【论文推荐】最新6篇生成式对抗网络(GAN)相关论文—半监督对抗学习、行人再识别、代表性特征、高分辨率深度卷积、自监督、超分辨
【导读】专知内容组整理了最近六篇生成式对抗网络(GAN)相关文章,为大家进行介绍,欢迎查看!
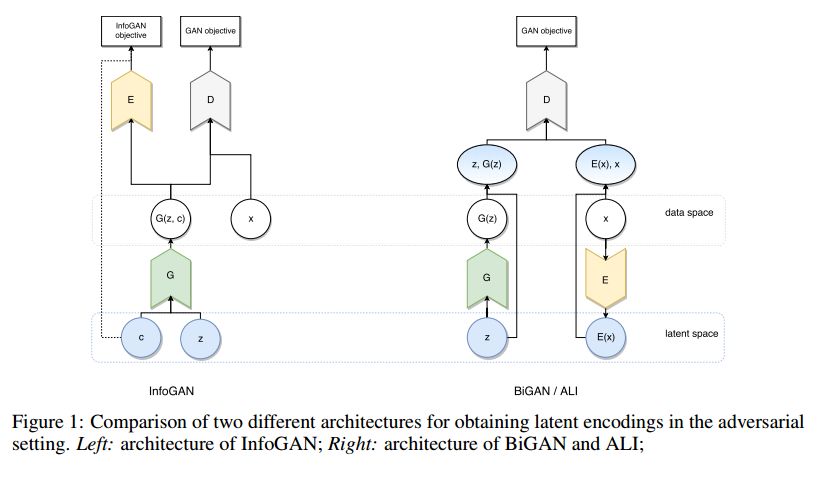
1. Classification of sparsely labeled spatio-temporal data through semi-supervised adversarial learning(基于半监督对抗学习的稀疏标记时空数据分类)
作者:Atanas Mirchev,Seyed-Ahmad Ahmadi
摘要:In recent years, Generative Adversarial Networks (GAN) have emerged as a powerful method for learning the mapping from noisy latent spaces to realistic data samples in high-dimensional space. So far, the development and application of GANs have been predominantly focused on spatial data such as images. In this project, we aim at modeling of spatio-temporal sensor data instead, i.e. dynamic data over time. The main goal is to encode temporal data into a global and low-dimensional latent vector that captures the dynamics of the spatio-temporal signal. To this end, we incorporate auto-regressive RNNs, Wasserstein GAN loss, spectral norm weight constraints and a semi-supervised learning scheme into InfoGAN, a method for retrieval of meaningful latents in adversarial learning. To demonstrate the modeling capability of our method, we encode full-body skeletal human motion from a large dataset representing 60 classes of daily activities, recorded in a multi-Kinect setup. Initial results indicate competitive classification performance of the learned latent representations, compared to direct CNN/RNN inference. In future work, we plan to apply this method on a related problem in the medical domain, i.e. on recovery of meaningful latents in gait analysis of patients with vertigo and balance disorders.
