【专知荟萃21】视觉问答VQA知识资料全集(入门/进阶/论文/综述/视频/专家,附查看)
点击上方“专知”关注获取专业AI知识!

【导读】主题荟萃知识是专知的核心功能之一,为用户提供AI领域系统性的知识学习服务。主题荟萃为用户提供全网关于该主题的精华(Awesome)知识资料收录整理,使得AI从业者便捷学习和解决工作问题!在专知人工智能主题知识树基础上,主题荟萃由专业人工编辑和算法工具辅助协作完成,并保持动态更新!另外欢迎对此创作主题荟萃感兴趣的同学,请加入我们专知AI创作者计划,共创共赢! 今天专知为大家呈送第二十一篇专知主题荟萃-视觉问答(Visual Question Answering)知识资料大全集荟萃 (入门/进阶/综述/视频/代码/专家等),请大家查看!专知访问www.zhuanzhi.ai, 或关注微信公众号后台回复" 专知"进入专知,搜索主题“视觉问答”查看。此外,我们也提供该文网页桌面手机端(www.zhuanzhi.ai)完整访问,可直接点击访问收录链接地址,以及pdf版下载链接,请文章末尾查看!此为初始版本,请大家指正补充,欢迎在后台留言!欢迎大家分享转发~
入门学习
进阶论文
Attention-Based
Knowledge-based
Memory Network
Video QA
综述
Tutorial
Dataset
Code
领域专家
视觉问答(Visual Question Answering,VQA)专知荟萃
入门学习
基于深度学习的VQA(视觉问答)技术
[https://zhuanlan.zhihu.com/p/22530291]
视觉问答全景概述:从数据集到技术方法
论文读书笔记(Multimodal Compact Bilinear Pooling for Visual Question Answering and Visual Grounding)
[http://www.jianshu.com/p/5bf03d1fadfa]
能看图回答问题的AI离我们还有多远?Facebook向视觉对话进发
[https://www.leiphone.com/news/201711/4B9cNlCINsVyPdTw.html]
图像问答Image Question Answering
[http://www.cnblogs.com/ranjiewen/p/7604468.html]
实战深度学习之图像问答
[https://zhuanlan.zhihu.com/p/20899091]
2017 VQA Challenge 第一名技术报告
[https://zhuanlan.zhihu.com/p/29688475]
深度学习为视觉和语言之间搭建了一座桥梁
[http://www.msra.cn/zh-cn/news/features/vision-and-language-20170713]
进阶论文
Kushal Kafle, and Christopher Kanan. Visual question answering: Datasets, algorithms, and future challenges. Computer Vision and Image Understanding [2017].
[https://arxiv.org/abs/1610.01465]
Justin Johnson, Bharath Hariharan, Laurens van der Maaten, Li Fei-Fei, C. Lawrence Zitnick, Ross Girshick, CLEVR: A Diagnostic Dataset for Compositional Language and Elementary Visual Reasoning, CVPR 2017.
