TensorFlow Lite指南实战,附48页ppt
【导读】TensorFlow Lite是可帮助开发人员在移动端(mobile)、嵌入式(embeded)和物联网(IoT)设备上运行TensorFlow机器学习模型的一组工具。它使设备机器学习具有低延迟和更小的二进制体积。本文是TensorFlow Lite入门指导。

TensorFlow Lite
TensorFlow Lite由两个主要组件组成:
interpreter(解释器):可在许多不同的硬件类型(包括手机,嵌入式Linux设备和微控制器)上运行经过特别优化的模型。
-
converter(转换器):将TensorFlow模型转换为供解释器使用的有效形式,并且可以引入优化以改善二进制大小和性能。
下图显示了 TensorFlow Lite 的架构设计:
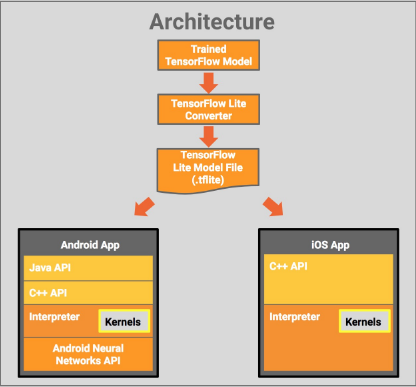
在设备端使用模型的过程:
训练并保存模型(开发机器)
转换模型(开发机器)
将转换后的模型复制到设备上
使用TF Lite解释器运行推理

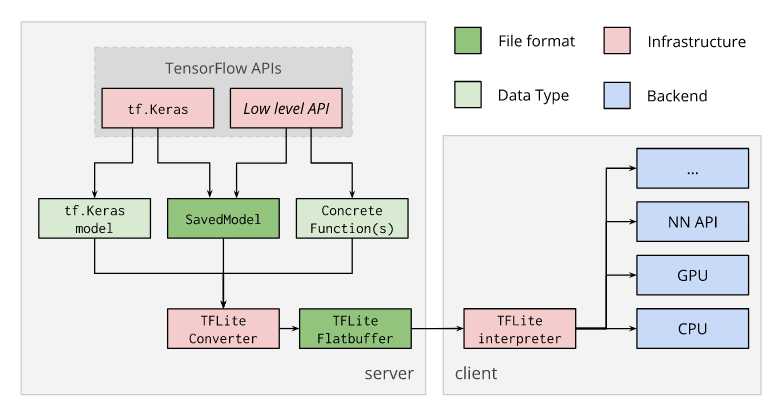
converter使用TF模型生成FlatBuffer文件(.tflite),然后将FlatBuffer文件部署到客户端设备(例如移动设备,嵌入式设备)并使用TensorFlow Lite解释器在本地运行。下图显示了此转换过程:
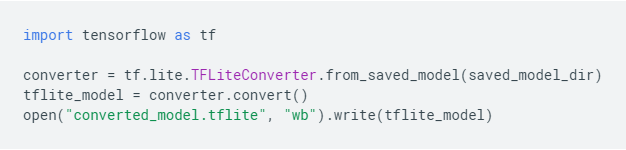
converter代码实现如下:
为什么要使用FlatBuffer? 主要原因有:
无需解析/拆包即可访问序列化数据
内存效率和速度-访问数据所需的唯一内存是缓冲区的内存
没有依赖项的跨平台代码
使用converter转换模型的主要原因:
使模型更小(内存占用更小)
提高推理效率
需要较少的内存访问
推理中使用更少的能量
注:推理(Inference) 是通过模型(model)运行数据(data)以获得预测(predictions)的过程。这个过程需要模型(model)、解释器(interpreter)和输入数据(input data)。
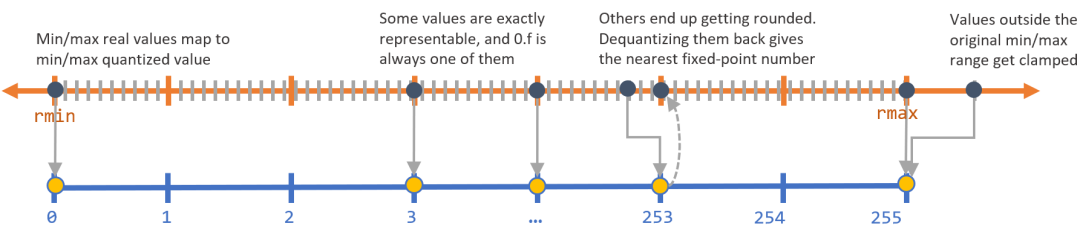
为了实现这些目标,主要组成部分是所谓的量化(Quantization)如下图:
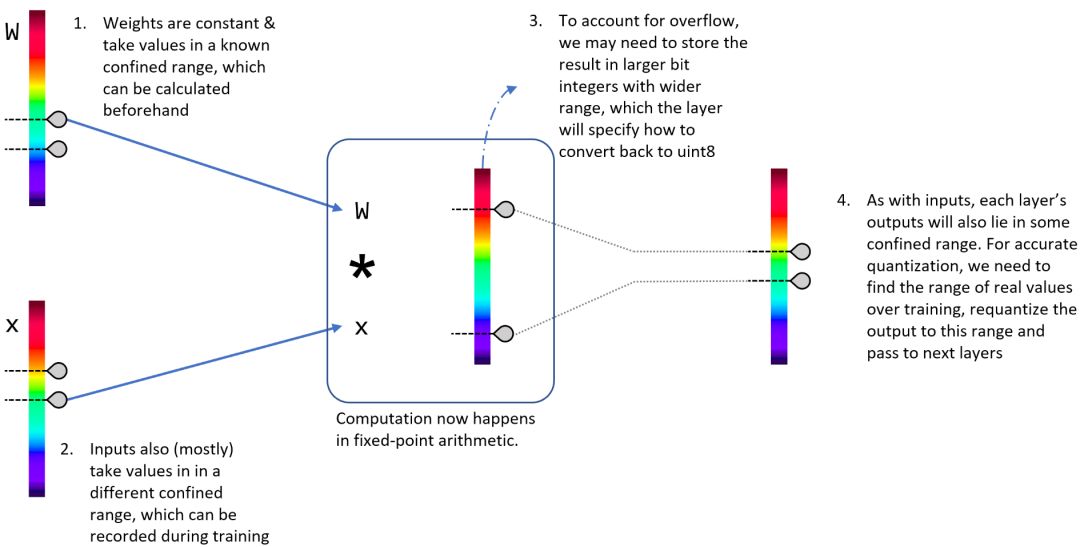
参考网址:
https://sahnimanas.github.io/post/quantization-in-tflite/#deep_compression
Quantization有两种量化方式:
Post-training quantization
更容易实现,在大多数情况下非常高效
Training-aware quantization
更复杂,需要重写计算图
量化公式:
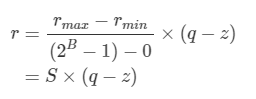
r是真实值(通常是float32)
q是B位整数(uint8,uint32等)量化表示
S(floating)和z(integer)是我们缩放的因子
更多内容请参考原始PPT。
-
后台回复“TFLAP” 就可以获取完整《TensorFlow Lite A primer》PPT的下载链接~
部分PPT截图如下所示:









参考链接:
https://github.com/michelucci/TensorFlow-Roadshow-Zurich
https://www.tensorflow.org/lite/guide




展开全文



