【论文推荐】最新六篇情感分析相关论文—深度上下文、支持向量机、两级LSTM、多模态情感分析、软件工程、代码混合
【导读】专知内容组整理了最近六篇情感分析(Sentiment Analysis)相关文章,为大家进行介绍,欢迎查看!
1. Deep contextualized word representations(深度上下文的词表示)
作者:Matthew E. Peters,Mark Neumann,Mohit Iyyer,Matt Gardner,Christopher Clark,Kenton Lee,Luke Zettlemoyer
机构:University of Washington
摘要:We introduce a new type of deep contextualized word representation that models both (1) complex characteristics of word use (e.g., syntax and semantics), and (2) how these uses vary across linguistic contexts (i.e., to model polysemy). Our word vectors are learned functions of the internal states of a deep bidirectional language model (biLM), which is pre-trained on a large text corpus. We show that these representations can be easily added to existing models and significantly improve the state of the art across six challenging NLP problems, including question answering, textual entailment and sentiment analysis. We also present an analysis showing that exposing the deep internals of the pre-trained network is crucial, allowing downstream models to mix different types of semi-supervision signals.
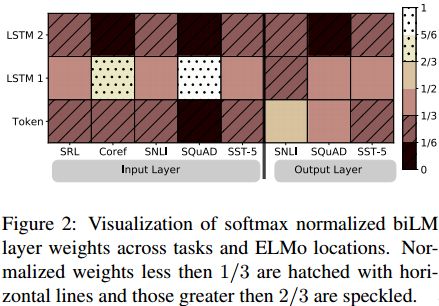
期刊:arXiv, 2018年3月23日
网址:
http://www.zhuanzhi.ai/document/e99adfc85a049b9b08d32861faee38fd
2. Sentiment Analysis of Comments on Rohingya Movement with Support Vector Machine(基于支持向量机的对罗兴亚运动评论的情感分析)
作者:Hemayet Ahmed Chowdhury,Tanvir Alam Nibir,Md. Saiful Islam
机构:Shahjalal University of Science and Technology
摘要:The Rohingya Movement and Crisis caused a huge uproar in the political and economic state of Bangladesh. Refugee movement is a recurring event and a large amount of data in the form of opinions remains on social media such as Facebook, with very little analysis done on them.To analyse the comments based on all Rohingya related posts, we had to create and modify a classifier based on the Support Vector Machine algorithm. The code is implemented in python and uses scikit-learn library. A dataset on Rohingya analysis is not currently available so we had to use our own data set of 2500 positive and 2500 negative comments. We specifically used a support vector machine with linear kernel. A previous experiment was performed by us on the same dataset using the naive bayes algorithm, but that did not yield impressive results.
期刊:arXiv, 2018年3月22日
网址:
http://www.zhuanzhi.ai/document/e0f0d7a8efbc840dd91780fd0f424a26
3. ρ-hot Lexicon Embedding-based Two-level LSTM for Sentiment Analysis(基于ρ-hot词典Embedding的两级LSTM情感分析)
作者:Ou Wu,Tao Yang,Mengyang Li,Ming Li
摘要:Sentiment analysis is a key component in various text mining applications. Numerous sentiment classification techniques, including conventional and deep learning-based methods, have been proposed in the literature. In most existing methods, a high-quality training set is assumed to be given. Nevertheless, constructing a high-quality training set that consists of highly accurate labels is challenging in real applications. This difficulty stems from the fact that text samples usually contain complex sentiment representations, and their annotation is subjective. We address this challenge in this study by leveraging a new labeling strategy and utilizing a two-level long short-term memory network to construct a sentiment classifier. Lexical cues are useful for sentiment analysis, and they have been utilized in conventional studies. For example, polar and privative words play important roles in sentiment analysis. A new encoding strategy, that is, $\rho$-hot encoding, is proposed to alleviate the drawbacks of one-hot encoding and thus effectively incorporate useful lexical cues. We compile three Chinese data sets on the basis of our label strategy and proposed methodology. Experiments on the three data sets demonstrate that the proposed method outperforms state-of-the-art algorithms.
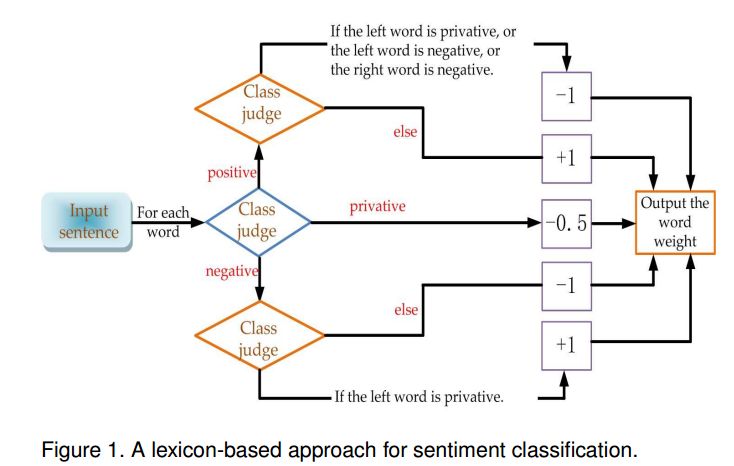
期刊:arXiv, 2018年3月21日
网址:
http://www.zhuanzhi.ai/document/9f0a5b91d95f818aee5c76a4b0597018
4. Multimodal Sentiment Analysis: Addressing Key Issues and Setting up Baselines(多模态情感分析:解决关键问题和建立基准)
作者:Soujanya Poria,Navonil Majumder,Devamanyu Hazarika,Erik Cambria,Amir Hussain,Alexander Gelbukh
摘要:Sentiment analysis is proven to be very useful tool in many applications regarding social media. This has led to a great surge of research in this field. Hence, in this paper, we compile the baselines for such research. In this paper, we explore three different deep-learning based architectures for multimodal sentiment classification, each improving upon the previous. Further, we evaluate these architectures with multiple datasets with fixed train/test partition. We also discuss some major issues, frequently ignored in multimodal sentiment analysis research, e.g., role of speaker-exclusive models, importance of different modalities, and generalizability. This framework illustrates the different facets of analysis to be considered while performing multimodal sentiment analysis and, hence, serves as a new benchmark for future research in this emerging field. We draw a comparison among the methods using empirical data, obtained from the experiments. In the future, we plan to focus on extracting semantics from visual features, cross-modal features and fusion.
期刊:arXiv, 2018年3月19日
网址:
http://www.zhuanzhi.ai/document/c17e1c4ff9714aaa7f7faca96b692850
5. A Benchmark Study on Sentiment Analysis for Software Engineering Research(对软件工程研究进行情感分析的基准研究)
作者:Nicole Novielli,Daniela Girardi,Filippo Lanubile
机构:University of Bari Aldo Moro
摘要:A recent research trend has emerged to identify developers' emotions, by applying sentiment analysis to the content of communication traces left in collaborative development environments. Trying to overcome the limitations posed by using off-the-shelf sentiment analysis tools, researchers recently started to develop their own tools for the software engineering domain. In this paper, we report a benchmark study to assess the performance and reliability of three sentiment analysis tools specifically customized for software engineering. Furthermore, we offer a reflection on the open challenges, as they emerge from a qualitative analysis of misclassified texts.

