【深度学习进阶模型详解】概率图模型/深度生成模型/深度强化学习,复旦邱锡鹏老师《神经网络与深度学习》教程分享05(附pdf下载)
点击上方“专知”关注获取专业AI知识!

【导读】复旦大学副教授、博士生导师、开源自然语言处理工具FudanNLP的主要开发者邱锡鹏(http://nlp.fudan.edu.cn/xpqiu/)老师撰写的《神经网络与深度学习》书册,是国内为数不多的深度学习中文基础教程之一,每一章都是干货,非常精炼。邱老师在今年中国中文信息学会《前沿技术讲习班》做了题为《深度学习基础》的精彩报告,报告非常精彩,深入浅出地介绍了神经网络与深度学习的一系列相关知识,基本上围绕着邱老师的《神经网络与深度学习》一书进行讲解。专知希望把如此精华知识资料分发给更多AI从业者,为此,专知特别联系了邱老师,获得他的授权同意分享。邱老师特意做了最新更新版本,非常感谢邱老师!专知内容组围绕邱老师的讲义slides,进行了解读,请大家查看,并多交流指正! 此外,请查看本文末尾,可下载最新神经网络与深度学习的slide。
邱老师的报告内容分为三个部分:
概述
机器学习概述
线性模型
应用
基础模型
前馈神经网络
卷积神经网络
循环神经网络
网络优化与正则化
应用
进阶模型
记忆力与注意力机制
无监督学习
概率图模型
深度生成模型
深度强化学习
模型独立的学习方式
【特此注明】本报告材料获邱锡鹏老师授权发布,由于笔者能力有限,本篇所有备注皆为专知内容组成员通过根据报告记录和PPT内容自行补全,不代表邱锡鹏老师本人的立场与观点。
邱老师个人主页: http://nlp.fudan.edu.cn/xpqiu/
课程Github主页:https://nndl.github.io/
神经网络与深度学习

深度学习模型往往在大型监督型数据集上训练。所谓监督型数据集,即每条数据都有一个对应的标签。比如流行的ImageNet数据集,有一百万张人为标记的图像。一共有1000个类,每个类有1000张图像。创建这样的数据集需要花费大量的精力,同时也需要很多的时间。现在想象创建一个有1M个类的数据集。试想一下,对有100M数据帧的视频数据集的每一帧进行分类。该任务量简直不可估量。
无监督学习的目标是兼容小数据集进行训练的通用系统,即便是很少的数据。
比较主流的无监督模型有:聚类学习、自动编码器、生成模型、PredNet
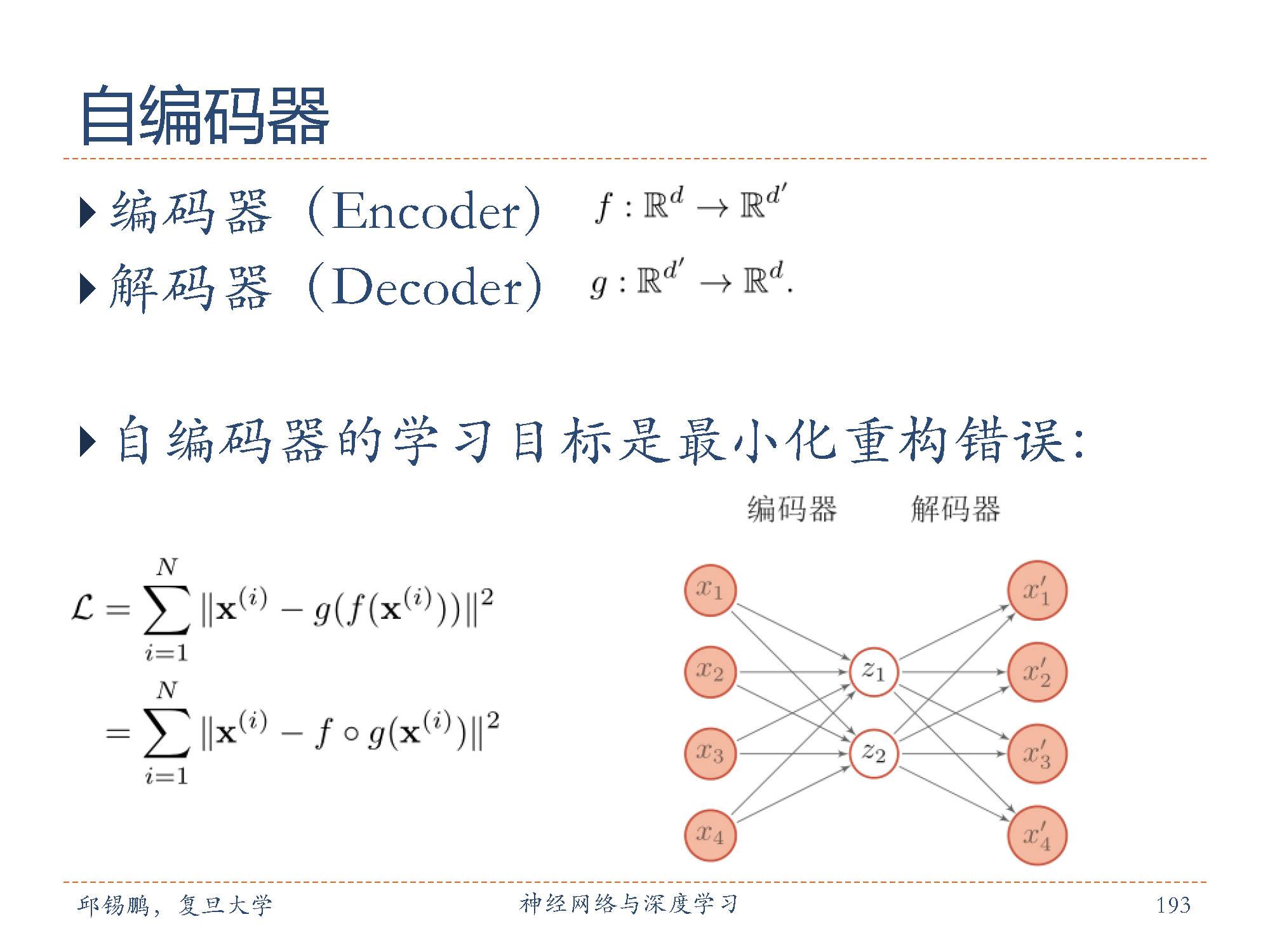
自编码器的目标是通过调整参数,使重构误差最小。
算法的大致思想是:将神经网络的隐含层看成是一个编码器和解码器,输入数据经过隐含层的编码和解码,到达输出层时,确保输出的结果尽量与输入数据保持一致。也就是说,隐含层是尽量保证输出数据等于输入数据的。 这样做的一个好处是,隐含层能够抓住输入数据的特点,使其特征保持不变。例如,假设输入层有100个神经元,隐含层只有50个神经元,输出层有100个神经元,通过自动编码器算法,我们只用隐含层的50个神经元就找到了100个输入层数据的特点,能够保证输出数据和输入数据大致一致,就大大降低了隐含层的维度。
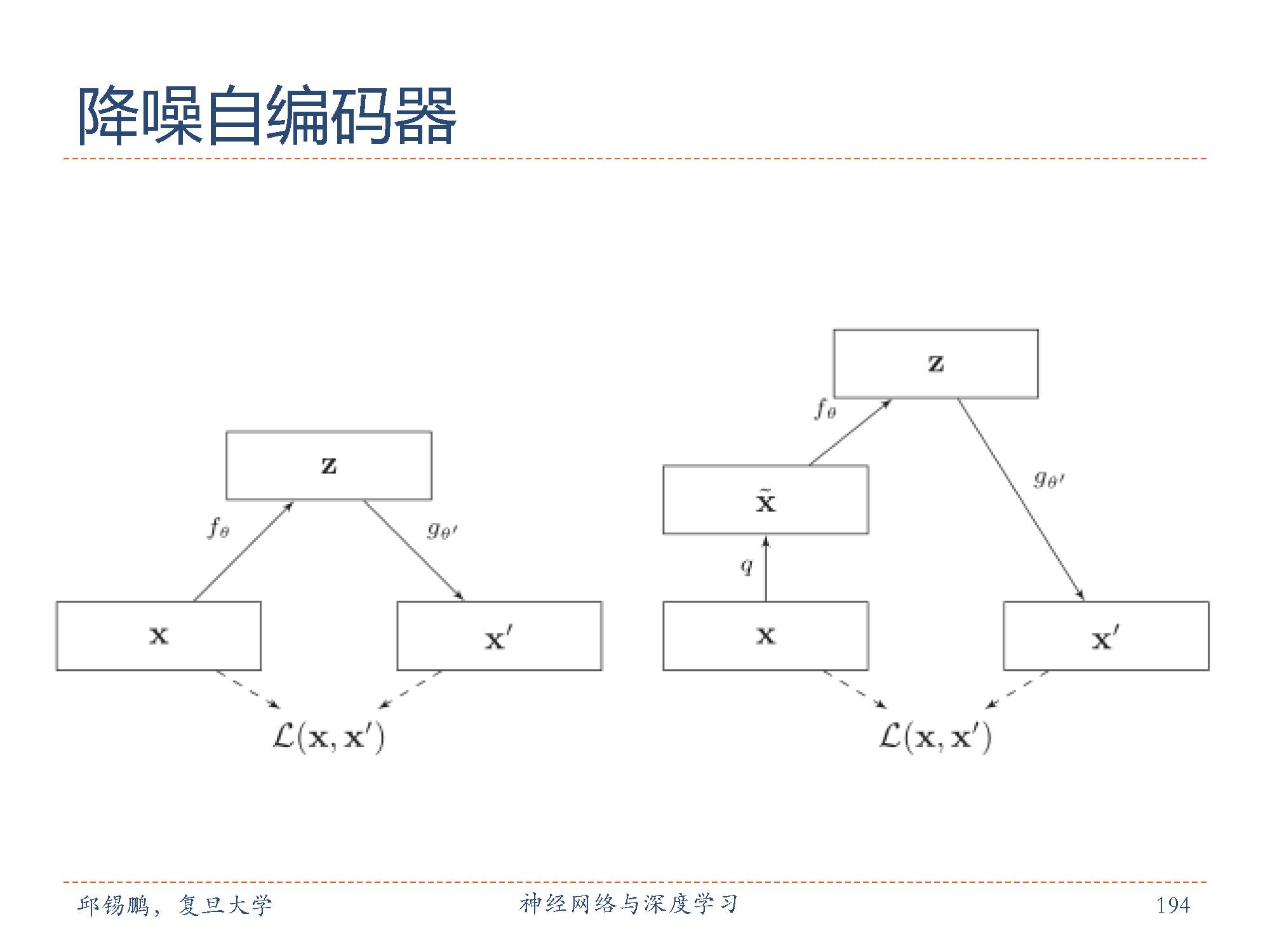
降噪自编码器目的是提取、编码出具有鲁棒性的特征怎么才能使特征很鲁棒呢?就是以一定概率分布(通常使用二项分布)去擦除原始input矩阵,即每个值都随机置0, 这样看起来部分数据的部分特征是丢失了。用这个丢失的数据去计算其他数,网络就学习了这个破损的数据。这个破损的数据是有用的,原因是:
一,通过与非破损数据训练的对比,破损数据训练出来的Weight噪声比较小。
二,破损数据一定程度上减轻了训练数据与测试数据的代沟。