期刊:arXiv, 2018年1月29日
网址:
http://www.zhuanzhi.ai/document/173cd44a0bcc2b6ba4e35662bed64dc0
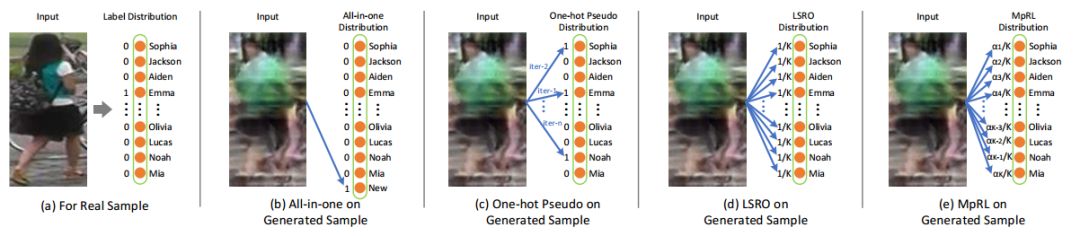
2. Multi-pseudo Regularized Label for Generated Samples in Person Re-Identification(基于多伪正则化标签生成样本的行人再识别)
作者:Yan Huang,Jinsong Xu,Qiang Wu,Zhedong Zheng,Zhaoxiang Zhang,Jian Zhang
摘要:Sufficient training data is normally required to train deeply learned models. However, the number of pedestrian images per ID in person re-identification (re-ID) datasets is usually limited, since manually annotations are required for multiple camera views. To produce more data for training deeply learned models, generative adversarial network (GAN) can be leveraged to generate samples for person re-ID. However, the samples generated by vanilla GAN usually do not have labels. So in this paper, we propose a virtual label called Multi-pseudo Regularized Label (MpRL) and assign it to the generated images. With MpRL, the generated samples will be used as supplementary of real training data to train a deep model in a semi-supervised learning fashion. Considering data bias between generated and real samples, MpRL utilizes different contributions from predefined training classes. The contribution-based virtual labels are automatically assigned to generated samples to reduce ambiguous prediction in training. Meanwhile, MpRL only relies on predefined training classes without using extra classes. Furthermore, to reduce over-fitting, a regularized manner is applied to MpRL to regularize the learning process. To verify the effectiveness of MpRL, two state-of-the-art convolutional neural networks (CNNs) are adopted in our experiments. Experiments demonstrate that by assigning MpRL to generated samples, we can further improve the person re-ID performance on three datasets i.e., Market-1501, DukeMTMCreID, and CUHK03. The proposed method obtains +6.29%, +6.30% and +5.58% improvements in rank-1 accuracy over a strong CNN baseline respectively, and outperforms the state-of-the- art methods.
期刊:arXiv, 2018年1月29日
网址:
http://www.zhuanzhi.ai/document/735fe58ab843f2fb02adb71bd0dcbbb7
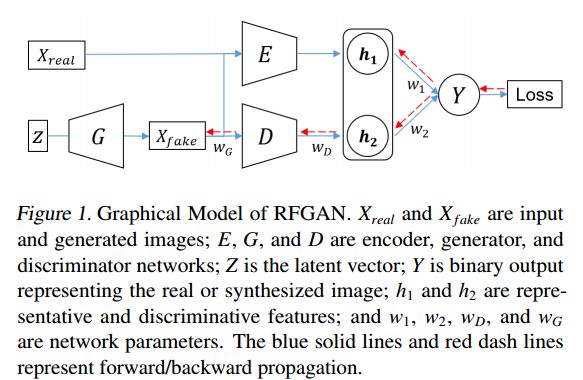
3. Improved Training of Generative Adversarial Networks Using Representative Features(利用代表性特征改进生成对抗网络的训练)
作者:Duhyeon Bang,Hyunjung Shim
摘要:Despite of the success of Generative Adversarial Networks (GANs) for image generation tasks, the trade-off between image diversity and visual quality are an well-known issue. Conventional techniques achieve either visual quality or image diversity; the improvement in one side is often the result of sacrificing the degradation in the other side. In this paper, we aim to achieve both simultaneously by improving the stability of training GANs. A key idea of the proposed approach is to implicitly regularizing the discriminator using a representative feature. For that, this representative feature is extracted from the data distribution, and then transferred to the discriminator for enforcing slow updates of the gradient. Consequently, the entire training process is stabilized because the learning curve of discriminator varies slowly. Based on extensive evaluation, we demonstrate that our approach improves the visual quality and diversity of state-of-the art GANs.
