【计算机视觉】检测与分割详解
【导读】神经网络在计算机视觉领域有着广泛的应用。只要稍加变形,同样的工具和技术就可以有效地应用于广泛的任务。在本文中,我们将介绍其中的几个应用程序和方法,包括语义分割、分类与定位、目标检测、实例分割。
作者 | Ravindra Parmar
编译 | Xiaowen
Detection andSegmentation through ConvNets
——计算机视觉-目标检测与分割
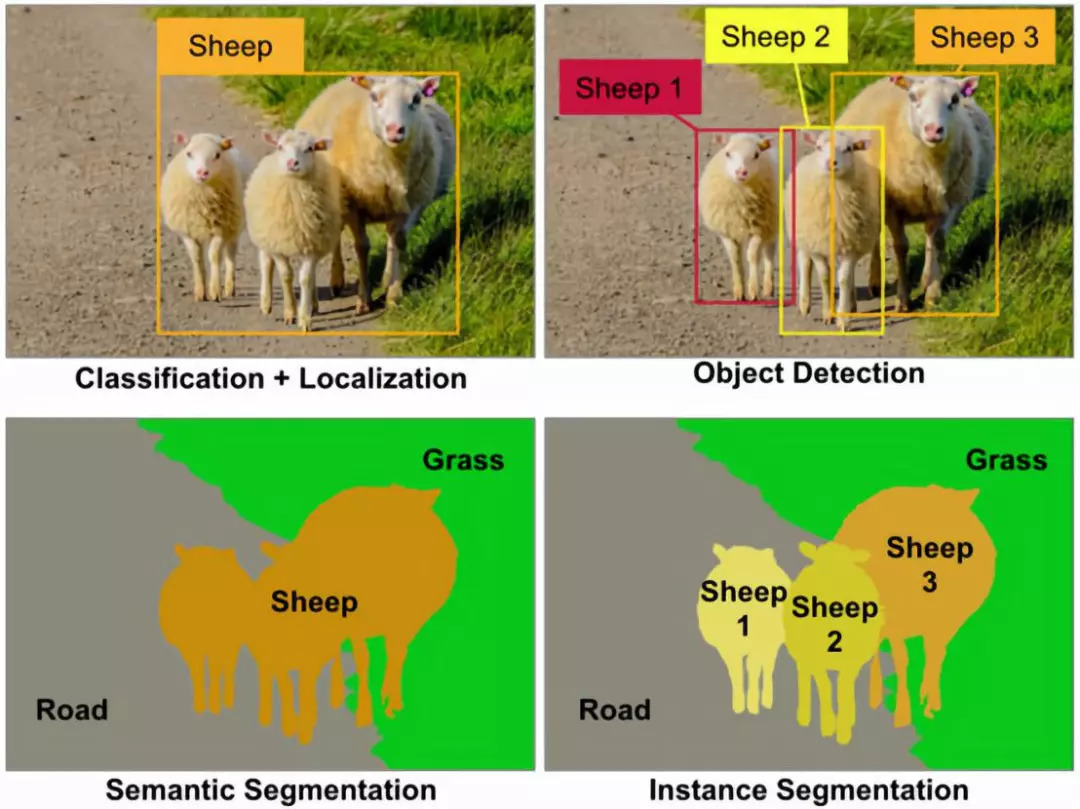
神经网络在计算机视觉领域有着广泛的应用。只要稍加变形,同样的工具和技术就可以有效地应用于广泛的任务。在本文中,我们将介绍其中的几个应用程序和方法。最常见的四个是:
语义分割(Semantic segmentation)
分类与定位(Classification and localization)
目标检测(Object detection)
实例分割(Instance segmentation)
语义分割
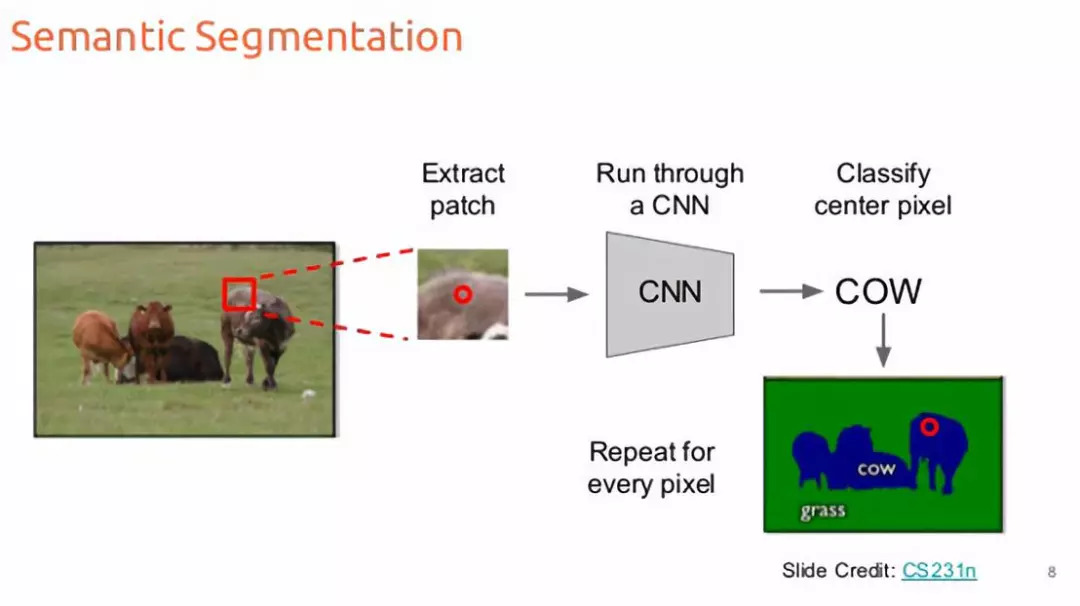
我们输入图像并输出每个像素的类别决策。换句话说,我们希望将每个像素划分为几个可能的类别之一。这意味着,所有携带绵羊的像素都会被分类为一个类别,有草和道路的像素也会被分类。更重要的是,输出不会区分两种不同的绵羊。