在概率论和统计学中, 概率图模型( ProbabilisticGraphical Model, PGM),简称图模型( Graphical Model, GM),是指一种用图结构来描述多元随机变量之间条件独立关系的概率模型。
在机器学习中,图模型越来越多地用来设计和分析各种学习算法。很多机器学习模型都可以很作是概率模型(Probabilistic Model),将学习任务归结于计算输入和输出之间的条件概率分布。因此,图模型提供了一种新的角度来解释机器学习模型,并且这种角度有很多优点,比如了解不同机器学习模型之间的联系,方便设计新模型等。
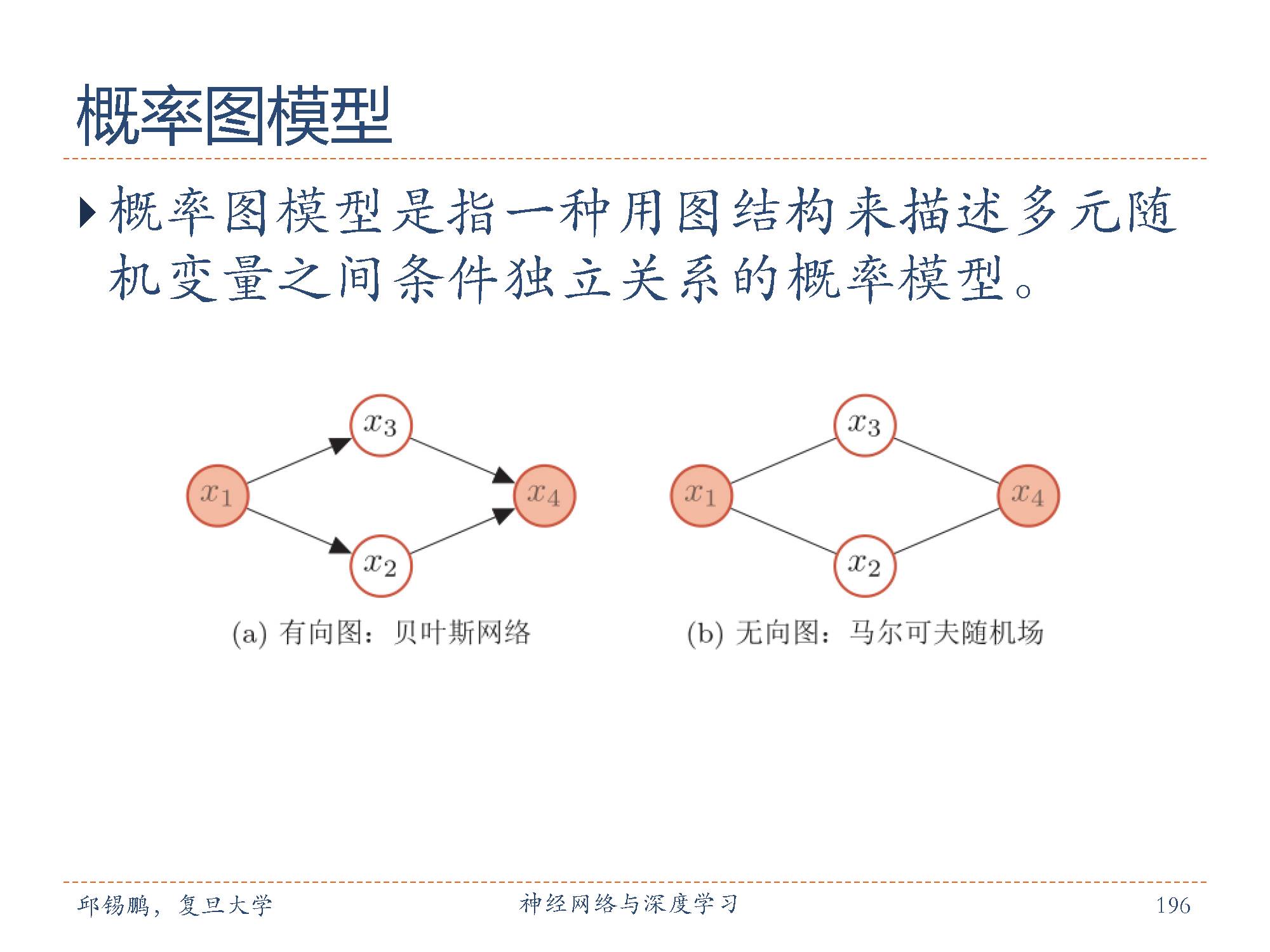
一个图由节点和节点之间的边组成。在概率图模型中,每一个节点都表示一个随机变量(或一组随机变量),边表示这些随机变量之间的概率依赖关系。有向图模型也叫做贝叶斯网络,为有向非循环图,边的方向代表了因果关系。无向图模型,也叫做马尔可夫随机场,每条边代表来两个变量之间有概率依赖关系,但是并不表明任何因果关系。对于一个非全连接的图模型,都可以根据条件独立性将联合概率分布进行因子分解,表示为一组局部的条件概率分布的乘积.
常见的概率图模型可以分为两类:有向图模型和无向图模型。图中给出了两个代表性图模型的例子:有向图和无向图,分别表示了其中四个变量之间的依赖关系。

贝叶斯网络具有局部马尔可夫性质:每个随机变量在给定父节点的情况下,条件独立于它的非后代节点。利用贝叶斯网络的局部马尔可夫性,我们可以对多元变量的联合概率进行简化,从而降低建模的复杂度。
利用上面图中有向图的例子,其联合概率图本图所示。
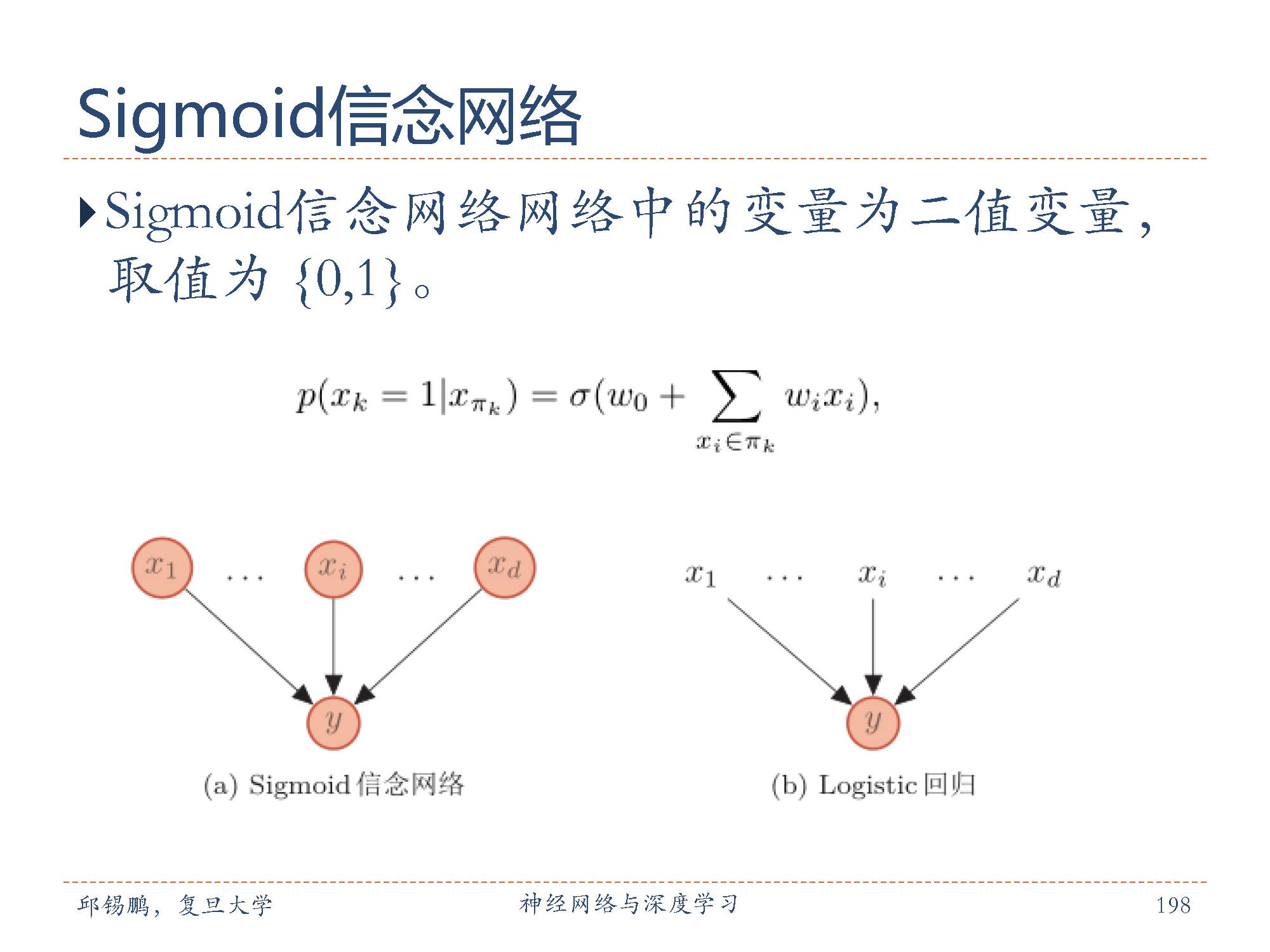
Sigmoid 信念网络与 Logistic 回归模型都采用logistic sigmoid函数来计算条件概率。如果将Sigmoid信念网络简化为只有一个叶子节点,其所有的父节点之间没有连接,且取值为实数,那么Sigmoid信念网络的网络结构和 logistic回归模型类似,这两个模型区别在于 logistic 回归模型中的 x 作为一种确定性的参数,而非变量,如图所示。
但是这两个模型的区别在于 logistic 回归模型中的 x 作为一种确定性的参数,而非变量。因此,logistic回归模型只建模条件概率 p(y|x),是一种判别模型;而 sigmoid信念网络建模 p(x, y),是一种生成模型。