期刊:arXiv, 2018年1月28日
网址:
http://www.zhuanzhi.ai/document/6f89e2096d28f651d0de58bb66b89db9
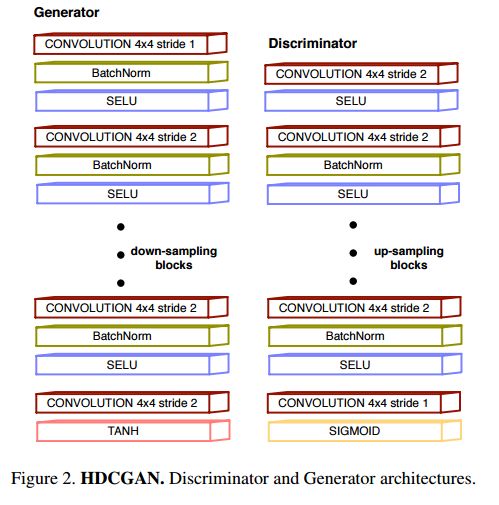
4. High-Resolution Deep Convolutional Generative Adversarial Networks(高分辨率深度卷积生成对抗网络)
作者:Joachim D. Curtó,Irene C. Zarza,Fernando De La Torre,Irwin King,Michael R. Lyu
摘要:Generative Adversarial Networks (GANs) convergence in a high-resolution setting with a computational constrain of GPU memory capacity (from 12GB to 24 GB) has been beset with difficulty due to the known lack of convergence rate stability. In order to boost network convergence of DCGAN (Deep Convolutional Generative Adversarial Networks) and achieve good-looking high-resolution results we propose a new layered network structure, HDCGAN, that incorporates current state-of-the-art techniques for this effect. A novel dataset, Curt\'o Zarza (CZ), containing human faces from different ethnical groups in a wide variety of illumination conditions and image resolutions is introduced. We conduct extensive experiments on CelebA and CZ.
期刊:arXiv, 2018年1月27日
网址:
http://www.zhuanzhi.ai/document/c0a9bdcf04b217c106d206f603f795db
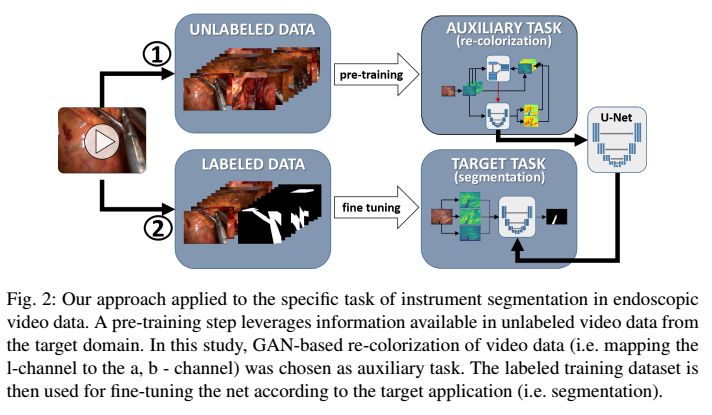
5. Exploiting the potential of unlabeled endoscopic video data with self-supervised learning(利用自监督学习探索无标签内窥镜视频数据的潜力)
作者:Tobias Ross,David Zimmerer,Anant Vemuri,Fabian Isensee,Sebastian Bodenstedt,Fabian Both,Philip Kessler,Martin Wagner,Beat Müller,Hannes Kenngott,Stefanie Speidel,Klaus Maier-Hein,Lena Maier-Hein
摘要:Surgical data science is a new research field that aims to observe all aspects and factors of the patient treatment process in order to provide the right assistance to the right person at the right time. Due to the breakthrough successes of deep learning-based solutions for automatic image annotation, the availability of reference annotations for algorithm training is becoming a major bottleneck in the field. The purpose of this paper was to investigate the concept of self-supervised learning to address this issue. Our approach is guided by the hypothesis that unlabeled video data can be used to learn a representation of the target domain that boosts the performance of state-of-the-art machine learning algorithms when used for pre-training. Essentially, this method involves an auxiliary task that requires training with unlabeled endoscopic video data from the target domain to initialize a convolutional neural network (CNN) for the target task. In this paper, we propose to undertake a re-colorization of medical images with generative adversarial network (GAN)-based architecture as an auxiliary task. A variant of the method involves a second pre-training step based on labeled data for the target task from a related domain. We have validated both variants using medical instrument segmentation as the target task. The proposed approach can be used to radically reduce the manual annotation effort involved in training CNNs. Compared to the baseline approach of generating annotated data from scratch, our method decreases exploratively the number of labeled images by up to 60% without sacrificing performance. Our method also outperforms alternative methods for CNN pre-training, such as pre-training on publicly available non-medical (COCO) or medical data (MICCAI endoscopic vision challenge 2017) using the target task (in this instance: segmentation).