[http://vision.stanford.edu/pdf/johnson2017cvpr.pdf]
Justin Johnson, Bharath Hariharan, Laurens van der Maaten, Judy Hoffman, Li Fei-Fei, C. Lawrence Zitnick, Ross Girshick, Inferring and Executing Programs for Visual Reasoning, arXiv:1705.03633, 2017. [https://arxiv.org/abs/1705.03633]
Ronghang Hu, Jacob Andreas, Marcus Rohrbach, Trevor Darrell, Kate Saenko, Learning to Reason: End-to-End Module Networks for Visual Question Answering, arXiv:1704.05526, 2017. [https://arxiv.org/abs/1704.05526]
Adam Santoro, David Raposo, David G.T. Barrett, Mateusz Malinowski, Razvan Pascanu, Peter Battaglia, Timothy Lillicrap, A simple neural network module for relational reasoning, arXiv:1706.01427, 2017. [https://arxiv.org/abs/1706.01427]
Hedi Ben-younes, Remi Cadene, Matthieu Cord, Nicolas Thome: MUTAN: Multimodal Tucker Fusion for Visual Question Answering [https://arxiv.org/pdf/1705.06676.pdf] [https://github.com/Cadene/vqa.pytorch]
Vahid Kazemi, Ali Elqursh, Show, Ask, Attend, and Answer: A Strong Baseline For Visual Question Answering, arXiv:1704.03162, 2016. [https://arxiv.org/abs/1704.03162] [https://github.com/Cyanogenoid/pytorch-vqa]
Kushal Kafle, and Christopher Kanan. An Analysis of Visual Question Answering Algorithms. arXiv:1703.09684, 2017. [https://arxiv.org/abs/1703.09684]
Hyeonseob Nam, Jung-Woo Ha, Jeonghee Kim, Dual Attention Networks for Multimodal Reasoning and Matching, arXiv:1611.00471, 2016. [https://arxiv.org/abs/1611.00471]
Jin-Hwa Kim, Kyoung Woon On, Jeonghee Kim, Jung-Woo Ha, Byoung-Tak Zhang, Hadamard Product for Low-rank Bilinear Pooling, arXiv:1610.04325, 2016. [https://arxiv.org/abs/1610.04325]
Akira Fukui, Dong Huk Park, Daylen Yang, Anna Rohrbach, Trevor Darrell, Marcus Rohrbach, Multimodal Compact Bilinear Pooling for Visual Question Answering and Visual Grounding, arXiv:1606.01847, 2016. [https://arxiv.org/abs/1606.01847] [https://github.com/akirafukui/vqa-mcb]
Kuniaki Saito, Andrew Shin, Yoshitaka Ushiku, Tatsuya Harada, DualNet: Domain-Invariant Network for Visual Question Answering. arXiv:1606.06108v1, 2016. [https://arxiv.org/pdf/1606.06108.pdf]
Arijit Ray, Gordon Christie, Mohit Bansal, Dhruv Batra, Devi Parikh, Question Relevance in VQA: Identifying Non-Visual And False-Premise Questions, arXiv:1606.06622, 2016. [https://arxiv.org/pdf/1606.06622v1.pdf]
Hyeonwoo Noh, Bohyung Han, Training Recurrent Answering Units with Joint Loss Minimization for VQA, arXiv:1606.03647, 2016. [http://arxiv.org/abs/1606.03647v1]
Jiasen Lu, Jianwei Yang, Dhruv Batra, Devi Parikh, Hierarchical Question-Image Co-Attention for Visual Question Answering, arXiv:1606.00061, 2016. [https://arxiv.org/pdf/1606.00061v2.pdf] [https://github.com/jiasenlu/HieCoAttenVQA]
Jin-Hwa Kim, Sang-Woo Lee, Dong-Hyun Kwak, Min-Oh Heo, Jeonghee Kim, Jung-Woo Ha, Byoung-Tak Zhang, Multimodal Residual Learning for Visual QA, arXiv:1606.01455, 2016. [https://arxiv.org/pdf/1606.01455v1.pdf]
Peng Wang, Qi Wu, Chunhua Shen, Anton van den Hengel, Anthony Dick, FVQA: Fact-based Visual Question Answering, arXiv:1606.05433, 2016. [https://arxiv.org/pdf/1606.05433.pdf]
Ilija Ilievski, Shuicheng Yan, Jiashi Feng, A Focused Dynamic Attention Model for Visual Question Answering, arXiv:1604.01485. [https://arxiv.org/pdf/1604.01485v1.pdf]
Yuke Zhu, Oliver Groth, Michael Bernstein, Li Fei-Fei, Visual7W: Grounded Question Answering in Images, CVPR 2016. [http://arxiv.org/abs/1511.03416]