图模型的几个要素包括:图结构、推断、参数学习。
在上面的篇幅中介绍了图结构,推断是指给定一组变量,在观测到部分变量时,计算其他变量的后验概率分布。
贝叶斯网络参数学习包括两部分:一是网络结构估计,估计每个条件概率分布的参数;二是寻找最优的网络结构。由于后者的优化一般比较困难,因此贝叶斯网络的结构一般是由领域专家来构建。在给定网络结构的条件下,网络的参数一般通过最大似然来进行估计。

在贝叶斯网络中,所有变量 x的联合概率分布可以分解为每个随机变量 xk的局部条件概率的连乘形式。如图中的公式所示,通过最大化x的对数似然,只需要分别最大化每个条件似然。如果x 中所有变量都是可观测的并且是离散的,只需要在训练集上统计每个变量的条件概率表即可。

马尔可夫随机场( MarkovRandom Fields),也叫无向图模型,或马尔可夫网络(Markov Network),是一类用无向图来表示一组具有马尔可夫性质的随机变量 X 的联合概率分布模型。
马尔可夫网络的联合分布可以表示如图所示。

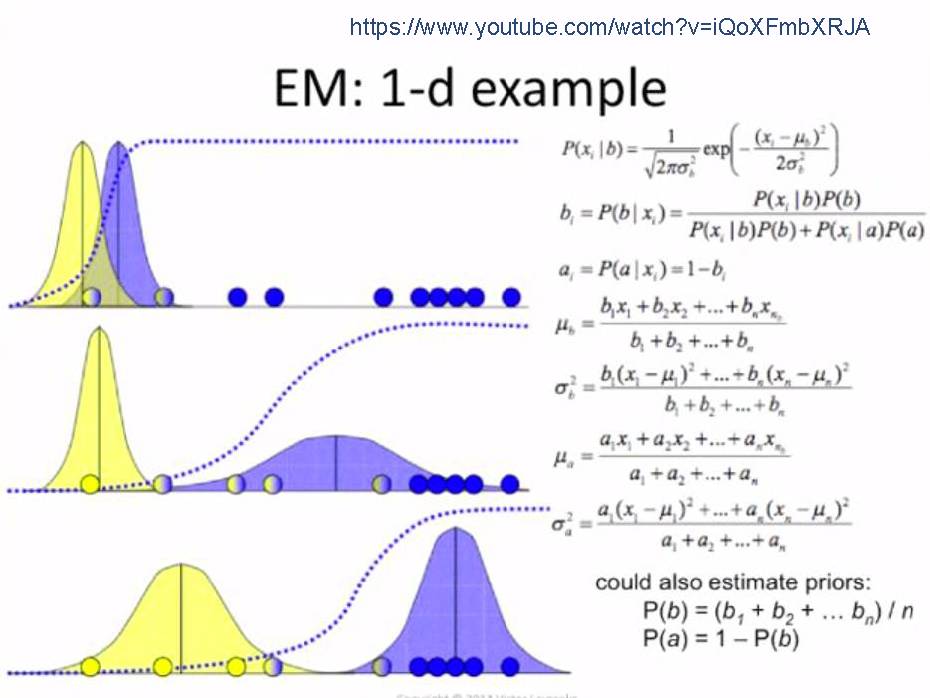
期望最大化(EM)算法是常用的含隐变量的参数估计方法,通过迭代的方法来最大化边际似然。将推断过程分解为两个步骤:先找到近似分布 q(z)使得l(θ; x) = L(q, θ; x),再寻找参数 θ 最大化 L(q, θ; x)。

