【重温经典】吴恩达机器学习课程学习笔记十一:神经网络
【导读】前一段时间,专知内容组推出了春节充电系列:李宏毅2017机器学习课程学习笔记,反响热烈,由此可见,大家对人工智能、机器学习的系列课程非常感兴趣,近期,专知内容组推出吴恩达老师的机器学习课程笔记系列,重温机器学习经典课程,希望大家会喜欢。
【重温经典】吴恩达机器学习课程学习笔记二:无监督学习(unsupervised learning)
【重温经典】吴恩达机器学习课程学习笔记三:监督学习模型以及代价函数的介绍
【重温经典】吴恩达机器学习课程学习笔记六:特征处理与多项式拟合
【重温经典】吴恩达机器学习课程学习笔记七:Logistic回归
【重温经典】吴恩达机器学习课程学习笔记八:Logistic回归续
吴恩达机器学习课程系列视频链接:
http://study.163.com/course/courseMain.htm?courseId=1004570029
吴恩达课程学习笔记十一:神经网络
1、 非线性假设
从本次课程总结开始,将开始对神经网络这一机器学习算法进行介绍。当然,先介绍神经网络的表示。神经网络最终是为了制造出能模拟大脑的机器。
为什么使用神经网络算法?
如下图左上方的数据集,采用logistic回归,因为只有两个特征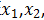
但是对于特征项数较多时,比如房价预测的例子,当特征种类n=100时,二次项会有5000项,三次项有170000,复杂度分别是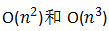
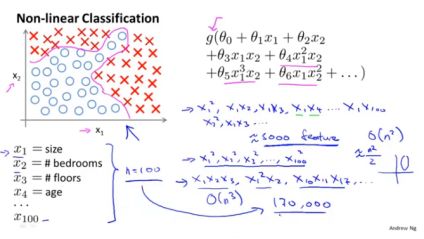
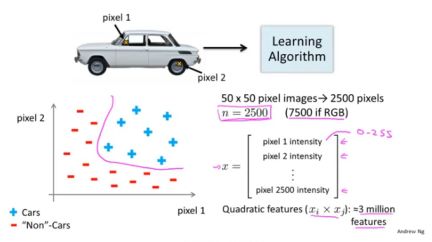
综上可以看出logistic回归在处理特征数较多时遇到的问题。我们再看一个计算机视觉里,可能经常说的例子。假设你想训练一个分类器,来判断一个输入图片是否是汽车。需要走下面的这样一个流程:
1、 取出图像中一小部分(下图红色部分),计算机会读为矩阵(像素强度值的网络)
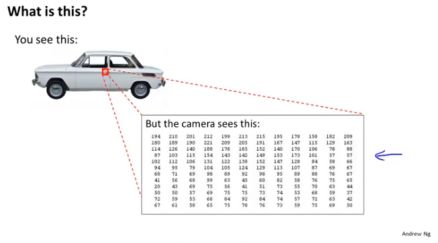
2、 以下是我们的样本,一部分图片是汽车,一部分不是,在理想情况下,训练器可以识别出一个输入图像是否是汽车。

3、 我们从样本图片中选择像素点位置(这里选取pixel1和pixel2),根据像素点的强度来确定图片在如下坐标系中的位置。现在需要做的是使用一种非线性假设解决这个二类分类问题。
假设图像的大小为50pixel*50pixel,则一共有2500pixels(即n=2500),则输入特征向量x如下图,若采用灰度图,则intensity取值为0~255,若为彩度图,则n=7500。
若使用*(二次项),则会约有300万个特征。这个数字太大,如果对于每个样本都处理300万个特征,这样的计算量太大了。
综上我们可知,就算仅仅考虑二次项与三次项,当n较大时,logistic仍然会体现出它极大的局限性。而神经网络被证明在学习复杂的非线性假设上可以较好的工作。
2、模型展示:
如下图所示,是一个简单神经元的图,x1,x2,x3是输入信息(有时候会包括x0=1,又称为bias unit,根据对于输入的表示是否有利而决定是否有x0)。黄色的圆圈是一个(轴突),会对输入的信息进行处理,下图为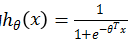
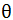
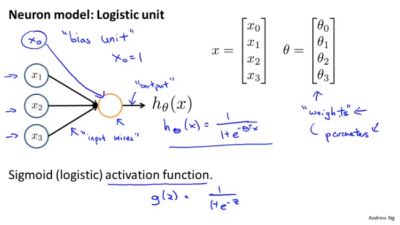
下面是一张神经网络的图,第一层被称为输入层,第二层称为隐藏层,第三层称为输出层,实际上在含有更多层的神经网络中,除了输入与输出层,其他都可以被称为隐藏层。在训练过程中,我们通常只能看到输入与输出的数据。
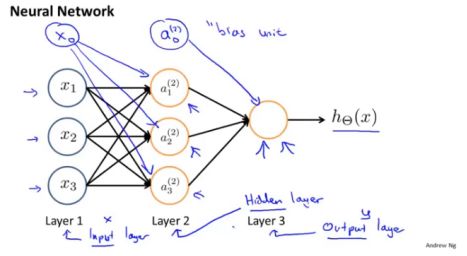
下图给出了神经网络各层之间的关系。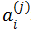
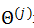
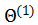
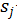
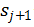
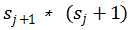

参考链接:
http://study.163.com/course/courseMain.htm?courseId=1004570029
请关注专知公众号(扫一扫最下面专知二维码,或者点击上方蓝色专知),
后台回复“NGML2018” 就可以获取 吴恩达机器学习课程下载链接~
-END-
专 · 知
人工智能领域主题知识资料查看与加入专知人工智能服务群:
【专知AI服务计划】专知AI知识技术服务会员群加入与人工智能领域26个主题知识资料全集获取

点击上面图片加入会员
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

点击“阅读原文”,使用专知
展开全文



