。CVD:心血管疾病,Neo:肿瘤,Resp:呼吸道疾病,Immun:免疫性疾病。
一个两层的GCN可以允许信息在最多两阶节点之间传递。因此,尽管图中文档和文档没有直接的边,但是两层的GCN允许文档对之间的信息交换。在我们的初步实验中。我们发现,双层GCN的性能优于单层GCN,而多层GCN的性能并没有提高。这类似于(Kipf and Welling 2017) 和 (Li, Han, and Wu 2018)的结果。
实验
在本节中,我们在两个实验任务上评估了我们的文本图卷积网络(Text Graph Convolutional Networks, Text GCN)。具体来说,我们想确定:
即使标签数据有限,我们的模型在文本分类方面能否取得令人满意的结果?
我们的模型能够学习预测性单词和文档嵌入吗?
我们比较了我们的Text GCN与多种最先进的文本分类和嵌入方法如下:
TF-IDF + LR: 词袋模型,词频逆文档频率加权。采用Logistic回归作为分类器。
CNN: 卷积神经网络(Kim 2014)。我们研究了使用随机初始化词嵌入的CNN-rand和使用预先训练的词嵌入的CNN-non-static。
LSTM: (Liu, Qiu, and Huang 2016)定义的LSTM模型,使用最后一个隐藏状态作为整个文本的表示。我们还对模型进行了有/没有预先训练的词嵌入的实验。
Bi-LSTM: 一种双向的LSTM,通常用于文本分类。我们将预先训练好的词嵌入到Bi-LSTM中。
PV-DBOW: (Le and Mikolov 2014)提出的段落向量模型,忽略文本中单词的顺序。我们使用Logistic回归作为分类器。
PV-DM: 由(Le and Mikolov 2014)提出的考虑词序的段落向量模型。我们使用Logistic回归作为分类器。
PTE: 预测性文本嵌入(Tang, Qu, and Mei 2015),它首先学习基于包含单词、文档和标签为节点的异构文本网络的单词嵌入,然后将词嵌入平均值作为文档嵌入,用于文本分类。
fastText: 一种简单高效的文本分类方法(Joulin et al. 2017),它将word/n-gram嵌入量的平均值作为文档嵌入量,然后将文档嵌入量输入线性分类器。我们分别用和不用bigrams对它进行了评估。
SWEM: 简单的词嵌入模型(Shen et al. 2018),它使用简单的pooling策略对词嵌入进行操作。
LEAM: 标签嵌入的attentive模型(Wang et al. 2018),该模型将单词和标签嵌入到相同的联合空间进行文本分类。它使用标签描述。
Graph-CNN-C:一种使用Chebyshev filter的graph CNN模型,它对单词嵌入相似性图(Defferrard, Bresson Vandergheynst 2016)进行卷积。
Graph-CNN-S:与Graph-CNN-C相同,但使用Spline滤波器 (Bruna et al. 2014)。
Graph-CNN-F: 与Graph-CNN-C相同,但是使用了傅里叶滤波器(Henaff, Bruna, and LeCun 2015)。
数据集
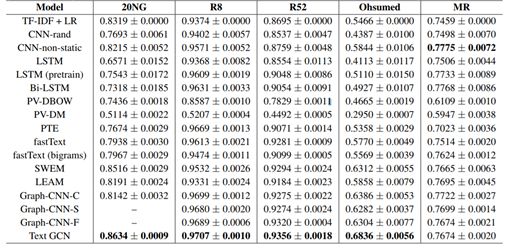
我们在五个广泛使用的基准语料库上进行了实验,包括路透社21578的20个新闻组(20NG)、Ohsum- ed、R52和R8以及电影评论(MR)。