参数估计方法中,如果有一组变量,有部分变量是是不可观测的如何进行参数估计呢?
我们知道通过最大化对数边际似然函数可以推断参数。EM算法具体的过程可以分为两步:
1. E步( Expectation):固定参数θ,找到一个分布q(z)使得 L(q, θ; x)最大。
2. M步( Maximization):固定 q(z),找到一组参数θ,使得 L(q, θ; x)最大。
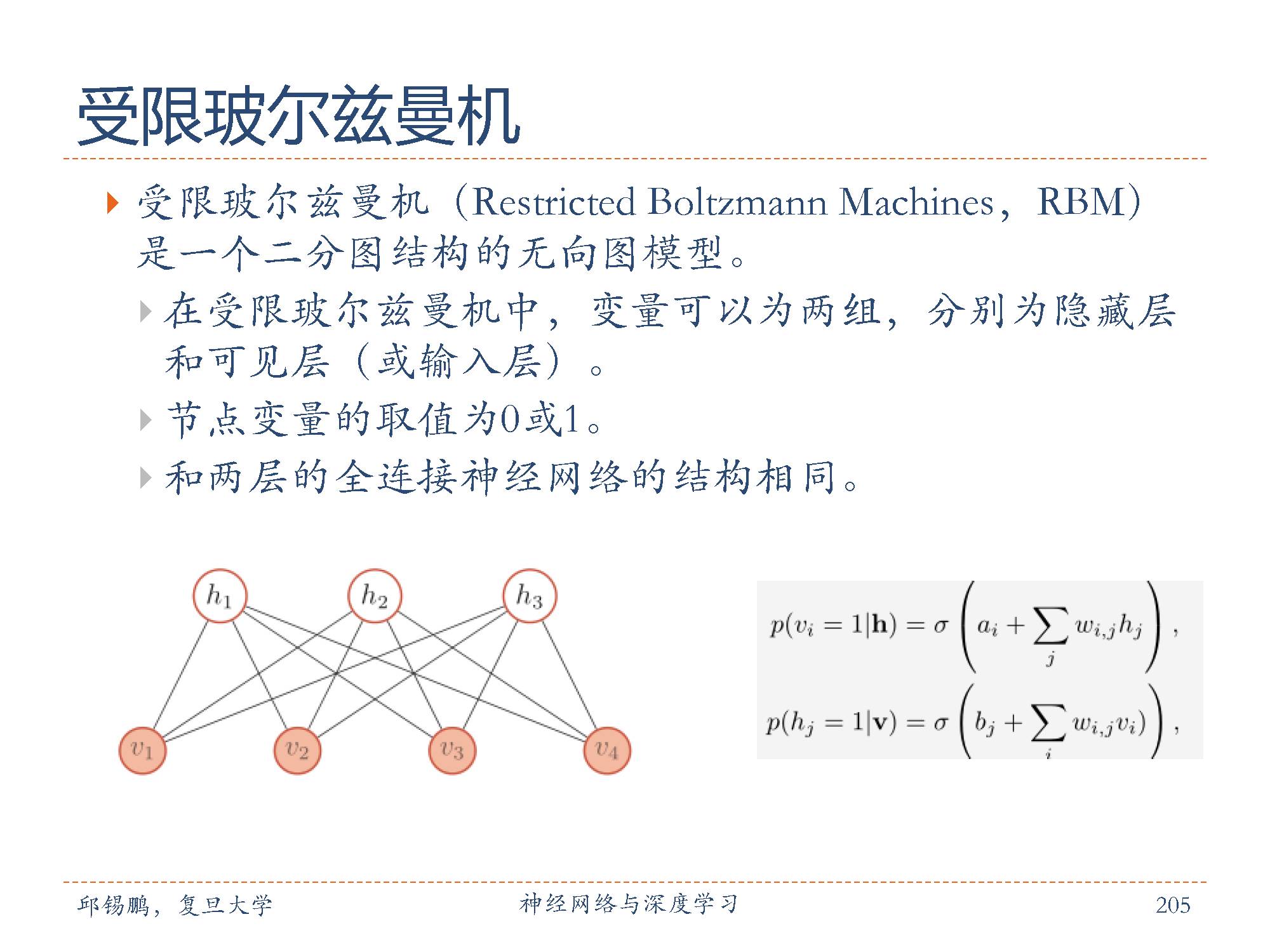
玻尔兹曼机( Boltzmann Machine)是一个特殊的概率无向图模型。受限玻尔兹曼机( Restricted Boltzmann Machines, RBM)是一个二分图结构的无向图模型,如图所示。
在受限玻尔兹曼机中,变量可以为两组,分别为隐藏层和可见层(或输入层)。同一层中的节点之间没有连接,一个层中的节点与另一层中的所有节点连接。节点变量的取值为0或1。
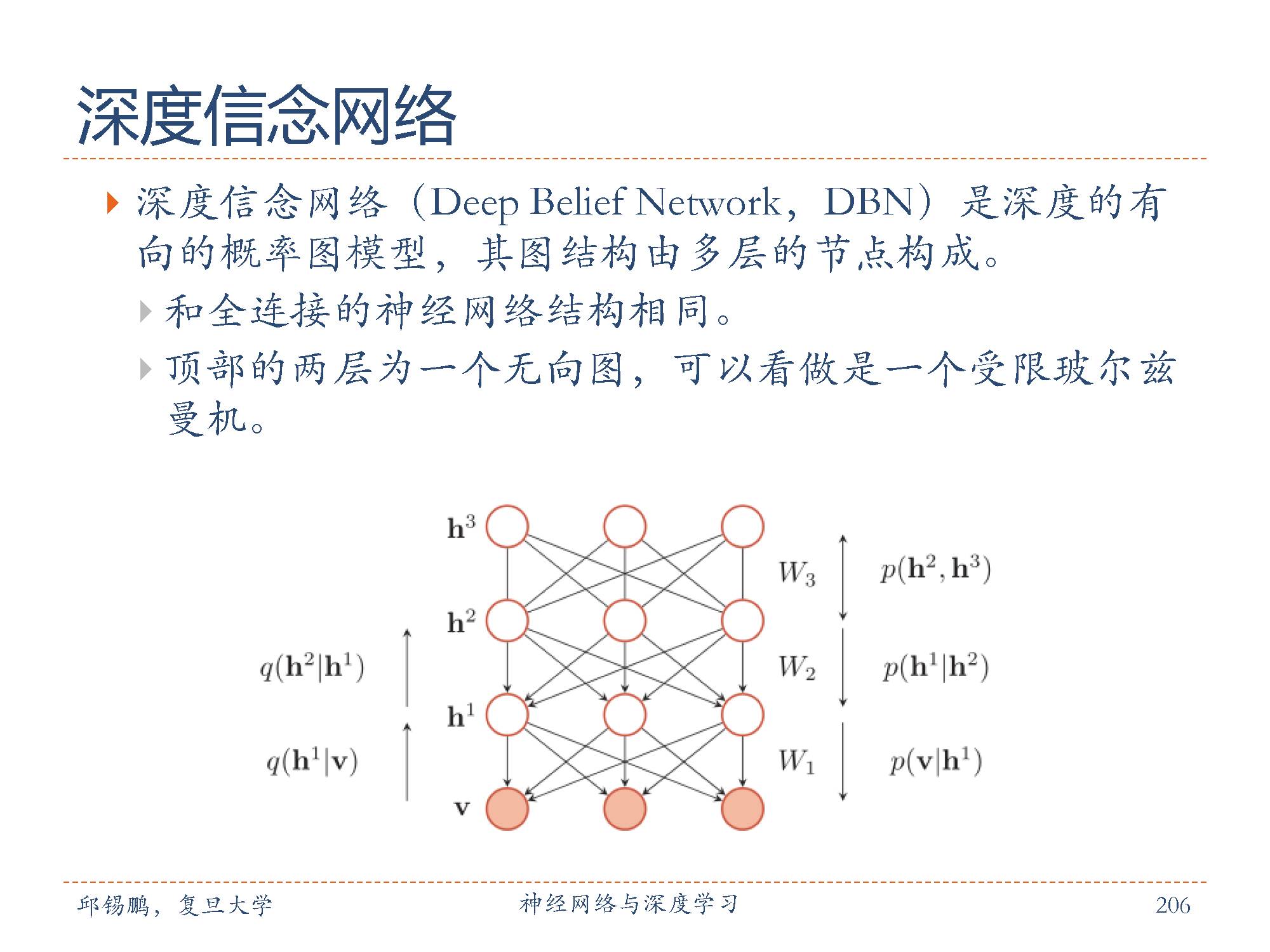
深度信念网络( DeepBelief Network,DBN)是深度的有向的概率图模型,其图结构由多层的节点构成。每层节点的内部没有连接,相邻两层的节点之间为全连接。网络的最底层为可见变量,其它层节点都为隐变量。最顶部的两层间的连接是无向的,其他层之间有连接上下的有向连接。如图所示。深度信念网络是一个生成模型,可以用来生成符合特定分布的样本。
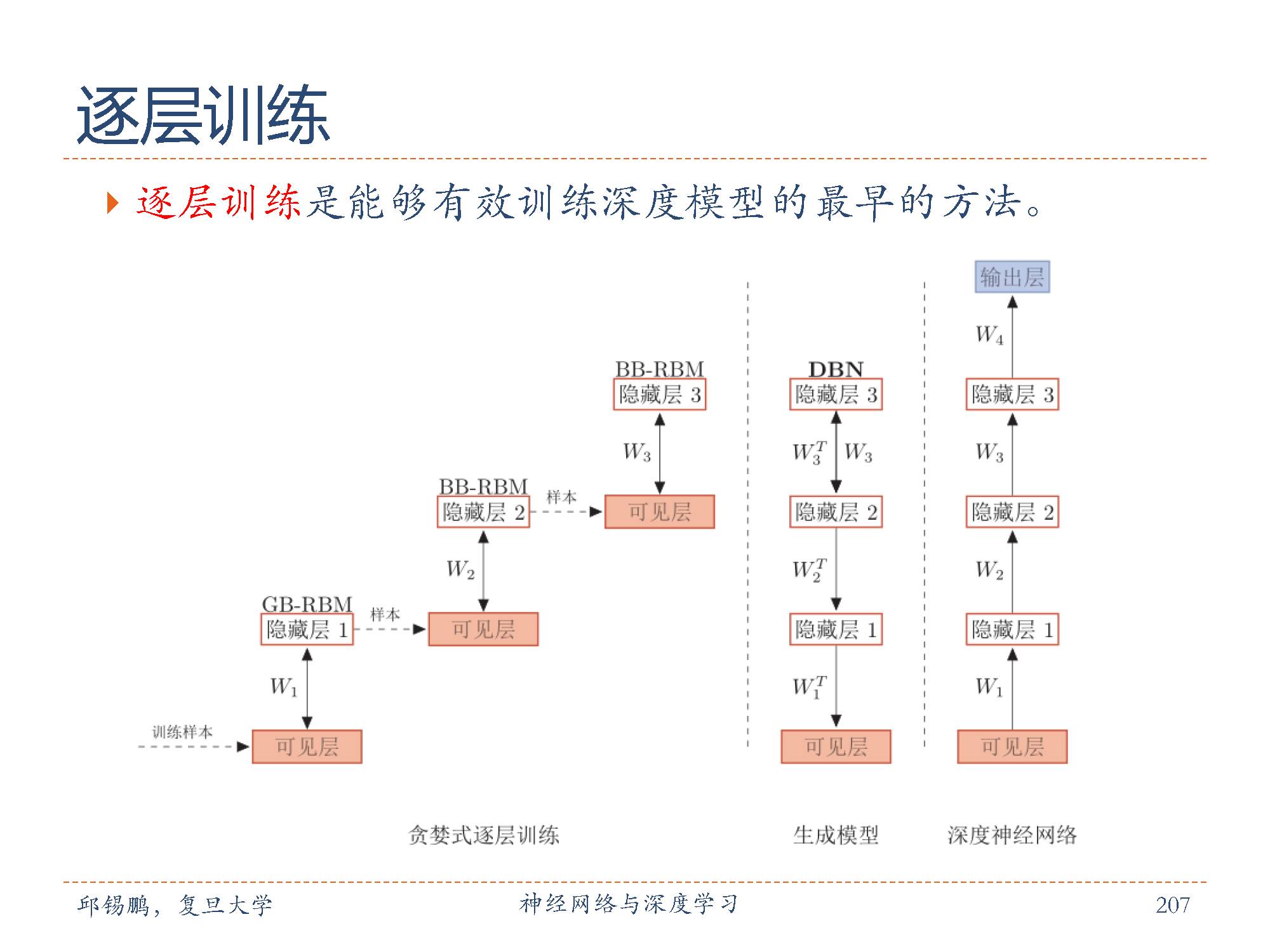
深度信念网络中,隐变量之间的关系十分复杂,由于“贡献度分配问题”,很难直接学习。为了有效地训练深度信念网络,我们将每一层的 sigmoid 信念网络转换为受限玻尔兹曼机。这样做的好处是隐变量的后验概率是相互独立的,从而可以很容易地进行采样。这样,深度信念网络可以看作是由多个受限玻尔兹曼机从下到上进行堆叠,每一层受限玻尔兹曼机的隐层作为上一层受限玻尔兹曼机的可见层。进一步地,深度信念网络可以采用逐层训练的方式来快速训练,即从最底层开始,每次只训练一层,直到最后一层。深度信念网络的训练过程可以分为预训练和精调两个阶段。先通过逐层预训练将模型的参数初始化为较优的值,再通过传统学习方法对参数进行精调。

图模型和神经网络的关系描述如下:
图模型和神经网络有着类似的网络结构,但两者也有很大的不同。图模型的节点是随机变量,其图结构的主要功能是用来描述变量之间的依赖关系,一般是稀疏连接。使用图模型的好处是可以有效进行统计推断。而神经网络中的节点是神经元,是一个计算节点。如果将神经网络中每个神经元看做是一个二值随机变量,那神经网络就变成一个sigmoid信念网络。
图模型中的每个变量一般有着明确的解释,变量之间依赖关系一般是人工来定义。而神经网络中的神经元则没有直观的解释。
图模型一般是生成模型,可以用生成样本,也可以通过贝叶斯公式用来做分类。而神经网络是判别模型,直接用来分类。
图模型的参数学习的目标函数为似然函数或条件似然函数,若包含隐变量则通常通过EM算法来求解。而神经网络参数学习的目标为交叉熵或平方误差等损失函数。