Hyeonwoo Noh, Paul Hongsuck Seo, and Bohyung Han, Image Question Answering using Convolutional Neural Network with Dynamic Parameter Prediction, CVPR, 2016.[http://arxiv.org/pdf/1511.05756.pdf]
Jacob Andreas, Marcus Rohrbach, Trevor Darrell, Dan Klein, Learning to Compose Neural Networks for Question Answering, NAACL 2016. [http://arxiv.org/pdf/1601.01705.pdf]
Jacob Andreas, Marcus Rohrbach, Trevor Darrell, Dan Klein, Deep compositional question answering with neural module networks, CVPR 2016. [https://arxiv.org/abs/1511.02799]
Zichao Yang, Xiaodong He, Jianfeng Gao, Li Deng, Alex Smola, Stacked Attention Networks for Image Question Answering, CVPR 2016. [http://arxiv.org/abs/1511.02274] [https://github.com/JamesChuanggg/san-torch]
Kevin J. Shih, Saurabh Singh, Derek Hoiem, Where To Look: Focus Regions for Visual Question Answering, CVPR, 2015. [http://arxiv.org/pdf/1511.07394v2.pdf]
Kan Chen, Jiang Wang, Liang-Chieh Chen, Haoyuan Gao, Wei Xu, Ram Nevatia, ABC-CNN: An Attention Based Convolutional Neural Network for Visual Question Answering, arXiv:1511.05960v1, Nov 2015. [http://arxiv.org/pdf/1511.05960v1.pdf]
Huijuan Xu, Kate Saenko, Ask, Attend and Answer: Exploring Question-Guided Spatial Attention for Visual Question Answering, arXiv:1511.05234v1, Nov 2015. [http://arxiv.org/abs/1511.05234]
Kushal Kafle and Christopher Kanan, Answer-Type Prediction for Visual Question Answering, CVPR 2016. [http://www.cv-foundation.org/openaccess/content_cvpr_2016/html/Kafle_Answer-Type_Prediction_for_CVPR_2016_paper.html]
Stanislaw Antol, Aishwarya Agrawal, Jiasen Lu, Margaret Mitchell, Dhruv Batra, C. Lawrence Zitnick, Devi Parikh, VQA: Visual Question Answering, ICCV, 2015. [http://arxiv.org/pdf/1505.00468]
Stanislaw Antol, Aishwarya Agrawal, Jiasen Lu, Margaret Mitchell, Dhruv Batra, C. Lawrence Zitnick, Devi Parikh, VQA: Visual Question Answering, ICCV, 2015. [http://arxiv.org/pdf/1505.00468] [https://github.com/JamesChuanggg/VQA-tensorflow]
Bolei Zhou, Yuandong Tian, Sainbayar Sukhbaatar, Arthur Szlam, Rob Fergus, Simple Baseline for Visual Question Answering, arXiv:1512.02167v2, Dec 2015. [http://arxiv.org/abs/1512.02167]
Hauyuan Gao, Junhua Mao, Jie Zhou, Zhiheng Huang, Lei Wang, Wei Xu, Are You Talking to a Machine? Dataset and Methods for Multilingual Image Question Answering, NIPS 2015. [http://arxiv.org/pdf/1505.05612.pdf]
Mateusz Malinowski, Marcus Rohrbach, Mario Fritz, Ask Your Neurons: A Neural-based Approach to Answering Questions about Images, ICCV 2015. [http://arxiv.org/pdf/1505.01121v3.pdf]
Mengye Ren, Ryan Kiros, Richard Zemel, Exploring Models and Data for Image Question Answering, ICML 2015. [http://arxiv.org/pdf/1505.02074.pdf]
Mateusz Malinowski, Mario Fritz, Towards a Visual Turing Challe, NIPS Workshop 2015. [http://arxiv.org/abs/1410.8027]
Mateusz Malinowski, Mario Fritz, A Multi-World Approach to Question Answering about Real-World Scenes based on Uncertain Input, NIPS 2014. [http://arxiv.org/pdf/1410.0210v4.pdf]
Attention-Based
Hedi Ben-younes, Remi Cadene, Matthieu Cord, Nicolas Thome: MUTAN: Multimodal Tucker Fusion for Visual Question Answering [https://arxiv.org/pdf/1705.06676.pdf] [https://github.com/Cadene/vqa.pytorch]
Jin-Hwa Kim, Kyoung Woon On, Jeonghee Kim, Jung-Woo Ha, Byoung-Tak Zhang, Hadamard Product for Low-rank Bilinear Pooling, arXiv:1610.04325, 2016. [https://arxiv.org/abs/1610.04325]