20NG 数据集(bydate版本)包含18,846个文档,平均分为20个不同的类别。总共有11,314个文档在训练集中,7,532个文档在测试集中
Ohsumed 语料库来自MEDLINE数据库,这是一个由国家医学图书馆维护的重要医学文献书目数据库。在这项工作中,我们使用了13929个独特的心血管疾病摘要,在1991年的前20000个摘要。集合中的每个文档都有一个或多个与23个疾病类别相关的类别。由于我们侧重于单标签文本分类,所以排除了属于多个类别的文档,只保留了一个类别的7400个文档。培训集中有3357个文档,测试集中有4043个文档。
R52和R8 (通用版本)是Reuters 21578数据集的两个子集。R8有8类,分为5,485个培训文档和2,189个测试文档。R52有52个类别,分为6532个培训和2568个测试文档
MR 是一个电影评论的二元情绪分类数据集,每个评论只包含一个句子(Pang and Lee 2005)料库有5331条正面评论和5331条负面评论。我们使用(Tang,Qu, and Mei 2015)行训练/测试分割
我们首先通过清理和标记文本(Kim 2014)对所有数据集进行预处理。然后,我们删除了NLTK定义的停用词和20NG、R8、R52和Ohsumed中出现少于5次的低频字。唯一的例外是MR,我们在清理和标记原始文本后没有删除单词,因为文档非常短。表1总结了预处理数据集的统计数据。
表1: 数据集的汇总统计
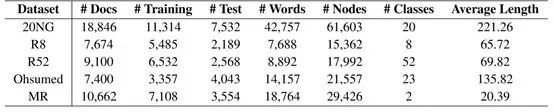
表2: 文档分类任务测试精度。我们运行所有模型10次,并得到均值±标准差。基于student t-test(p<0.05),TextGCN在20NG、R8、R52和Ohsumed上显著优于基准方法。
设置 对于Text GCN,我们设置第一个卷积层的嵌入大小为200,窗口大小为20。我们还对其他设置进行了实验,发现小的更改并不会对结果产生太大的影响。我们调整了其他参数,并将学习率设置为0.02,dropout为0.5,损失权重为0。我们随机选取训练集的10%作为验证集,在(Kipf and Welling 2017)之后,我们使用Adam (Kingma and Ba 2015)对文本GCN进行最多200个epoch的训练,如果验证损失连续10个epoch没有减少,则停止训练。对于基线模型,我们使用默认的参数设置,就像在它们最初的论文或实现中一样。对于使用预先训练好的单词嵌入的基准模型,我们使用了300维GloVe词嵌入(Pennington, Socher,and Manning 2014)
测试性能 表2给出了每个模型的测试精度。Text GCN在四个数据集上的性能最好,显著优于所有基准模型(基于student t-test, p < 0.05),说明了该方法在长文本数据集上的有效性。对于更深入的性能分析,我们注意到TF- IDF + LR在像20NG这样的长文本数据集上执行得很好,并且使用随机初始化的单词嵌入可以超过CNN。当预先训练的手套词嵌入提供,CNN表现得更好,特别是在Ohsumed和20NG。在短文本数据集MR上,利用预先训练好的词嵌入,CNN也获得了最好的结果,这表明它可以很好地对连续和短距离语义进行建模。同样,基于LSTM的模型也依赖于预先训练好的词嵌入,并且当文档较短时,模型的性能往往更好。PV-DBOW在20NG和Ohsumed上的结果与强基线相当,但在较短文本上的结果明显低于其他基准。这可能是因为单词顺序在短文本或情感分类中很重要。