深度生成模型,就是利用神经网络来隐式地建模条件分布,并不对条件分布P(x|z)本身进行建模,而是建模生成过程,即学习一个映射函数g : Z → X。神经网络的输入为隐变量z,输出为观测变量x。
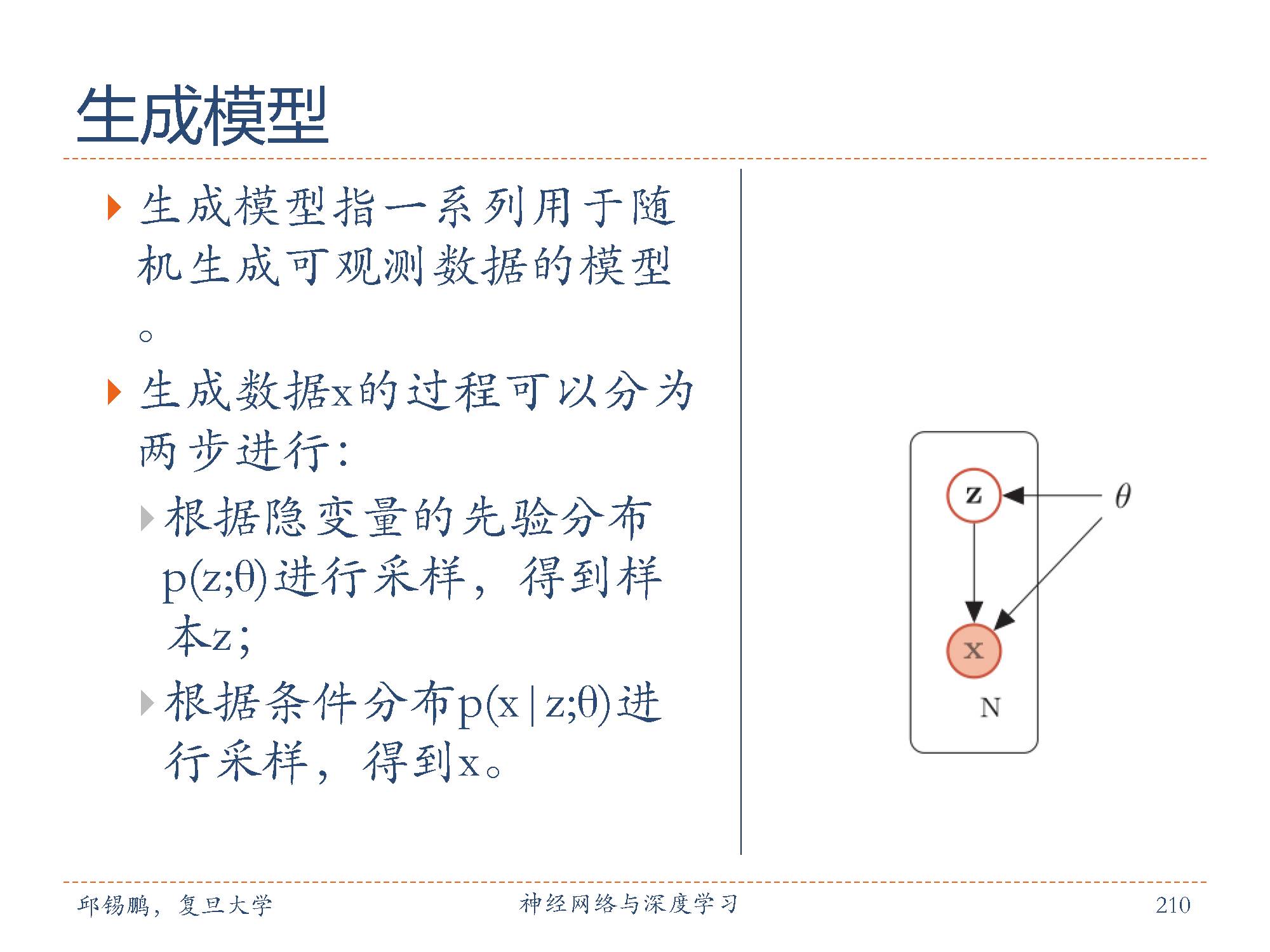
生成模型(Generative Model)是概率统计和机器学习中的一个概念,指一系列用于随机生成可观测数据的模型。生成模型有两个基本功能,一是学习一个概率分布,即密度估计问题,而是生成数据。
在机器学习中,生成模型是非常重要的模型,既可以用在无监督学习中,也可以用在有监督学习中。在无监督学习中,生成模型可以直接建模一些观测数据的概率密度函数。在有监督学习中,生成模型可以计算条件概率密度函数,作为计算类别后验概率的中间步骤,然后通过贝叶斯规则可以从生成模型中得到条件分布。
生成数据是生成模型的一个很重要的功能,比如生成图像、文本、声音等。自然图像就是可以看作是在连续高维空间中的样本,每一个像素点就是一个变量的一维。不同像素之间存在某种未知的依赖关系,比如一些相邻的像素点的颜色一般是相似的。通过建立一个图像生成模型,可以来生成一些逼真的自然图像。同样,自然语言可以看作是在离散高维空间中的样本。一个句子中每一个词可以看出一维离散变量,不同词之间也存在一个的语法或语义约束关系。