Akira Fukui, Dong Huk Park, Daylen Yang, Anna Rohrbach, Trevor Darrell, Marcus Rohrbach, Multimodal Compact Bilinear Pooling for Visual Question Answering and Visual Grounding, arXiv:1606.01847, 2016. [https://arxiv.org/abs/1606.01847]
Hyeonwoo Noh, Bohyung Han, Training Recurrent Answering Units with Joint Loss Minimization for VQA, arXiv:1606.03647, 2016. [http://arxiv.org/abs/1606.03647v1]
Jiasen Lu, Jianwei Yang, Dhruv Batra, Devi Parikh, Hierarchical Question-Image Co-Attention for Visual Question Answering, arXiv:1606.00061, 2016. [https://arxiv.org/pdf/1606.00061v2.pdf]
Zichao Yang, Xiaodong He, Jianfeng Gao, Li Deng, Alex Smola, Stacked Attention Networks for Image Question Answering, CVPR 2016. [http://arxiv.org/abs/1511.02274]
Ilija Ilievski, Shuicheng Yan, Jiashi Feng, A Focused Dynamic Attention Model for Visual Question Answering, arXiv:1604.01485. [https://arxiv.org/pdf/1604.01485v1.pdf]
Kan Chen, Jiang Wang, Liang-Chieh Chen, Haoyuan Gao, Wei Xu, Ram Nevatia, ABC-CNN: An Attention Based Convolutional Neural Network for Visual Question Answering, arXiv:1511.05960v1, Nov 2015. [http://arxiv.org/pdf/1511.05960v1.pdf]
Huijuan Xu, Kate Saenko, Ask, Attend and Answer: Exploring Question-Guided Spatial Attention for Visual Question Answering, arXiv:1511.05234v1, Nov 2015. [http://arxiv.org/abs/1511.05234]
Knowledge-based
Peng Wang, Qi Wu, Chunhua Shen, Anton van den Hengel, Anthony Dick, FVQA: Fact-based Visual Question Answering, arXiv:1606.05433, 2016. [https://arxiv.org/pdf/1606.05433.pdf]
Qi Wu, Peng Wang, Chunhua Shen, Anton van den Hengel, Anthony Dick, Ask Me Anything: Free-form Visual Question Answering Based on Knowledge from External Sources, CVPR 2016. [http://arxiv.org/abs/1511.06973]
Peng Wang, Qi Wu, Chunhua Shen, Anton van den Hengel, Anthony Dick, Explicit Knowledge-based Reasoning for Visual Question Answering, arXiv:1511.02570v2, Nov 2015. [http://arxiv.org/abs/1511.02570]
Yuke Zhu, Ce Zhang, Christopher Re,́ Li Fei-Fei, Building a Large-scale Multimodal Knowledge Base System for Answering Visual Queries, arXiv:1507.05670, Nov 2015. [http://arxiv.org/abs/1507.05670]
Memory Network
Caiming Xiong, Stephen Merity, Richard Socher, Dynamic Memory Networks for Visual and Textual Question Answering, ICML 2016. [http://arxiv.org/abs/1603.01417]
Aiwen Jiang, Fang Wang, Fatih Porikli, Yi Li, Compositional Memory for Visual Question Answering, arXiv:1511.05676v1, Nov 2015. [http://arxiv.org/abs/1511.05676]
Video QA
Kuo-Hao Zeng, Tseng-Hung Chen, Ching-Yao Chuang, Yuan-Hong Liao, Juan Carlos Niebles, Min Sun, Leveraging Video Descriptions to Learn Video Question Answering, AAAI 2017. [https://arxiv.org/abs/1611.04021]
Makarand Tapaswi, Yukun Zhu, Rainer Stiefelhagen, Antonio Torralba, Raquel Urtasun, Sanja Fidler, MovieQA: Understanding Stories in Movies through Question-Answering, CVPR 2016. [http://arxiv.org/abs/1512.02902]
Linchao Zhu, Zhongwen Xu, Yi Yang, Alexander G. Hauptmann, Uncovering Temporal Context for Video Question and Answering, arXiv:1511.05676v1, Nov 2015. [http://arxiv.org/abs/1511.04670]
综述
Qi Wu, Damien Teney, Peng Wang, Chunhua Shen, Anthony Dick, and Anton van den Hengel. Visual question answering: A survey of methods and datasets. Computer Vision and Image Understanding [2017].
