【攻克Dota2基础算法】深度Q学习介绍
【导读】最近,OpenAI在dota2的5v5比赛中,使用基于强化学习的AI bot击败了人类玩家,震惊业界。那么强化学习是如何操纵游戏人物一步步达成胜利的呢?请看今天的深度Q学习介绍,本文翻译自Thomas Simonini在medium专栏上强化学习系列的第三篇文章,其中关于Q-learning的介绍可以参考本系列的第二篇【1】。
作者 | Thomas Simonini
编译 | 专知
整理 | yongxi
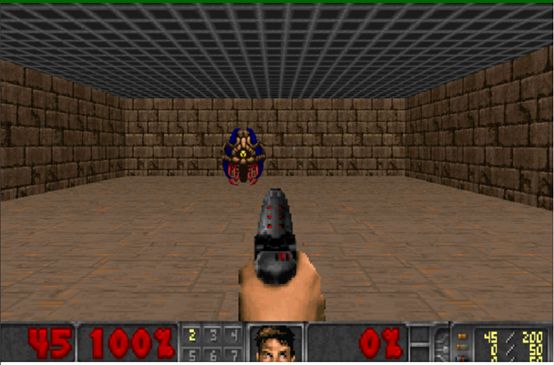
这篇文章是强化学习系列的第三篇文章。如果需要更多的资源,可以在此查看【2】. 今天,我们将构建一个深度Q网络,为环境中的agent实现一个可以获取环境状态信息以及近似Q-value的神经网络。
多亏这个模型,我们才可以使用agent打Doom游戏。
在这篇文章中,你将学到:
什么是深度Q学习(DQL)。
DQL中的最好策略是什么?
如何解决Temporal limitation问题?
为什么我们使用经验回放?
DQL背后的数学理论是什么?
如何通过tensorflow实现?
在Q-learning中加入“Deep”
在本系列的前一篇文章中【1】,我们基于Q-learning方法构建了一个可以玩Frozen Lake游戏的agent。当时实现了Q-learing方法并可以更新Q-table。以此表作为“备忘录”来帮助我们找到当给定环境状态时,在未来获得最佳奖励的行为。这是一个好策略,但却扩展性很低。
今天,我们将创建一个可以玩Doom的agent。Doom内的环境非常巨大(百万级的状态集)。创建Q-table并更新它们非常不易。
最好的做法是,构建一个神经网络,以近似得出各个状态下行为的Q-values。
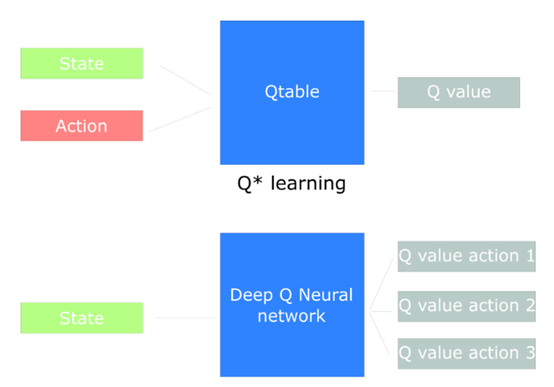
如何令深度Q学习工作呢?
这看起来非常复杂,但我们将一步一步完成解释。
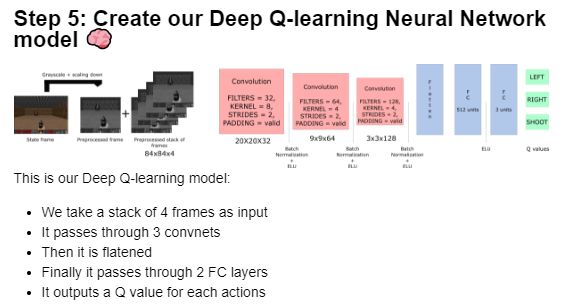
我们的深度Q神经网络的每次输入是4帧图片,输出为各环境下的每个可选行为的Q-values向量。我们需要找到向量中最大的Q-value,以帮我们做出最好的行为决策。
开始,agent的错误很多,但一段时间后,就可以将每帧画面(环境)与最好的行为关联起来

预处理部分
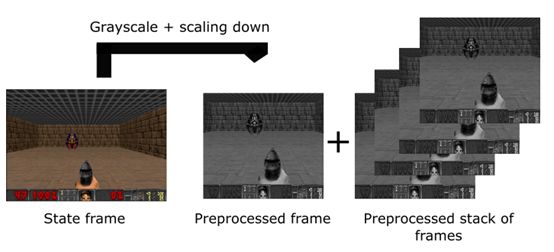
预处理是非常重要的一步,我们希望减少状态的复杂度,以帮助减少训练过程所需的计算时间。
首先,我们将每帧图像转换为灰度图,因为在我们的例子中,色彩并没有提供很多的重要信息。之后,我们将每帧图片切分,在例子中,屋顶的价值并不大。最后,减少帧的大小,并将每四帧分为一组。
Temporal limitation问题
关于这个问题,Arthur Juliani【3】在他的文章【4】中给出了详细的解释。他提出了一个想法,通过LSTM神经网络解决这一问题【5】。但是,我认为对于初学者来说,将多个帧分成一组的方法更加合适。
你也许会问,为什么需要将每帧图片分为一组?这是由于可以帮我们解决temporal limitation问题。具体例子如下,在Pong游戏中,当你看到这一帧:

你能告诉我这个球会往哪去吗?当然不行,因为只有一帧图片是无法做出判断的。但是如果增加几帧信息,就可以很清晰的知道球正朝右边运动。

对于我们的Doom agent来说,道理相同,如果一次只输入一帧,则无法知道运动细节,也就则无法做出正确的决策了。
使用卷积神经网络
这些帧图片将使用三个卷积层进行处理。这些网络层可以允许agent发现图片之间的空间关系。
如果你对卷积方法不是很了解,那么可以阅读如下文章【6】。
每个卷积层将使用ELU作为激活函数。在网络中,我们采用一个使用激活函数为ELU的全连接层、一个输出层(采用线性激活函数的全连接层)来为每个行为计算Q-value值。
经验回放:给观察经验带来更大的效率
经验回放可以帮我们解决两个问题:
避免遗忘之前的经验。
减少经验之间的相关性
我将解释这两种概念。这部分的灵感来自于Udacity中深度学习基础的深度Q学习章节。
1、避免遗忘之前的经验
这里遇到各大问题:由于环境与行为间的高相关性,权重是可变化的。
回顾第一篇文章中,我们介绍了强化学习的过程【7】。
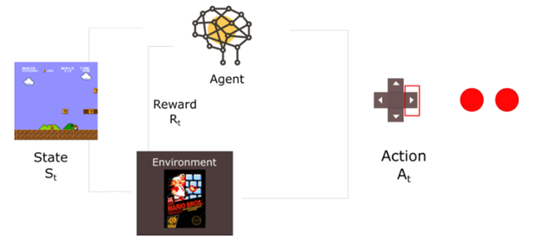
在每一个时间步中,我们都会接受一个元祖(状态、行为、反馈、新状态),模型从中学习并获得经验。
我们的问题是在与环境的交互过程中获得了连续样本,并且它倾向于忘记之前的经验。例如,如果我们完成了第一级到第二级的行为,随着时间的推移,agent将倾向于忘记它是如何从第一级运动到第二级的。

在多个时间点使用之前的行为,将有助于学习进程变得更加高效。
我们的解决办法是,创建一个“回放缓存”,其中存储的经验元祖将于环境进行交互,之后我们采样到部分样本,输入至神经网络中。

2、减少经验间的相关性
此处有另一个问题,我们知道每个行为都会对下一个状态产生影响。输出一组经验元组序列,有可能存在很高的相关性。如果我们在序列顺序上进行训练,有可能会使agent被相关性所影响。
通过对经验回放的随机采样,可以破坏这种相关性。以预防agent灾难性的震荡于消散。
可以通过例子来简单理解一下,首先,我们使用第一个射手,对面是一个怪兽,可以从左运动到右。我们有两把枪于两个可选动作,向左开枪与向右开枪。
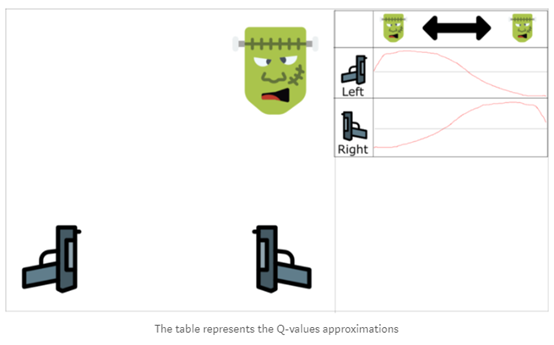
我们通过经验学习,如果击中怪兽,怪兽从相同方向过来的概率为70%,在这个例子中,这就是我们经验元组的相关性。
开始训练,agent看到怪兽在右边,并且使用右边的抢开枪,正确!然后,下一个怪兽也从右边经过(70%概率),并且agent同样朝右开枪,再一次答对了!
然后。。。
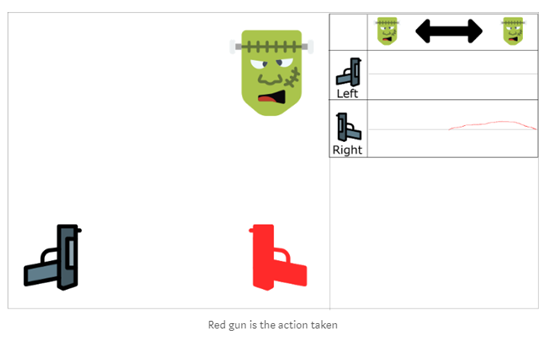
问题在于这个方法增加了朝右开枪的评估值。
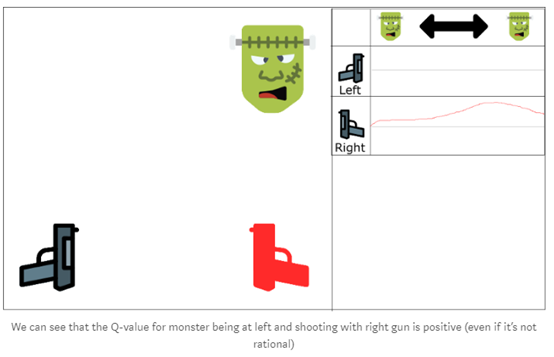
如果agent无法看到足够多的左边的例子(30%概率),那么agent将认为朝右开枪始终是对的,而不关心其他的因素。
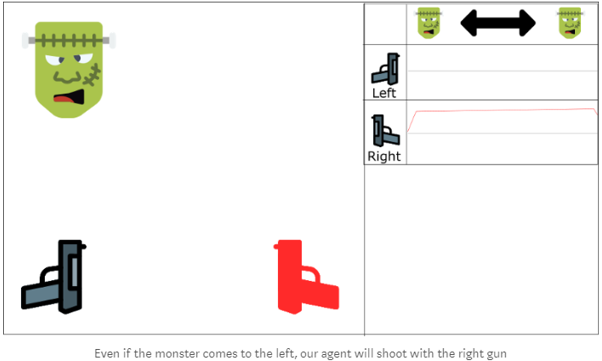
我们有两种平行策略去解决这一问题。
首先,必须停止从环境的交互中学习,开始尝试不同的方法,采用些随机发现的状态空间。并将结果保存至回放缓存中。
之后,可以调用这些经验,并从其中学习,返回并更新值函数。
最后,将获得一组更好的样例,可以从其中获得更好的泛化模式。
这会避免agent陷于状态空间的某个区域之中,防止某个行为的循环强化。
这个方法可以认为是一种监督学习,在未来的文章中,我们可以看到使用优先经验回放概念的想法,这将使神经网络更频繁的获得“重要”或“稀有”的动作样本。
深度Q学习算法
首先,我们需要了解下数学公式:回忆下Q函数的更新方法(Bellman equation):
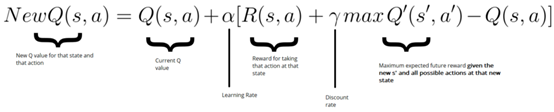
在此次例子中,我们希望更新网络的权重以减少误差。
误差(TD误差)通过计算Q_target(下一个时刻的最大可能值)与当前状态下预测得到的Q-value间的差值来获得。