深度生成模型就是利用神经网络来建模条件分布p(x|z;θ),并不对分布本身进行建模,而是建模生成过程。
变分自编码器(VariationalAutoencoder, VAE)是一种深度生成模型。其思想是利用神经网络来分别建模(1)生成模型p(x|z;θ);(2)后验概率分布和变分近似分布。
对抗生成式网络(GenerativeAdversarial Network, GAN)也是一种深度生成模型。GAN启发自博弈论中的二人零和博弈。这个模型的优化过程是一个“二元极小极大博弈(minimax two-player game)”问题,训练时固定一方,更新另一个模型的参数,交替迭代,使得对方的错误最大化,最终,G 能估测出样本数据的分布。
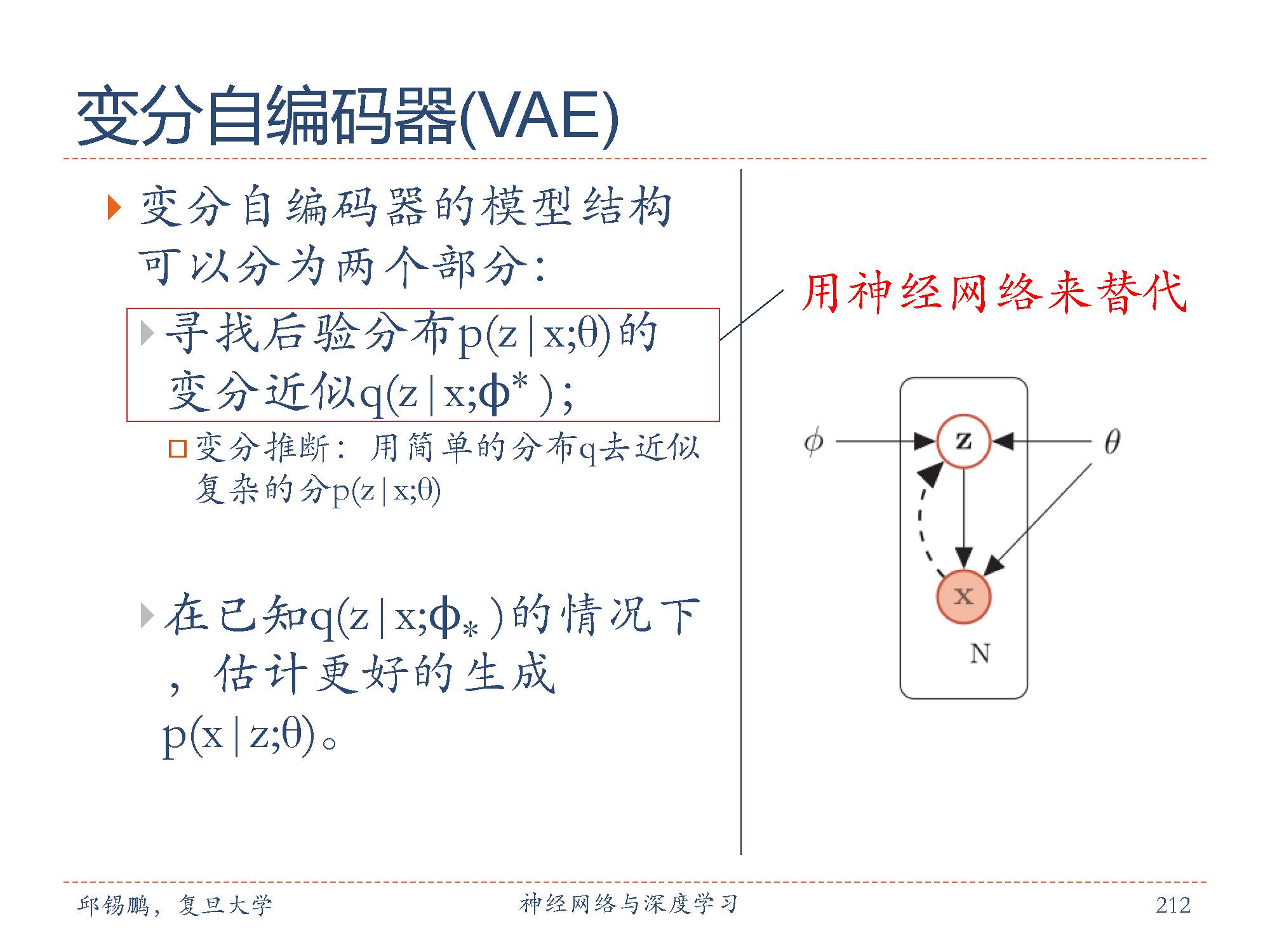
变分自编码器的模型结构可以分为两个部分:
1. 寻找后验分布p(z|x;θ)的变分近似q(z|x;ϕ∗ );
2. 在已知q(z|x;ϕ∗ )的情况下,估计更好的生成p(x|z;θ)。
如图所示,实线表示生成模型,虚线表示变分近似。
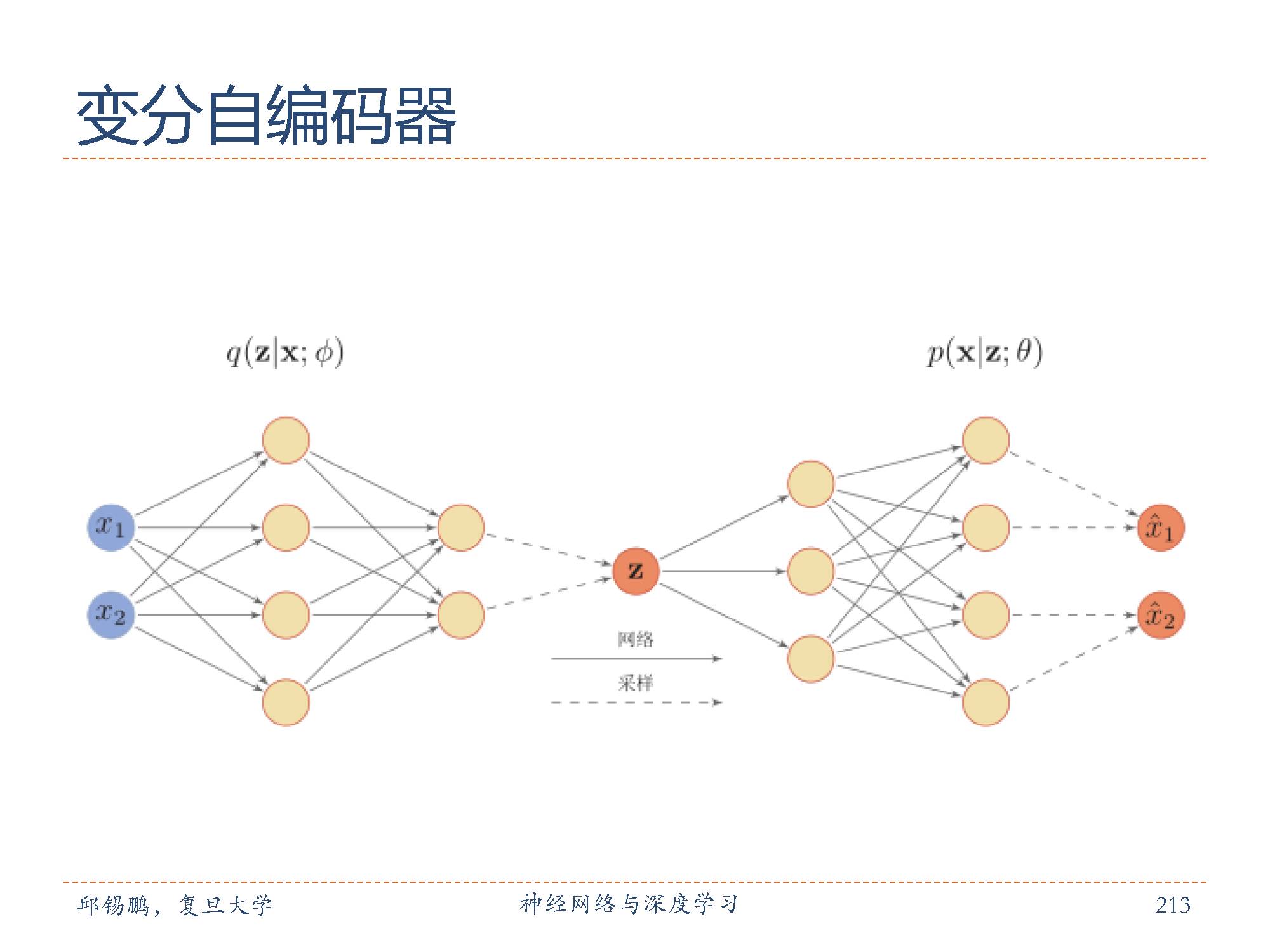
变分自编码器可以看作神经网络和贝叶斯网络的混合体。贝叶斯网络中的节点可以看成是一个随机变量。在变分自编码器中,我们仅仅将隐藏编码对应的节点看成是随机变量,其它节点还是作为普通神经元。这样,编码器变成一个变分推理网络,而解码器可以看作是将隐变量映射到观测变量的生成网络。
图中给出了变分自编码器的神经网络结构示例。
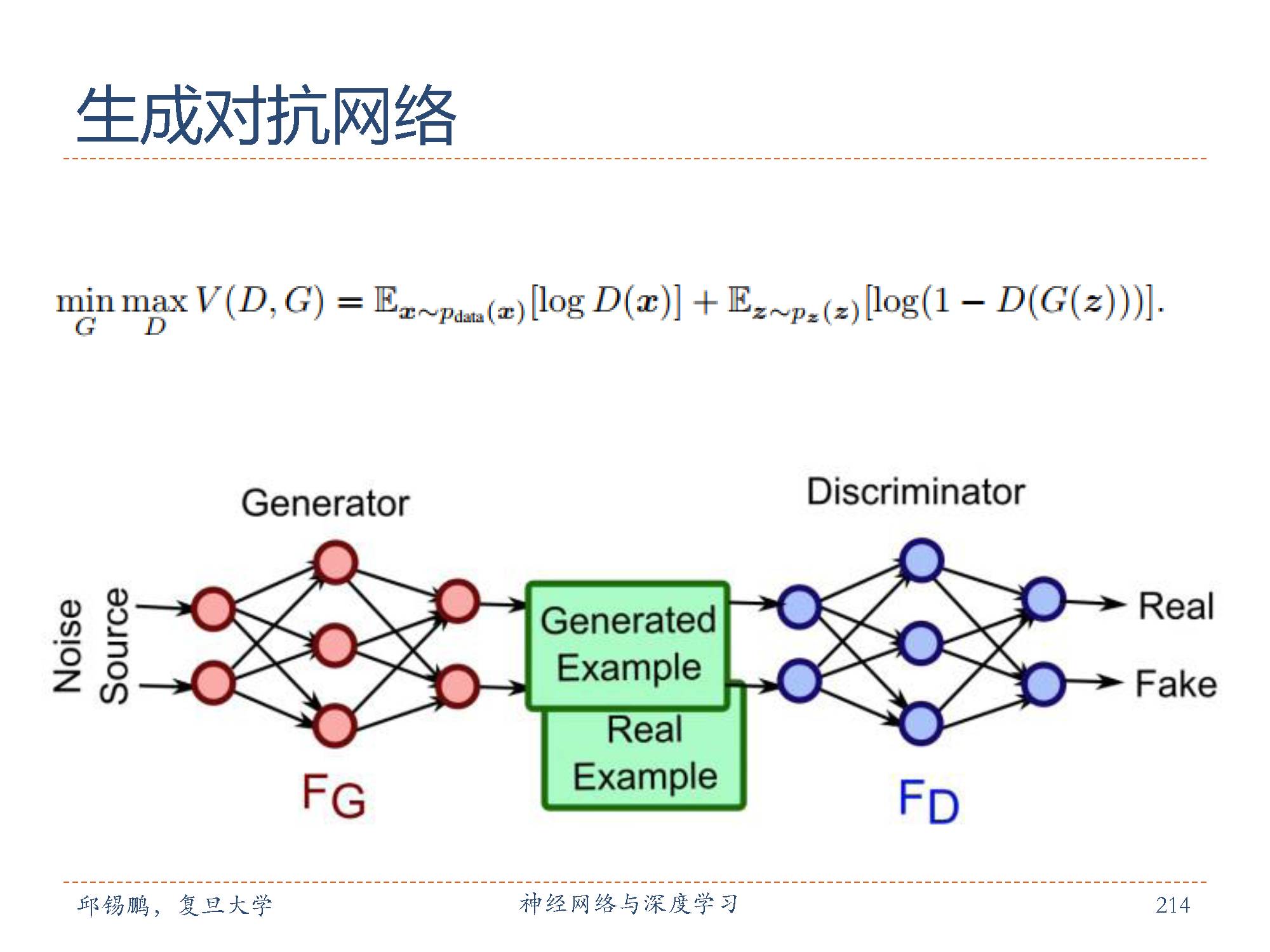
前面介绍了生成对抗网络的基本思想,假设有一种概率分布M,它相对于我们是一个黑盒子。为了了解这个黑盒子中的东西是什么,我们构建了两个东西G和D,G是另一种我们完全知道的概率分布,D用来区分一个事件是由黑盒子中那个不知道的东西产生的还是由我们自己设的G产生的。
不断的调整G和D,直到D不能把事件区分出来为止。在调整过程中,需要:优化G,使它尽可能的让D混淆。 优化D,使它尽可能的能区分出假冒的东西。
当D无法区分出事件的来源的时候,可以认为,G和M是一样的。从而,我们就了解到了黑盒子中的东西。
上述描述的公式化表示,如图中的公式所示。公式中D(x)表示x属于分布M的概率,因而,优化D的时候就是让V(D,G)最大,优化G的时候就是让V(D,G)最小。