[https://arxiv.org/abs/1607.05910]
Tutorial on Answering Questions about Images with Deep Learning Mateusz Malinowski, Mario Fritz
[https://arxiv.org/abs/1610.01076]
Survey of Visual Question Answering: Datasets and Techniques
[https://arxiv.org/abs/1705.03865]
Visual Question Answering: Datasets, Algorithms, and Future Challenges
[https://arxiv.org/abs/1610.01465]
Tutorial
CVPR 2017 VQA Challenge Workshop (有很多PPT)
[http://www.visualqa.org/workshop.html]
CVPR 2016 VQA Challenge Workshop
[http://www.visualqa.org/vqa_v1_workshop.html\]
Tutorial on Answering Questions about Images with Deep Learning
[https://arxiv.org/pdf/1610.01076.pdf]
Visual Question Answering Demo in Python Notebook
[http://iamaaditya.github.io/2016/04/visual_question_answering_demo_notebook\]
Tutorial on Question Answering about Images
[https://www.linkedin.com/pulse/tutorial-question-answering-images-mateusz-malinowski/]
Dataset
Visual7W: Grounded Question Answering in Images
homepage: http://web.stanford.edu/~yukez/visual7w/
github: https://github.com/yukezhu/visual7w-toolkit
github: https://github.com/yukezhu/visual7w-qa-models
DAQUAR
[http://www.cs.toronto.edu/~mren/imageqa/results/\]
COCO-QA
[http://www.cs.toronto.edu/~mren/imageqa/data/cocoqa/\]
The VQA Dataset
[http://visualqa.org/]
FM-IQA
[http://idl.baidu.com/FM-IQA.html]
Visual Genome
[http://visualgenome.org/]
Code
VQA Demo: Visual Question Answering Demo on pretrained model
[https://github.com/iamaaditya/VQA_Demo]
[http://iamaaditya.github.io/research/]
