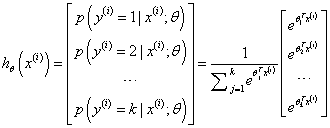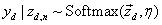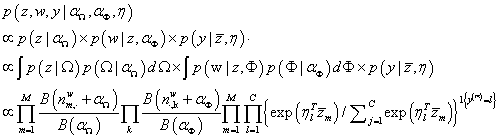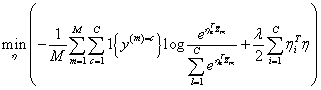1、SLDA
SLDA主题模型,主要思想是利用softmax分类器将文档类别标签信息,考虑到主题模型中,作为一个完整的模型进行训练,从而利用类别标签能很好的约束模型训练,能提高模型对于文本分类的分类性能。
Softmax分类器简介
**Logistic回归:**Logistic
Regression虽然名字里带“回归”,但是它实际上是一种分类方法,用于两分类问题(即输出只有两种)。根据第二章中的步骤,需要先找到一个预测函数(h),显然,该函数的输出必须是两个值(分别代表两个类别),所以利用了Logistic函数(或称为Sigmoid函数),函数形式为:
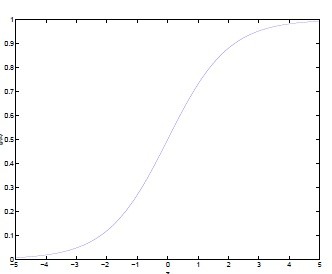
g(z)=1+e−z1
对应的函数图像是一个取值在0和1之间的S型曲线。
Softmax回归
softmax回归是逻辑斯蒂回归的推广,即,逻辑斯蒂回归只能区分两个类,softmax回归将它推广到了k个,经常放在各种神经网络的最顶层当作分类器。
回想一下在 logistic回归中,我们的训练集由
m个已标记的样本构成
{(x(1),y(1)),...,(x(m),y(m))}:,其中输入特征
x(i)∈ℜn+1。(我们对符号的约定如下:特征向量
x的维度为
n+1,其中
x0=1对应截距项) 由于 logistic 回归是针对二分类问题的,因此类标记
y(i)∈{0,1}。假设函数(hypothesis function) 如下:
hθ(x)=1+exp(−θTx)1
我们训练模型参数$\theta $,使其能够最小化代价函数 :
J(θ)=−m1[i=1∑my(i)loghθ(x(i))+(1−y(i))log(1−hθ(x(i)))]
在 softmax回归中,我们解决的是多分类问题(相对于 logistic回归解决的二分类问题),类标
y可以取
k个不同的值(而不是2个)。因此,对于训练集
{(x(1),y(1)),...,(x(m),y(m))},我们有
y(i)∈{1,2,...,k}。(注意此处的类别下标从1 开始,而不是 0)。例如,在 MNIST 数字识别任务中,我们有
k=10个不同的类别。
对于给定的测试输入
x,我们想用假设函数针对每一个类别j估算出概率值
p(y=j∣x)。也就是说,我们想估计
x的每一种分类结果出现的概率。因此,我们的假设函数将要输出一个
k维的向量(向量元素的和为1)来表示这
k个估计的概率值。
具体地说,我们的假设函数
hθ(x)形式如下:
其中
θ1,θ2,...,θk∈ℜn+1是模型的参数。请注意
∑j=1keθjTx(i)1这一项对概率分布进行归一化,使得所有概率之和为 1 。
详细内容请参考ufldl:
http://ufldl.stanford.edu/wiki/index.php/Softmax回归
SLDA(Supervised topic models)
SLDA(有监督主题模型)有很多扩展,包括Blei等人的“Supervised topic
models”,以及Labeled LDA,Disc LDA等。这里介绍一下Supervised topic
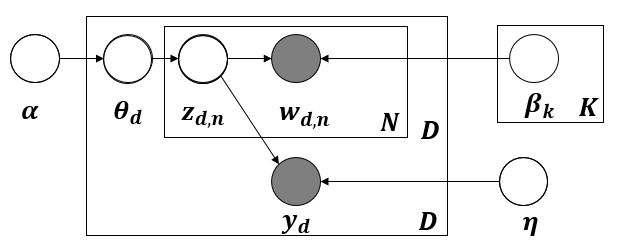
models,只介绍监督信息是离散的类标信息,开门见山,其图模型如下:
SLDA图模型生成过程:
-
对于每一个主题k:
-
从Dirichlet分布中获取文档-主题分布
θd:θd∣α∼Dir(α);
-
对于每个单词
wn:
-
首先从文档-主题分布中获取一个主题:
zn∣θ∼Mult(θ);
-
然后从对应的主题以及主题的主题-词分布中获取一个词:
wn∣zn,β1:K∼Mult(βzn)
-
获取单词类别标签:
y∣z1:N,η∼N(ηTz¯)
对于如何考虑单词的类别标签,作者在使用Softmax分类器,即:
该模型的参数估计方法有多种,这里参考论文中“Multi-Modal Supervised Latent Dirichlet Allocation for Event Classification in Social Media”的方法,给出求解过程:
首先写出联合后验分布
其中
B(α)=Γ(∑kαk)∏kΓ(αk)是归一化常数;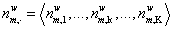 是文档m中属于主题k的单词的数目;
是文档m中属于主题k的单词的数目;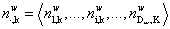 表示所有文档中,属于主题k的单词的数目;
表示所有文档中,属于主题k的单词的数目;
利用EM算法求解未知变量,在E-step利用Gibbs Sampling采样变量z,根据给定的参数
η1:C,在M-step通过最大化联合似然更新参数
η1:C(分类器)。
E-step:
利用collapsed Gibbs sampling采样当前词的topic,隐变量
zw,当前词分配主题k的概率公式为:
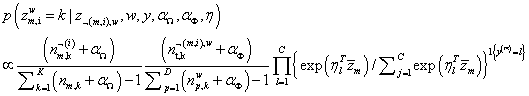
其中,
z¬(m,i),w表示文档-主题分布向量(除去当前位置i的词,只考虑文档m中其他维度的单词)。
∑k=1K(nm,k+αΩ)−1(nm,k¬(i)+αΩ)∑p=1D(np,kw+αΦ)−1(nt,k¬(m,i),w+αΦ)和传统的LDA类似,表示单词计数。
l=1∏C{exp(ηlTz¯m)/∑j=1Cexp(ηlTz¯m)}1{y(m)=l}考虑文档的类别信息,表示在当前分类器
η的条件下,当前词取主题k的概率。最终估计参数取值:
Φk,tw=∑p=1Dw(np,kw+αΦw)nt,kw+αΦw
Ωm,k=∑k=1K(nm,k+αΩ)nm,k+αΩ
M-step:
通过最大化联合概率分布,更新分类参数
η,固定E-step获取的参数,相当于最大化
p(y∣z¯,η),其中
z¯是文档的表示。问题转化为下面的优化问题:
参考文章
- sLDA—David M. Blei and Jon McAuliffe. Supervised topic models. In NIPS, 2007