生成对抗网络可以应用在minst手写数字数据集和人脸数据集中进行分类实验。

深度强化学习概念:
深度强化学习( Deep Reinforcement Learning)是将强化学习和深度学习结合在一起,用强化学习来定义问题和优化目标,用深度学习来解决状态表示、策略表示等问题。深度强化学习在一定程度上具备解决复杂问题的通用智能,并在很多任务上都取得了很大的成功。
强化学习概念:
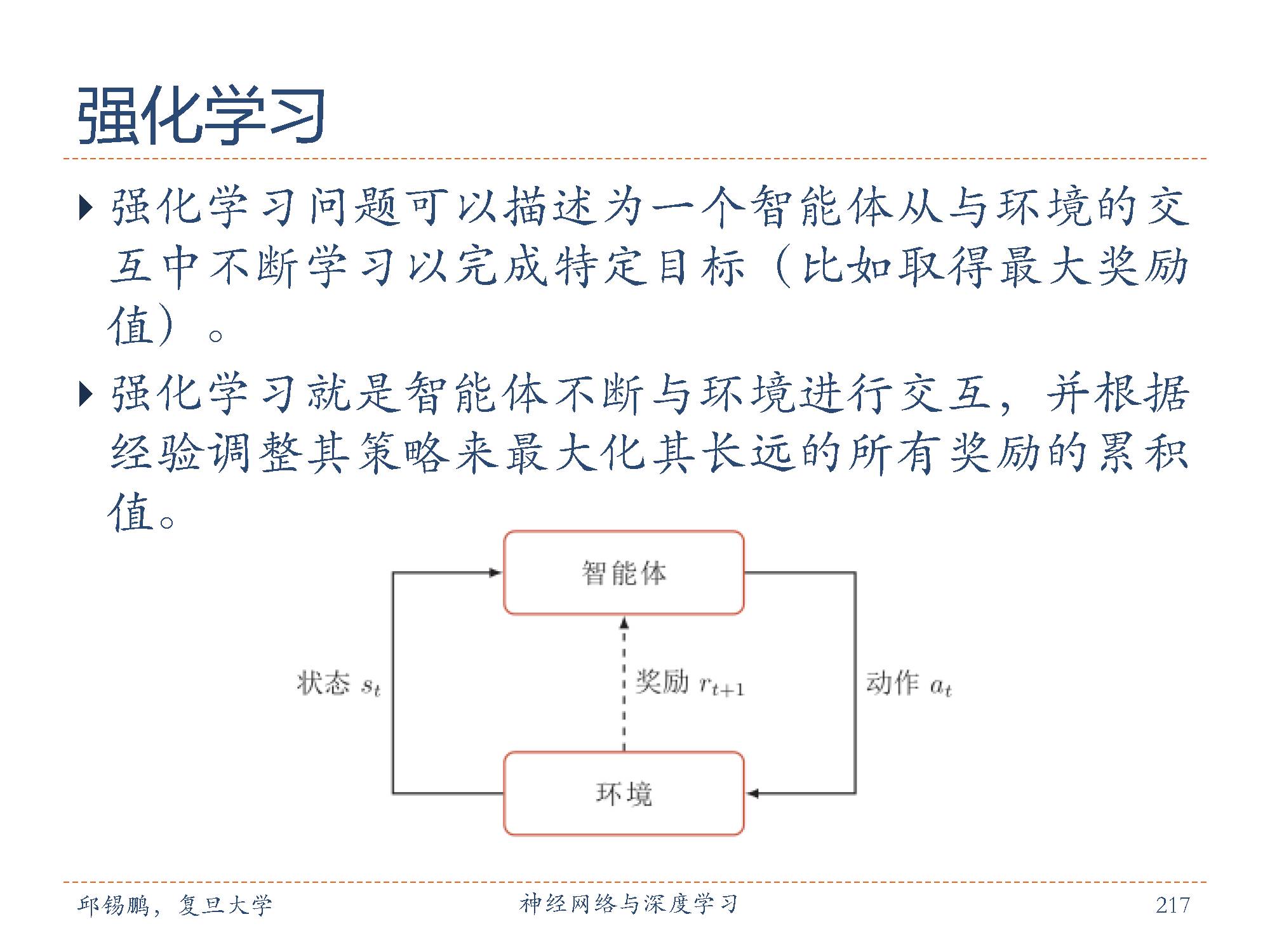
强化学习( Reinforcement Learning, RL),也叫增强学习,是指一类从(与环境)交互中不断学习的问题以及解决这类问题的方法。强化学习问题可以描述为一个智能体从与环境的交互中不断学习以完成特定目标(比如取得最大奖励值)。强化学习就是智能体不断与环境进行交互,并根据经验调整其策略来最大化其长远的所有奖励的累积值。和深度学习类似,强化学习中的关键问题也是贡献度分配问题 [Minsky, 1963],每一个动作并不能直接得到监督信息,需要通过整个模型的最终监督信息(奖励)得到,并且有一定的延时性。

在强化学习中,有两个可以进行交互的对象:智能体和环境。
智能体( Agent)可以感知外界环境的状态( State)和奖励反馈( Reward),并进行学习和决策。智能体的决策功能是指根据外界环境的状态来做出不同的动作( Action),而学习功能是指根据外界环境的奖励来调整策略。
环境( Environment)是智能体外部的所有事物,并受智能体动作的影响而改变其状态,并反馈给智能体相应的奖励。

如图所示,强化学习中的基本要素包括:
环境的状态集合: S;
智能体的动作集合: A;
状态转移概率: p(s′|s, a),即智能体根据当前状态s做出一个动作 a之后,
下一个时刻环境处于不同状态 s′ 的概率;即时奖励: R : S × A × S → R,即智能体根据当前状态做出一个动作之
后,环境会反馈给智能体一个奖励,这个奖励和动作之后下一个时刻的状
态有关。

什么是马尔科夫过程?
马尔可夫过程( Markov Process)是指随时间变动的变量 s0, s1, · · · , st ∈ S,其过程具有马尔可夫性,即下一个时刻的状态只取决于当前状态。
什么是值函数?
从状态s开始,执行策略π得到的期望总回报,如图中的第二个公式所示。

给定一个策略 π,从状态 s开始,执行策略 π,我们可以得到一个动作和状态的序列。因为策略和状态转移都有一定的随机性,每次试验的序列都可以不一样,其收获的总回报也不一样。那么,从状态s开始,执行策略 π 得到的期望总回报公式如图所示,该公式即为状态值函数的公式。

状态-动作值函数:
为了更方便优化策略,我们需要知道在状态s时,哪个动作会导致其总回报最大。因此,我们定义一个状态-动作值函数( State-ActionValue Function)。即初始状态为s,并执行动作 a 后的所能得到的期望总回报。
最优策略:
如果存在一个最优的策略 π∗,其在所有状态上的期望回报最大,我们就称π∗为最优策略。
如图中公式所示,最优策略 π∗对应的值函数称为最优值函数。

强化学习的目的求解马尔可夫决策过程 (MDP)的最优策略。从贝尔曼最优方程可知,求解最优的策略需要知道马尔可夫决策过程的状态转移概率和奖励。也就是说模型已知,我们直接可以通过贝尔曼最优方程来迭代计算最优策略。
基于模型的强化学习:
我们把模型已知时的强化学习算法,都称为基于模型的强化学习( Modelbased Reinforcement Learning)算法。常用的基于模型的强化学习算法主要有策略迭代算法和值迭代算法。
模型无关的强化学习:
在很多应用场景中,马尔可夫决策过程的状态转移概率和奖励函数都是未知的。在这种情况下,我们一般需要智能体和环境进行交互,并收集一些样本。然后再根据这些样本来求解马尔可夫决策过程最优策略。这样模型未知,基于采样的学习算法都称为模型无关的强化学习( Model-freeReinforcementLearning)算法。常用的模型无关的强化学习算法主要有蒙特卡罗采样和时序差分学习两种方法。

深度强化学习( Deep Reinforcement Learning)是将强化学习和深度学习结合在一起,用强化学习来定义问题和优化目标,用深度学习来解决状态表示、策略表示等问题。深度强化学习在一定程度上具备解决复杂问题的通用智能,并在很多任务上都取得了很大的成功。
有三种不同的结合强化学习和深度学习的方式,分别用深度神经网络来建模强化学习中的值函数、策略、 模型,然后用误差反向传播算法来优化目标函数。

为了在连续的状态和动作空间中计算值函数 Qπ(s, a),我们可以用一个函数Qθ(s, a)来表示近计算,称为值函数近似( ValueFunction Approximation)
其中, s和 a 分别是状态s和动作a的向量表示;函数Qθ(s, a)为深度神经网络,参数为θ,输出为一个实数,称为Q网络( Q-Network)。
如图中的公式所示,如果动作为有限离散的m个动作a1, · · · , am,我们可以让 Q网络输出一个m维向量,其中每一维用Qθ(s, ai)来表示,对应值函数Q(s, ai)的近似值。我们通过近似值函数逼近值函数。

深度 Q网络采取两个措施:一是目标网络冻结( FreezingTarget Networks),即在一个时间段内固定目标中的参数,来稳定学习目标;二是经验回放 (Experience Replay),构建一个经验池来去除数据相关性。经验池由智能体最近的经历组成的数据集。
深度 Q网络的学习过程如图所示。

基于策略函数的深度强化学习:
我们之前提到的策略优化都要依赖值函数,对于确定性策略,可以直接用深度神经网络来表示一个参数化的从状态空间到动作空间的映射函数:a = πθ(s),其中 s 为状态 s 的向量表示, θ 为参数。对于随机性策略,可以让深度神经网络的输出为一个分布:πθ(a|s)。
假设从状态s开始,执行策略πθ(a|s),得到的轨迹为s0 = s, a0, r1, s1, a2, · · · ,记为 τ,其总回报记为 G(τ)。因为最优的策略是使得在每个状态的总回报最大的策略,因此策略搜索的目标函数如图公式。

策略搜索:
我们可以使用一种直接对策略进行参数化的方法,称为策略搜索( Policy Search)。和基于值函数的方法相比,策略搜索可以不需要值函数,直接优化策略。此外,参数化的策略能够处理连续状态和动作,可以直接学出随机性策略。
策略梯度:
策略搜索是通过寻找参数 θ 使得目标函数 L(s; θ) 最大。目标函数关于 θ 的梯度如图所示。在公式中,期望可以通过采样的方法来近似。对当前策略πθ,可以随机游走采集多个轨迹,对于每一个轨迹,计算总回报G(τ),再乘以轨迹概率对参数θ的导数然后再计算平均。这种方法就叫做策略梯度( PolicyGradient)。