解决这个问题的一个可能的方法是把它当作一个滑动窗口的分类问题[1]。这样我们就把输入图像分解成几个大小相同的crop。然后每一种crop都会被传送给CNN,作为输出得到该crop的分类类别。像素级的crop会对每一个像素进行分类。这是非常容易的,不是吗?
滑动窗口的语义分割
嗯,甚至不需要研究生学位就能看出这种方法在实际中的计算效率有多低。我们需要的是一种尽量将图像的传送次数减少到单道的方法。幸运的是,有一些技术可以用所有卷积层来同时对所有像素进行预测。
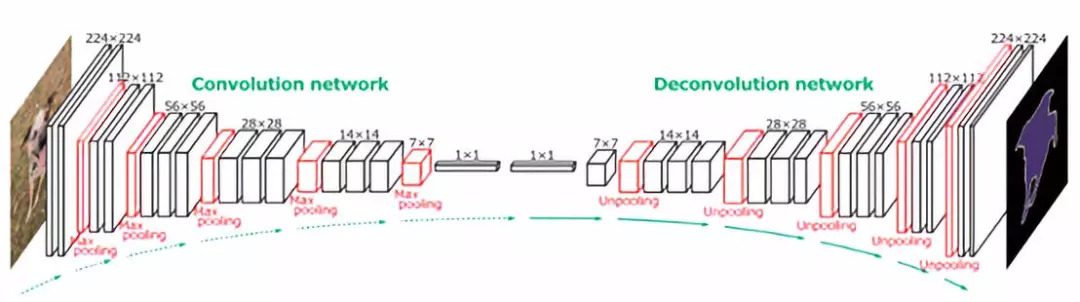
语义分割的全卷积层
如你所见,这样的网络将是下采样和上采样层的混合,以保持输入图像的空间大小(在像素级进行预测)。下采样是通过使用strides或max/avg pooling来实现的。另一方面,上采样需要使用一些巧妙的技术,其中两个是-最近邻[2]和转置卷积[3]。
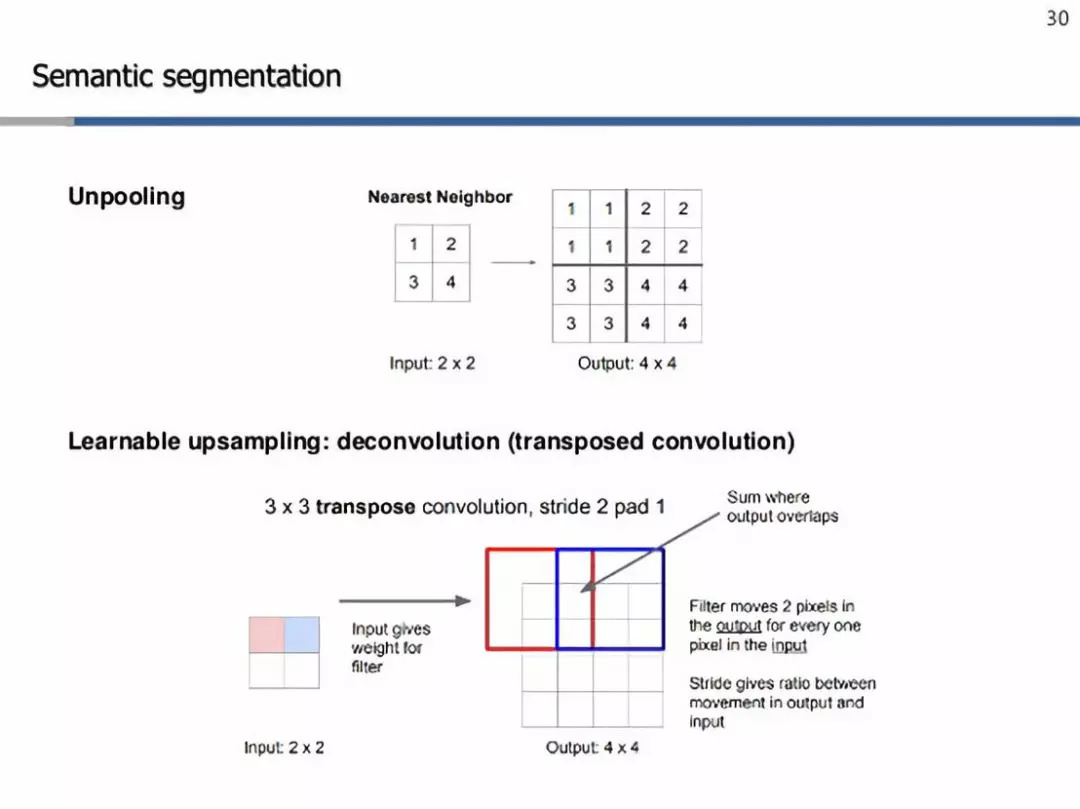
上采样技术
简而言之,最近邻只是在它的接受域中复制特定元素(在上面的例子中是2x2)。另一方面,转置卷积努力学习适当的权重,为滤波器执行上采样。在这里,我们从左上角值开始,这是一个标量,与过滤器相乘,并将这些值复制到输出单元格中。然后,我们将滤波器中的一些特定像素与输入中的一个像素成比例地移动。这就是输出和输入之间的比率,这将给我们提供我们想要使用的步幅。