期刊:arXiv, 2018年1月27日
网址:
http://www.zhuanzhi.ai/document/ab888b4fe829791fc8511ff647857ff9
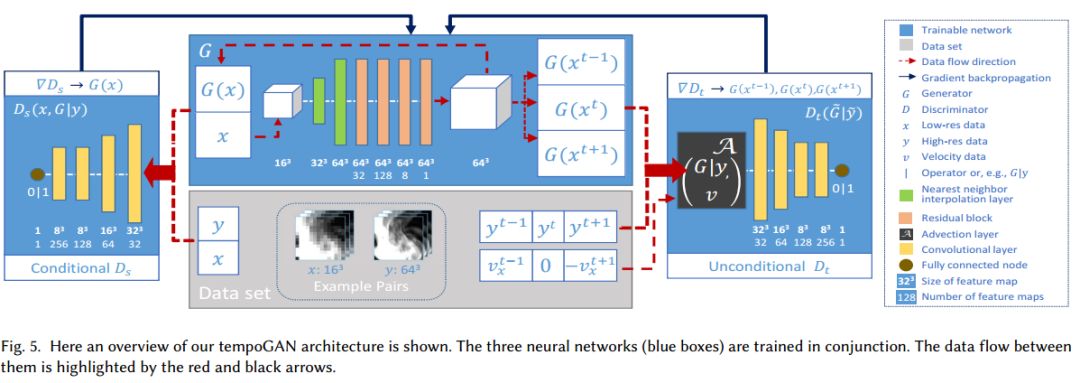
6. tempoGAN: A Temporally Coherent, Volumetric GAN for Super-resolution Fluid Flow(tempoGAN: 为超分辨流体流动的一种临时相干体)
作者:You Xie,Erik Franz,Mengyu Chu,Nils Thuerey
摘要:We propose a temporally coherent generative model addressing the super-resolution problem for fluid flows. Our work represents a first approach to synthesize four-dimensional physics fields with neural networks. Based on a conditional generative adversarial network that is designed for the inference of three-dimensional volumetric data, our model generates consistent and detailed results by using a novel temporal discriminator, in addition to the commonly used spatial one. Our experiments show that the generator is able to infer more realistic high-resolution details by using additional physical quantities, such as low-resolution velocities or vorticities. Besides improvements in the training process and in the generated outputs, these inputs offer means for artistic control as well. We additionally employ a physics-aware data augmentation step, which is crucial to avoid overfitting and to reduce memory requirements. In this way, our network learns to generate advected quantities with highly detailed, realistic, and temporally coherent features. Our method works instantaneously, using only a single time-step of low-resolution fluid data. We demonstrate the abilities of our method using a variety of complex inputs and applications in two and three dimensions.
期刊:arXiv, 2018年1月30日
网址:
http://www.zhuanzhi.ai/document/49f8d725491101012f6096785e5f26b3
-END-
专 · 知
人工智能领域主题知识资料查看获取:【专知荟萃】人工智能领域26个主题知识资料全集(入门/进阶/论文/综述/视频/专家等)
同时欢迎各位用户进行专知投稿,详情请点击:
【诚邀】专知诚挚邀请各位专业者加入AI创作者计划!了解使用专知!
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

请加专知小助手微信(Rancho_Fang),加入专知主题人工智能群交流!
点击“阅读原文”,使用专知!
展开全文