deep-qa: Implementation of the Convolution Neural Network for factoid QA on the answer sentence selection task
[https://github.com/aseveryn/deep-qa]
YodaQA: A Question Answering system built on top of the Apache UIMA framework
[http://ailao.eu/yodaqa/]
[https://github.com/brmson/yodaqa]
insuranceQA-cnn-lstm: tensorflow and theano cnn code for insurance QA
[https://github.com/white127/insuranceQA-cnn-lstm]
Tensorflow Implementation of Deeper LSTM+ normalized CNN for Visual Question Answering
[https://github.com/JamesChuanggg/VQA-tensorflow]
Visual Question Answering with Keras
[https://anantzoid.github.io/VQA-Keras-Visual-Question-Answering/]
Deep Learning Models for Question Answering with Keras
[http://sujitpal.blogspot.jp/2016/10/deep-learning-models-for-question.html]
Deep QA: Using deep learning to answer Aristo's science questions
[https://github.com/allenai/deep_qa]
Visual Question Answering in Pytorch
[https://github.com/Cadene/vqa.pytorch]
领域专家
Qi Wu
[https://researchers.adelaide.edu.au/profile/qi.wu01]
Bolei Zhou 周博磊
[http://people.csail.mit.edu/bzhou/]
Stanislaw Antol
[https://computing.ece.vt.edu/~santol/\]
Jin-Hwa Kim
[https://bi.snu.ac.kr/~jhkim/\]
Vahid Kazemi
[http://www.csc.kth.se/~vahidk/index.html\]
Justin Johnson
[http://cs.stanford.edu/people/jcjohns/]
Ilija Ilievski
[https://ilija139.github.io/]
初步版本,水平有限,有错误或者不完善的地方,欢迎大家提建议和补充(到专知网站www.zhuanzhi.ai 主题下评论),会一直保持更新,敬请关注http://www.zhuanzhi.ai 和关注专知公众号,获取最新AI相关知识。
特别提示-专知视觉问答主题:
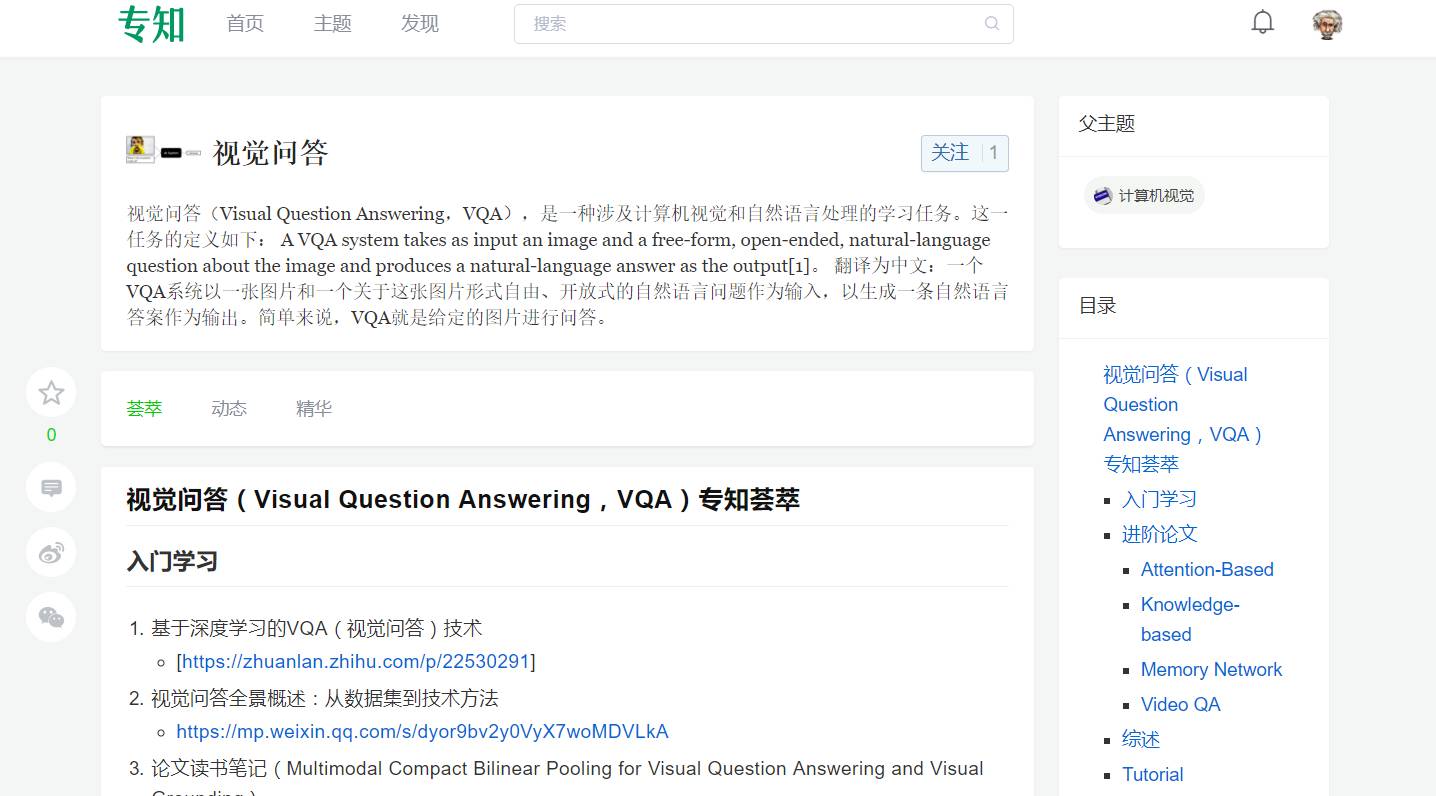
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录,顶端搜索“视觉问答” 主题,查看评论获得专知荟萃全集知识等资料,直接PC端访问体验更佳!如下图所示~