在有重叠的情况下,我们只对数值进行汇总。这样,这些过滤器也构成了这些网络的可学习参数,而不是一些固定的值集,就像最近的邻居一样。最后,利用像素级的交叉熵损失[4]对整个网络进行反向传播训练[5]。
分类和定位
图像分类[6]处理的是将类别标签分配给图像。但是有时,除了预测类别之外,我们还感兴趣的是该对象在图像中的位置。从数学的角度来说,我们可能希望在图像的顶部画一个包围框。幸运的是,我们可以重用图像分类学到的所有工具和技术。
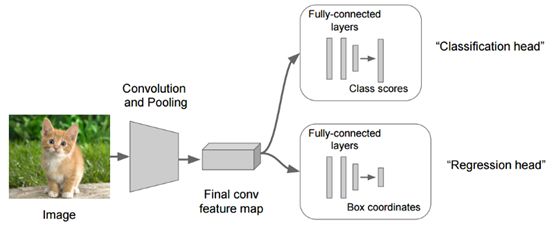
用于分类定位的卷积网络
我们首先将输入图像输入到某个巨大的ConvNet中,这将给出每个类别的分数。但是现在我们有了另一个完全连接的层,它从先前层次生成的特征Map中预测对象的边界框坐标(x,y坐标以及高度和宽度)。因此,我们的网络将产生两个输出,一个对应于图像类,另一个对应于边界。为了训练这个网络,我们必须考虑两个损失:分类的交叉熵损失和边界预测的L1/L2损失[7](某种回归损失)。
广义上,这种预测固定数目集的思想可以应用于除定位以外的各种计算机视觉任务,如人体姿态估计。

人体姿态估计
在这里,我们可以定义人体姿势的固定点集上的身体,例如关节。然后将我们的图像输入到ConvNet并输出相同的固定点集(x,y)坐标。然后我们可以在每一点上应用某种回归损失来通过反向训练来训练网络.