PV-DM的性能比PV-DBOW差,唯一可比较的结果是MR,在MR中单词顺序更重要。PV-DBOW和PV-DM的结果表明,无监督文档嵌入在文本分类中并没有很好的区分性。PTE和fastText明显优于PV-DBOW和PV-DM,因为它们以一种监督的方式学习文档嵌入,因此可以使用标签信息来学习更多有区别的嵌入。最近的两种方法SWEM和LEAM执行得很好,证明了简单的pooling方法和标签描述/嵌入的有效性。Graph-CNN模型也展示了具有竞争力的表现。这表明,利用预先训练好的词嵌入来构建词的相似度图,可以保持词之间的句法和语义关系,为大型外部文本数据提供额外的信息。
Text GCN运行良好的主要原因有两个方面:
1) 文本图可以同时捕捉文档和单词之间、全局的词与词之间的联系。
2) GCN模型作为拉普拉斯平滑的一种特殊形式,将节点的新特征计算为其自身及其二阶邻域的加权平均(Li, Han, and Wu 2018)。文档节点的标签信息可以传递给相邻的词节点(文档中的词),然后转发给其他词节点和第一阶邻域词节点的邻域文档节点。词节点可以收集全面的文档标签信息,在图中充当桥梁或关键路径,将标签信息传播到整个图中。然而,我们也观察到文本GCN在MR上并没有优于CNN和基于LSTM的模型,这是因为GCN忽略了在情绪分类中非常有用的语序,而CNN和LSTM则明确地对连续的单词序列进行建模。另一个原因是MR文本图的边数比其他文本图的边数少,这限制了节点之间的消息传递。因为文档非常短,文档只有很少的文档和字的边。由于滑动窗口的数量较少,单词-单词边的数量也受到限制。然而,CNN和LSTM依赖于来自外部语料库的预先训练好的单词嵌入,而Text GCN只使用目标输入语料库中的信息。
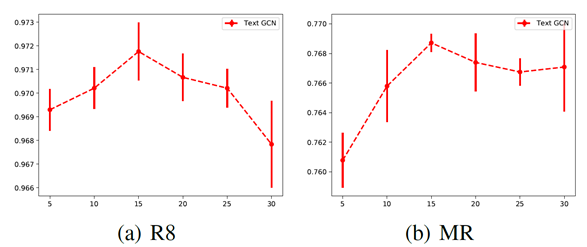
图2:测试不同滑动窗尺寸的精度
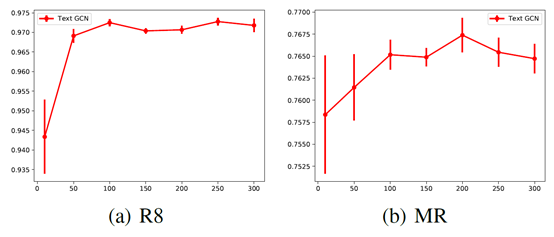
图3:通过改变嵌入尺寸测试精度
参数的敏感性 图2显示了R8和MR上不同滑动窗尺寸下的测试精度,我们可以看到,随着窗尺寸的增大,测试精度先增大,当窗尺寸大于15时,平均精度停止增大。这表明,窗口大小过小无法生成足够的全局字并发信息,而窗口大小过大可能会在不太相关的节点之间添加边缘。图3描述了R8和MR上的分类性能,不同维度的第一层嵌入。我们观察到类似的趋势,如图2所示。过低的维度嵌入可能不能很好地将标签信息传播到整个图中,而高维嵌入则不能提高分类性能,并且可能会花费更多的培训时间。
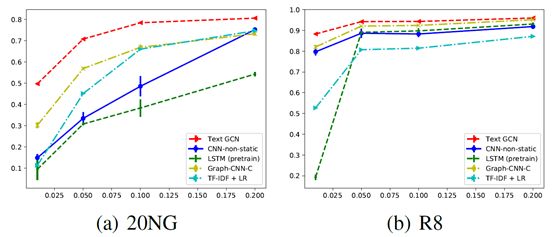
图4:不同训练数据比例的测试精度
标签数据大小的影响 为了评价标记数据大小的影响,我们用不同比例的训练数据测试了几种性能最好的模型。图4报告了原始的20NG和R8训练集的1%、5%、10%和20%的测试精度。我们注意到,文本GCN可以在有限的标注文档下实现更高的测试精度。例如,文本GCN在20NG上的测试精度为0.8063±0.0025,只有20%的训练文档;在R8上的测试精度为0.8830±0.0027,只有1%的训练文档,比一些即使是完整训练文档的基准模型都要高。这些令人鼓舞的结果与(Kipf and Welling 2017)的结果相似,GCN可以在低标签率下很好地执行,这再次表明GCN可以很好地将文档标签信息传播到整个图中,我们的单词-文档图保存了全局的单词共现信息。
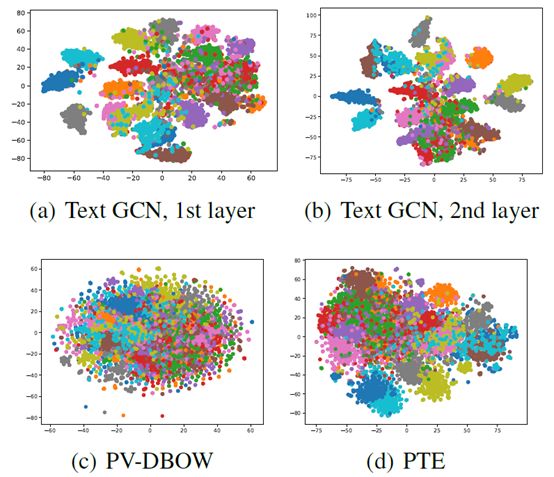
图5: 20NG中测试集文档嵌入的t-SNE可视化。