期刊:arXiv, 2018年3月17日
网址:
http://www.zhuanzhi.ai/document/72d31a7dd0bf34c1689dfacf0b1e76e6
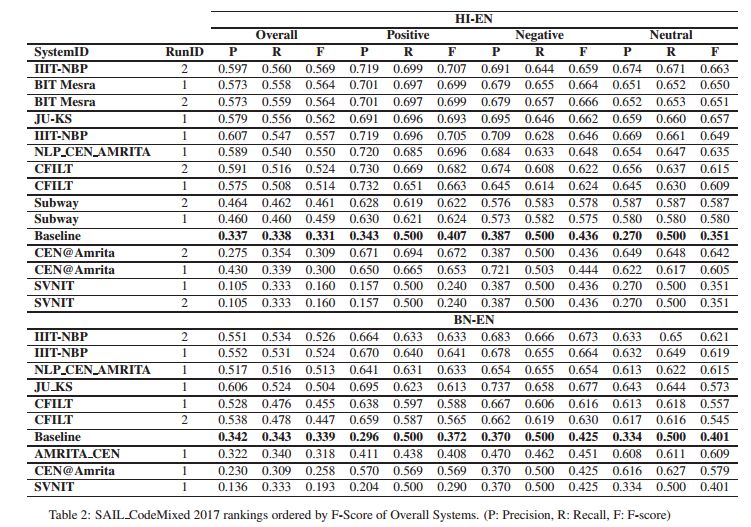
6.Sentiment Analysis of Code-Mixed Indian Languages: An Overview of SAIL_Code-Mixed Shared Task @ICON-2017(对代码混合的印度语言的情绪分析:对sail_code混合共享任务的概述)
作者:Braja Gopal Patra,Dipankar Das,Amitava Das
机构:University of Texas Health Science Center,Jadavpur University
摘要:Sentiment analysis is essential in many real-world applications such as stance detection, review analysis, recommendation system, and so on. Sentiment analysis becomes more difficult when the data is noisy and collected from social media. India is a multilingual country; people use more than one languages to communicate within themselves. The switching in between the languages is called code-switching or code-mixing, depending upon the type of mixing. This paper presents overview of the shared task on sentiment analysis of code-mixed data pairs of Hindi-English and Bengali-English collected from the different social media platform. The paper describes the task, dataset, evaluation, baseline and participant's systems.
期刊:arXiv, 2018年3月19日
网址:
http://www.zhuanzhi.ai/document/a3607bbaf647980e6ae4ad1e25330380
-END-
专 · 知
人工智能领域主题知识资料查看获取:【专知荟萃】人工智能领域26个主题知识资料全集(入门/进阶/论文/综述/视频/专家等)
同时欢迎各位用户进行专知投稿,详情请点击:
【诚邀】专知诚挚邀请各位专业者加入AI创作者计划!了解使用专知!
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

请加专知小助手微信(Rancho_Fang),加入专知主题人工智能群交流!加入专知主题群(请备注主题类型:AI、NLP、CV、 KG等)交流~

点击“阅读原文”,使用专知!
展开全文