目标检测
目标检测的思想是从我们感兴趣的一组固定类别开始,每当这些类别中的任何一种出现在输入图像中时,我们就会在图像周围画出包围框,并预测它的类标签。这与图像分类和定位的不同之处在于,在前一种意义上,我们只对单个对象进行分类和绘制边框。而在后一种情况下,我们无法提前知道图像中期望的对象数量。同样,我们也可以采用蛮力滑动窗口方法[8]来解决这个问题。然而,这又是一种计算效率低下的问题,很少有算法能有效地解决这一问题,比如基于Region proposal的算法,及基于yolo目标检测的算法[9]。
基于Region proposal的算法
给定一个输入图像,一个Regionproposal算法会给出成千上万个可能出现对象的框。当然,在没有对象的情况下,输出框中存在噪声的可能性。但是,如果图像中有任何对象,该算法就会选择它作为候选框。
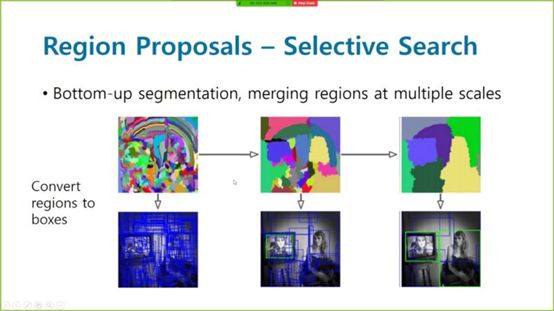
区域搜索的选择性搜索
为了使所有的候选框都是一样大小的,我们需要把它们变形到固定的方格大小,这样我们最终就可以给网络输入了。然后,我们可以将一个巨大的ConvNets应用到从region proposal输出的每个候选框中以获得最终类别。当然,与蛮力滑动窗口算法相比,它最终的计算效率要高得多。这就是R-CNN背后的整个想法。为了进一步降低复杂度,采用Fast R-CNN的方法,Fast R-CNN的思想首先是通过ConvNet传递输入图像,得到高分辨率的特征图,然后将这些region proposals强加到这个特征图上,而不是实际的图像上。这使得我们可以在有大量crops的情况下,在整个图像中重用大量代价昂贵的卷积运算。
YOLO(You only look once)
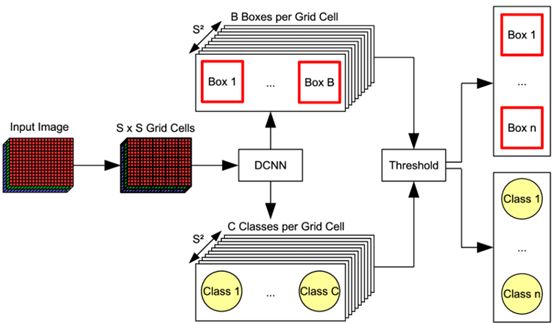
YOLO目标检测
Yolo背后的想法是,不要在所有提议的区域进行独立的处理,而是将所有的预测都重组为一个单一的回归问题,从图像像素到包围框坐标和分类概率。
我们首先将整个输入图像划分为SXS网格,每个网格单元与b边界(x,y,w,h)一起预测c条件的类概率(Pr(Class | Object)),每个边界盒(x,y,w,h)都有一个置信度分数。(x,y)坐标表示边框的中心相对于网格单元格的边界,而宽度和高度则是相对于整个图像预测。概率是以包含对象的网格单元为条件的。我们只预测每个网格单元格的一组类概率,而不管方框B的数量。置信度分数反映了模型对框中包含对象的信心程度,如果框中没有对象,则置信度必须为零。在另一个极端,置信度应与预测框与ground truth标签之间的交集(IOU)相同。
Confidence score =Pr(Object) * IOU
在测试时,我们将条件类概率和单个边框置信度预测相乘,这给出了每个框的特定类别的置信度分数。这些分数既编码了该类出现在盒子中的概率,也表示了预测的盒适合对象的程度。
Pr(Class | Object) ∗(Pr(Object) ∗ IOU) = Pr(Class) ∗ IOU
实例分割
实例分割采用语义分割和目标检测相结合的技术。给定一幅图像,我们希望预测该图像中目标的位置和身份(类似于目标检测),但是,与其预测这些目标的边界框,不如预测这些目标的整个分割掩码,即输入图像中的哪个像素对应于哪个目标实例。在此基础上,我们对图像中的每一只绵羊分别得到了分割掩码,而语义分割中所有的绵羊都得到了相同的分割掩码。