文档可视化 本文给出了文本GCN支持的文档嵌入的可视化演示。我们使用t-SNE工具(Maaten和Hinton2008)来可视化所学习的文档嵌入。图5显示了由GCN(第一层)、PV DBOW和PTE学习到的200维20NG测试文档嵌入的可视化,还显示了文本GCN的20维第二层测试文档嵌入。我们观察到文本GCN可以学习到更多有区别的文档嵌入,而第二层嵌入比第一层嵌入更容易区分。
表3: 20NG中几个类别最高值的单词。使用第二层词嵌入。
我们为每个类别展示前10个单词。
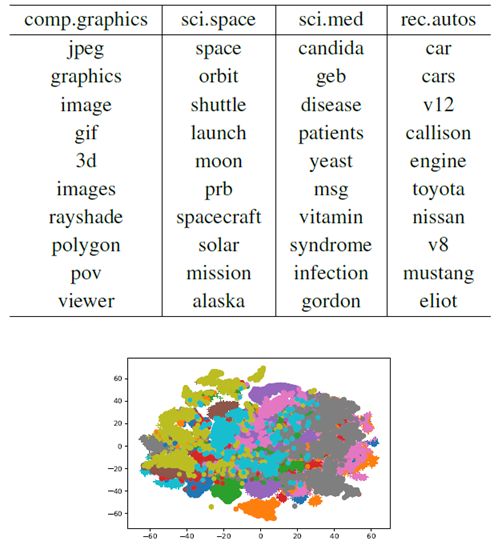
图6:从20NG中学习的第二层词嵌入(20维)的t-SNE可视化。
我们将值最大的维度设置为单词的标签。
单词可视化 我们也定性地形象化的用Text GCN学习词嵌入。图6显示了从20NG学到的第二层词嵌入的t-SNE可视化。我们将值最大的维度设置为单词的标签。我们可以看到具有相同标签的单词彼此很接近,这意味着大多数单词与某些特定的文档类密切相关。表3还显示了每个类别中值最高的前10个单词。我们注意到前10个单词是可解释的。例如,第1列中的“jpeg”、“graphics”和“image”可以表示它们的标签“comp.graphics”的含义。其他列中的单词也可以表示其标签的含义。
讨论 从实验结果可以看出,本文提出的Text GCN能够实现较强的文本分类结果,并能学习预测文档和单词嵌入。然而,本研究的一个主要限制是GCN模型本身具有转导性,其中测试文档节点(没有标签)包含在GCN训练中。因此,Text GCN不能快速生成嵌入并对不可见的测试文档进行预测。可能的解决方案是引入归纳(Hamilton,Ying, and Leskovec 2017)或快速GCN模型(Chen, Ma, andXiao 2018)。
总结与期望
本文提出了一种新的文本分类方法——文本图卷积网络(TextGraph Convolutional Networks, Text GCN)。我们为整个语料库构建了一个异构的单词-文档图,并将文档分类转化为一个节点分类问题。文本GCN能够很好地捕捉全局词的协同信息,利用有限的标记文档。一个简单的两层Text GCN在多个基准数据集上的性能优于许多最先进的方法,从而展示了有希望的结果。除了GCN模型归纳概括文本设置,一些有趣的未来的发展方向包括改善分类性能使用注意力机制(Veličkovićet al . 2018年)和发展无监督GCN大规模的框架表示学习文本标记文本数据。
原文
http://www.zhuanzhi.ai/paper/ca93a71ddf844f250ed3e84485d28080
【论文便捷下载】
请关注专知公众号(点击上方蓝色专知关注)
后台回复“GCNText” 就可以获取《基于图卷积网络的文本分类算法 》的下载链接~
-END-
专 · 知
专知《深度学习:算法到实战》课程全部完成!520+位同学在学习,现在报名,限时优惠!网易云课堂人工智能畅销榜首位!

欢迎微信扫一扫加入专知人工智能知识星球群,获取最新AI专业干货知识教程视频资料和与专家交流咨询!

请加专知小助手微信(扫一扫如下二维码添加),加入专知人工智能主题群,咨询《深度学习:算法到实战》课程,咨询技术商务合作~

请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

点击“阅读原文”,了解报名专知《深度学习:算法到实战》课程
展开全文