未来研究方向

未来研究方向,主要有非监督学习、自然语言理解和推理、其他结构的网络、优化问题等,更多研究方向如图所示。
其他的不知道了

这里邱老师也推荐了一些深度学习和神经网络的课程,如图所示。
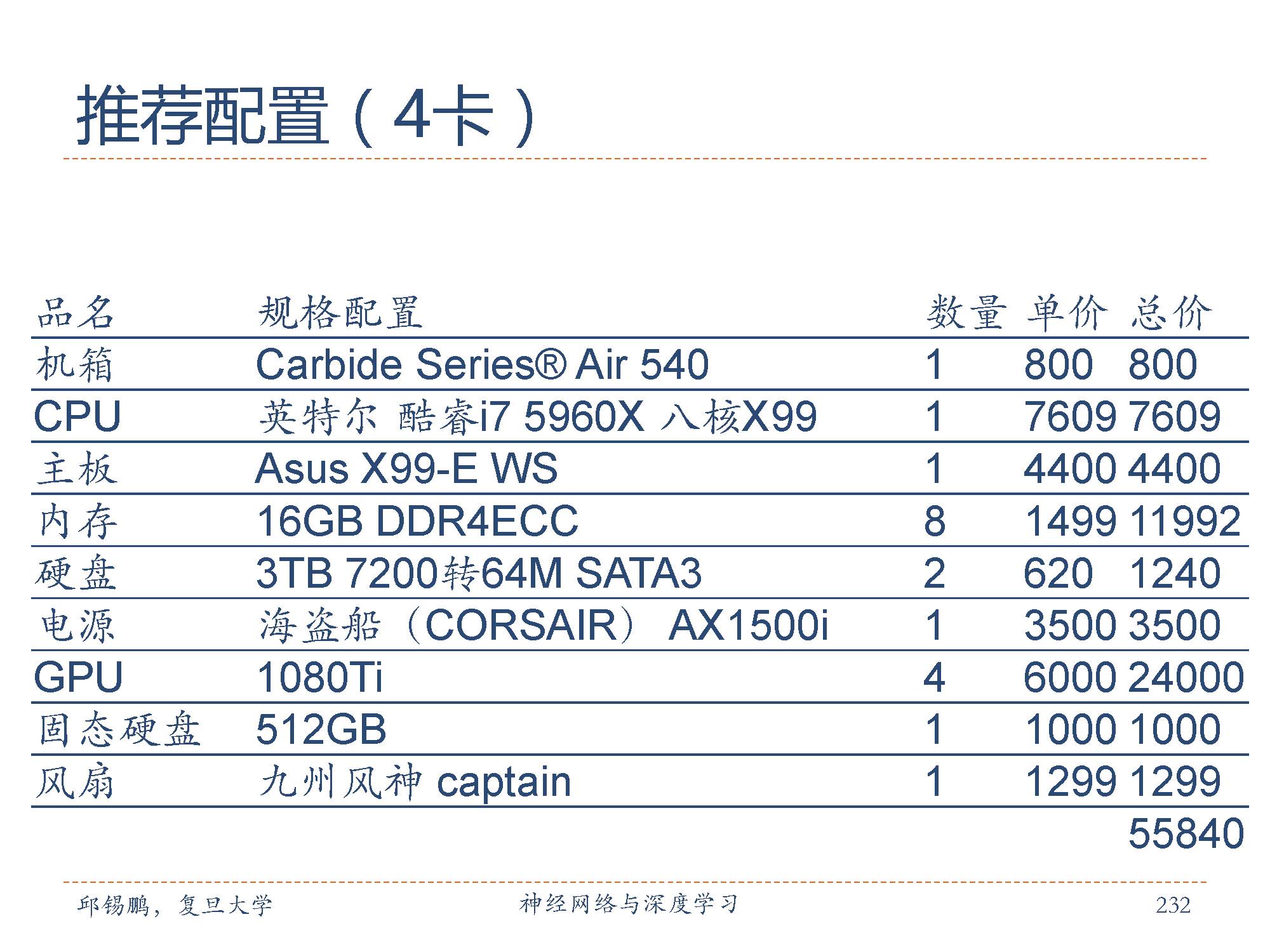
推荐的配置
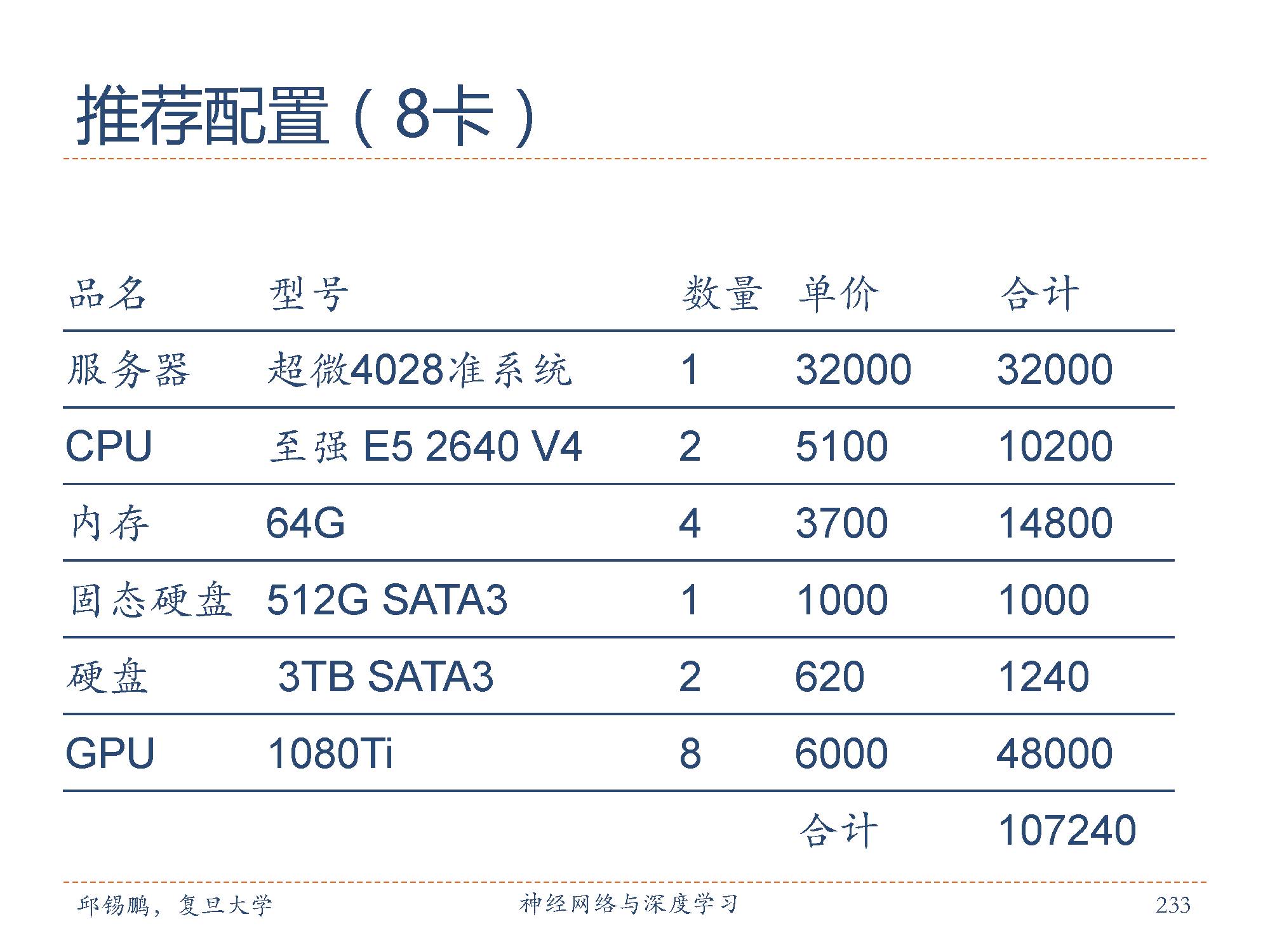
深度学习的实验一般要求比较高配置的服务器,邱老师在这里也推荐了两款配置,包括4-GPU和8-GPU两种配置。具体参数如图所示。

感谢大家耐心读完邱老师的深度学习教程!
第五部分的深度学习进阶模型的进阶模型部分结束了,后续会继续推出深度学习其他系列教程,敬请关注。
特别提示-邱老师深度学习slide-part5下载:
请关注专知公众号(扫一扫最下面专知二维码,或者点击上方蓝色专知),
后台回复“nndl5” 就可以获取本部分pdf下载链接~~
请对深度学习感兴趣的同学,扫描如下二维码,加入专知深度学习群,交流学习~

欢迎转发分享专业AI知识!
请查看更多,登录专知,获取更多AI知识资料,请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录,顶端搜索主题,查看获得对应主题专知荟萃全集知识等资料!如下图所示~
请扫描专知小助手,加入专知人工智能群交流~

专知荟萃知识资料全集获取(关注本公众号-专知,获取下载链接),请查看:
【专知荟萃01】深度学习知识资料大全集(入门/进阶/论文/代码/数据/综述/领域专家等)(附pdf下载)
【专知荟萃02】自然语言处理NLP知识资料大全集(入门/进阶/论文/Toolkit/数据/综述/专家等)(附pdf下载)
【专知荟萃03】知识图谱KG知识资料全集(入门/进阶/论文/代码/数据/综述/专家等)(附pdf下载)
【专知荟萃04】自动问答QA知识资料全集(入门/进阶/论文/代码/数据/综述/专家等)(附pdf下载)
【专知荟萃05】聊天机器人Chatbot知识资料全集(入门/进阶/论文/软件/数据/专家等)(附pdf下载)
【专知荟萃06】计算机视觉CV知识资料大全集(入门/进阶/论文/课程/会议/专家等)(附pdf下载)
【专知荟萃07】自动文摘AS知识资料全集(入门/进阶/代码/数据/专家等)(附pdf下载)
【专知荟萃08】图像描述生成Image Caption知识资料全集(入门/进阶/论文/综述/视频/专家等)
【专知荟萃09】目标检测知识资料全集(入门/进阶/论文/综述/视频/代码等)
【专知荟萃10】推荐系统RS知识资料全集(入门/进阶/论文/综述/视频/代码等)
【专知荟萃11】GAN生成式对抗网络知识资料全集(理论/报告/教程/综述/代码等)
【专知荟萃12】信息检索 Information Retrieval 知识资料全集(入门/进阶/综述/代码/专家,附PDF下载)
【专知荟萃13】工业学术界用户画像 User Profile 实用知识资料全集(入门/进阶/竞赛/论文/PPT,附PDF下载)
【专知荟萃14】机器翻译 Machine Translation知识资料全集(入门/进阶/综述/视频/代码/专家,附PDF下载)
【专知荟萃15】图像检索Image Retrieval知识资料全集(入门/进阶/综述/视频/代码/专家,附PDF下载)
【专知荟萃16】主题模型Topic Model知识资料全集(基础/进阶/论文/综述/代码/专家,附PDF下载)
【专知荟萃17】情感分析Sentiment Analysis 知识资料全集(入门/进阶/论文/综述/视频/专家,附查看)
【专知荟萃18】目标跟踪Object Tracking知识资料全集(入门/进阶/论文/综述/视频/专家,附查看)
【专知荟萃19】图像识别Image Recognition知识资料全集(入门/进阶/论文/综述/视频/专家,附查看)
-END-
欢迎使用专知
专知,一个新的认知方式! 专注在人工智能领域为AI从业者提供专业可信的知识分发服务, 包括主题定制、主题链路、搜索发现等服务,帮你又好又快找到所需知识。
使用方法>>访问www.zhuanzhi.ai, 或点击文章下方“阅读原文”即可访问专知
中国科学院自动化研究所专知团队
@2017 专知
专 · 知
关注我们的公众号,获取最新关于专知以及人工智能的资讯、技术、算法、深度干货等内容。扫一扫下方关注我们的微信公众号。


点击“阅读原文”,使用专知!
展开全文