此外,请关注专知公众号(扫一扫最下面专知二维码,或者点击上方蓝色专知),
后台回复“视觉问答”或者“VQA” 就可以在手机端获取专知视觉问答资料查看链接地址,直接打开荟萃资料的链接地址~~
请扫描专知小助手,加入专知人工智能群交流~

往期专知荟萃知识资料全集获取(关注本公众号-专知,获取下载链接),请查看:
【专知荟萃01】深度学习知识资料大全集(入门/进阶/论文/代码/数据/综述/领域专家等)(附pdf下载)
【专知荟萃02】自然语言处理NLP知识资料大全集(入门/进阶/论文/Toolkit/数据/综述/专家等)(附pdf下载)
【专知荟萃03】知识图谱KG知识资料全集(入门/进阶/论文/代码/数据/综述/专家等)(附pdf下载)
【专知荟萃04】自动问答QA知识资料全集(入门/进阶/论文/代码/数据/综述/专家等)(附pdf下载)
【专知荟萃05】聊天机器人Chatbot知识资料全集(入门/进阶/论文/软件/数据/专家等)(附pdf下载)
【专知荟萃06】计算机视觉CV知识资料大全集(入门/进阶/论文/课程/会议/专家等)(附pdf下载)
【专知荟萃07】自动文摘AS知识资料全集(入门/进阶/代码/数据/专家等)(附pdf下载)
【专知荟萃08】图像描述生成Image Caption知识资料全集(入门/进阶/论文/综述/视频/专家等)
【专知荟萃09】目标检测知识资料全集(入门/进阶/论文/综述/视频/代码等)
【专知荟萃10】推荐系统RS知识资料全集(入门/进阶/论文/综述/视频/代码等)
【专知荟萃11】GAN生成式对抗网络知识资料全集(理论/报告/教程/综述/代码等)
【专知荟萃12】信息检索 Information Retrieval 知识资料全集(入门/进阶/综述/代码/专家,附PDF下载)
【专知荟萃13】工业学术界用户画像 User Profile 实用知识资料全集(入门/进阶/竞赛/论文/PPT,附PDF下载)
【专知荟萃14】机器翻译 Machine Translation知识资料全集(入门/进阶/综述/视频/代码/专家,附PDF下载)
【专知荟萃15】图像检索Image Retrieval知识资料全集(入门/进阶/综述/视频/代码/专家,附PDF下载)
【专知荟萃16】主题模型Topic Model知识资料全集(基础/进阶/论文/综述/代码/专家,附PDF下载)
【专知荟萃17】情感分析Sentiment Analysis 知识资料全集(入门/进阶/论文/综述/视频/专家,附查看)
【专知荟萃18】目标跟踪Object Tracking知识资料全集(入门/进阶/论文/综述/视频/专家,附查看)
【专知荟萃19】图像识别Image Recognition知识资料全集(入门/进阶/论文/综述/视频/专家,附查看)
【专知荟萃20】图像分割Image Segmentation知识资料全集(入门/进阶/论文/综述/视频/专家,附查看)
-END-
欢迎使用专知
专知,一个新的认知方式!专注在人工智能领域为AI从业者提供专业可信的知识分发服务, 包括主题定制、主题链路、搜索发现等服务,帮你又好又快找到所需知识。
使用方法>>访问www.zhuanzhi.ai, 或点击文章下方“阅读原文”即可访问专知
中国科学院自动化研究所专知团队
@2017 专知
专 · 知
关注我们的公众号,获取最新关于专知以及人工智能的资讯、技术、算法、深度干货等内容。扫一扫下方关注我们的微信公众号。


点击“阅读原文”,使用专知!
展开全文



