LDA算法实现过程
四、LDA算法实现过程及代码
GibbsLDA算法的输入和输出(利用Gibbs Sampling算法推断LDA参数):
| LDA算法的输入与输出 |
|---|
| 算法输入: 分词后的文章集合(通常为一篇文章一行) 主题数K,超参数α和β |
| 算法输出: |
-
每篇文章的各个词被指定的主题编号:Tassign-model.txt
-
每篇文章的文档-主题分布θ:theta-model.txt
-
每个主题下的主题-词分布φ:phi-model.txt
-
程序中单词word的id映射表:wordMap.txt
-
每个主题下φ概率从高到低排序的top n特征词:twords.txt
GibbsLDA代码:
GibbsLDA.java (有最基础的GibbsLDA的代码和必要的注释)
这个代码很简单。
https://github.com/hankcs/LDA4j/blob/master/src/main/java/com/hankcs/lda/LdaGibbsSampler.java#L11
下图介绍GibbsLDA代码中实现LDA模型的Gibbs Sampling过程:
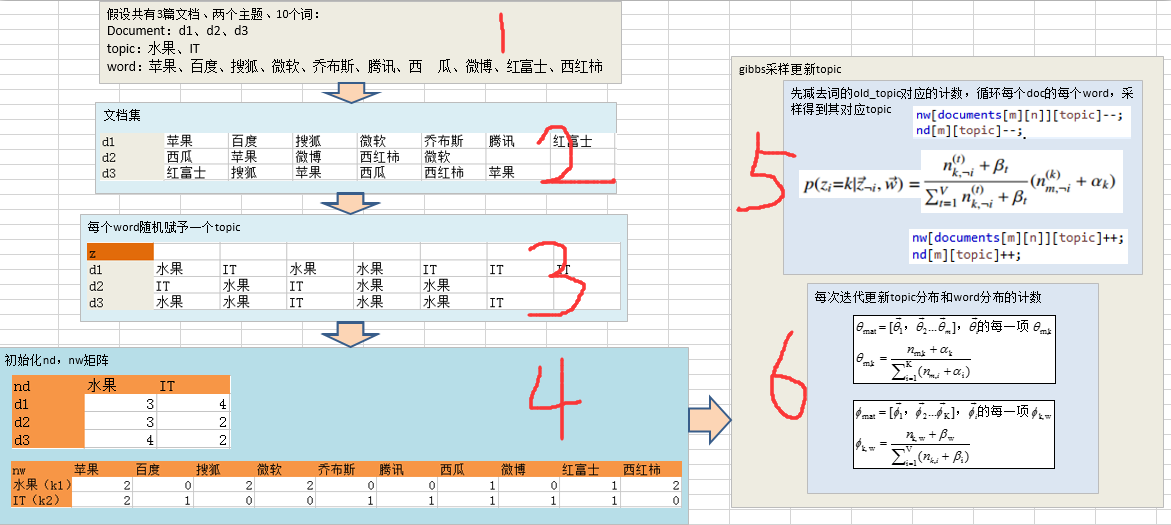
上图描述了java代码实现GibbsLDA的过程,示例过程如下:
-
第1步:首先假设共有三篇文档,两个主题,十个词;每个文档集 , , ;主题 , ;单词 , ,…, ;
-
第2步:将文档集中的每个文档 , , 中的所有单词进行统计处理,统计出其词频向量表示;
-
第3步:循环所有的文档,对于每个文档循环所有的单词,给每个单词随机赋值一个topic(从水果、IT两个topic中随机选择,最开始的随机赋予topic当然其中可能是不对的,但是经过后面的采样迭代逐渐达到平稳趋于正确)
-
第4步:对于第3步统计的文档中每个单词的topic,这一步将统计出两个分布θ和φ(即文档-主题分布和主题-词分布)。统计方法非常简单,可以理解为简单的计数。即对于3中的表格,在4中第一个表格每一行表示一个文档( , , ),每一列表示一个topic( , );第二个表格每一行表示主题( , ),每一列表示词( , ,…, );
-
第5步:利用Gibbs sampling更新每个单词的topic,包括三层循环:第一层是循环所有的文档,第二层是循环文档中的所有单词,第三层是求单词对应的所有topic的概率。利用求导的所有topic对应的概率,采样获得单词最可能取哪个topic(即最可能采样概率最大的那个topic)。过程如下面(摘自LDA算法漫游指南):
| Collasped Gibbs Sampling迭代阶段:(每一轮迭代有三重for循环)
- for iter in iter_number { //迭代iter_number次
-
- for (m, doc) in doc_set { //m是doc的编号
-
-
- for word in doc {
-
-
-
-
- t= 从z[m][n] 中取得当前word的主题编号(初始化来自随机)
令nw[word_id][t]、nwsum[t]、nd[m][t]三个统计量均减一(-1)
new double p[K]
- t= 从z[m][n] 中取得当前word的主题编号(初始化来自随机)
-
-
-
-
-
- for k in [0,1,2,…,K-1] { //从0到K-1个主题分别计算主题概率
-
-
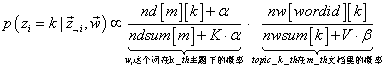
//按照上述公式生成单词对应的每个主题的概率,存放在数组p中
-
-
-
- }
-
-
-
-
- new_t = 从p数组中按照cumulative method算法采样一个topic
-
-
-
- 令nw[word_id][t]、nwsum[t]、nd[m][t]三个统计量均加一(+1)
-
-
-
- }
-
-
- }
- }
|
参考文章
-
马晨的LDA算法漫游指南—https://yuedu.baidu.com/ebook/d0b441a8ccbff121dd36839a.html
-
GibbsLDA代码—http://www.arbylon.net/projects/LdaGibbsSampler.java
-
GibbsLDA代码—https://github.com/hankcs/LDA4j/blob/master/src/main/java/com/hankcs/lda/LdaGibbsSampler.java
展开全文