在算法中,出现了两种处理过程。
1、 对环境采样,并且将观察到的信息存储于回放缓存中。
2、 随机选取一组小batch,并使用梯度下降方法进行迭代学习。
实现深度Q学习
此处有一个作者制作的视频【8】,基于tensorflow创建一个会玩Atari Space Invaders的agent。
现在我们知道强化学习是如何工作的了,我们将一步步实现我们自己的深度Q学习模型。每一步的代码都可以在下文中的Jupyter上面查看。
全部文档及代码见链接【9】。






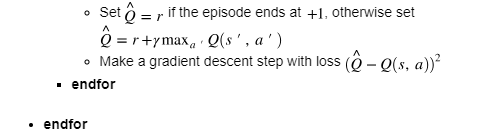

以上便是深度Q学习构建的全部内容了。在下一章中,将介绍深度Q学习的各类变体。
Fixed Q-values
Prioritized Experience Replay
Double DQN
Dueling Networks
[1] https://medium.freecodecamp.org/diving-deeper-into-reinforcement-learning-with-q-learning-c18d0db58efe
[2] https://simoninithomas.github.io/Deep_reinforcement_learning_Course/
[3] https://medium.com/@awjuliani
[4] https://medium.com/emergent-future/simple-reinforcement-learning-with-tensorflow-part-8-asynchronous-actor-critic-agents-a3c-c88f72a5e9f2
[5] http://colah.github.io/posts/2015-08-Understanding-LSTMs/
[6] https://medium.com/@ageitgey/machine-learning-is-fun-part-3-deep-learning-and-convolutional-neural-networks-f40359318721
[7] https://mp.weixin.qq.com/s?__biz=MzU2OTA0NzE2NA==&mid=2247491116&idx=1&sn=74dbd582e6fd0e5a9bd54c28187195dd&chksm=fc85ff3fcbf27629bdd356e0439258ea52f0cacd8390cce24b3c5d516684e2af296b7b2ebccf#rd
[8] https://youtu.be/gCJyVX98KJ4
[9] https://github.com/simoninithomas/Deep_reinforcement_learning_Course/tree/master/DQN/doom
原文链接:
https://medium.freecodecamp.org/an-introduction-to-deep-q-learning-lets-play-doom-54d02d8017d8
-END-
专 · 知
人工智能领域26个主题知识资料全集获取与加入专知人工智能服务群: 欢迎微信扫一扫加入专知人工智能知识星球群,获取专业知识教程视频资料和与专家交流咨询!

请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请加专知小助手微信(扫一扫如下二维码添加),加入专知主题群(请备注主题类型:AI、NLP、CV、 KG等)交流~

请关注专知公众号,获取人工智能的专业知识!
点击“阅读原文”,使用专知
展开全文