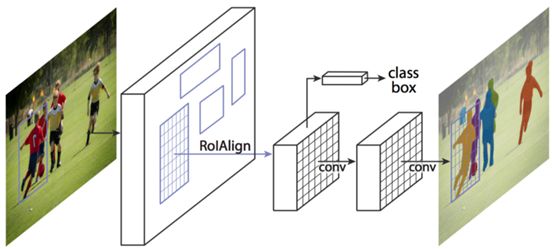
基于Mask R-CNN的实例分割
Mask R-CNN是这类任务的首选网络。在这个多阶段的处理任务中,我们通过一个ConvNet和一些学习region proposal网络传递输入图像。一旦我们有了这些region proposal,我们就把这些proposals投影到卷积特征图上,就像我们在R-CNN的情况下所做的那样。然而现在,除了进行分类和边界框预测之外,我们还预测了每个region proposal的分割掩码。
参考链接:
1. https://www.pyimagesearch.com/2015/03/23/sliding-windows-for-object-detection-with-python-and-opencv/
2. https://groups.google.com/d/topic/neon-users/I-x9ooJO5PA
3. https://towardsdatascience.com/up-sampling-with-transposed-convolution-9ae4f2df52d0
4. https://rdipietro.github.io/friendly-intro-to-cross-entropy-loss/
5. http://neuralnetworksanddeeplearning.com/chap2.html
6. https://medium.com/@tifa2up/image-classification-using-deep-neural-networks-a-beginner-friendly-approach-using-tensorflow-94b0a090ccd4
7. https://letslearnai.com/2018/03/10/what-are-l1-and-l2-loss-functions.html
8. https://www.pyimagesearch.com/2015/03/23/sliding-windows-for-object-detection-with-python-and-opencv/
9. https://pjreddie.com/darknet/yolo/
原文链接:
https://towardsdatascience.com/detection-and-segmentation-through-convnets-47aa42de27ea
-END-
专 · 知
人工智能领域26个主题知识资料全集获取与加入专知人工智能服务群: 欢迎微信扫一扫加入专知人工智能知识星球群,获取专业知识教程视频资料和与专家交流咨询!

请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请加专知小助手微信(扫一扫如下二维码添加),加入专知主题群(请备注主题类型:AI、NLP、CV、 KG等)交流~

请关注专知公众号,获取人工智能的专业知识!
点击“阅读原文”,使用专知
展开全文



