【前沿】用AlphaGo Zero方法实现增强学习下棋
点击上方“专知”关注获取专业AI知识!

【导读】Google DeepMind AlphaGo团队在Nature上发表两篇论文《Mastering the game of Go without Human Knowledge》 和《Mastering the game of Go with deep neural networks and tree search》,这两篇划时代的论文,将成为永恒经典,在第一篇文章中,其介绍了迄今最强最新的版本AlphaGo Zero,不使用人类先验知识,使用纯强化学习,将价值网络和策略网络整合为一个架构,3天训练后就以100比0击败了上一版本的AlphaGo。近期,Samuel Graván使用Keras/TensorFlow实现了用AlphaGo Zero方法实现增强学习下棋,让我们来看下。
▌前言
视频
先看下Google DeepMind 研究人员David Silver介绍 AlphaGo Zero:
论文
Mastering the game of Go without Human Knowledge
不使用人类知识
摘要
长久以来,人工智能的目标是在富有挑战性的领域中学习出一种从无知幼儿到超级专家的算法。最近,AlphaGo成为了在围棋游戏中打败人类世界冠军的第一个程序。其中,AlphaGo对下棋位置的预估和选定下棋位置所使用的树搜索算法使用了神经网络。这些网络利用高段位棋手的走棋通过有监督学习的方式来训练,然后通过自我对弈来完成进行增强学习。本篇论文中我们提出了一种完全独立的增强学习算法,算法不需要人工数据,或是基于游戏规则的引导或领域知识。AlphaGo变成了自己的老师:训练一个神经网络用来完成AlphaGo的落子预测和对弈的赢家。这个网络同时还提高了树搜索的能力,带来的结果就是能够在下一手中有更高质量的落子选择和更强的自我对弈能力。从无知幼儿开始,我们新的程序—AlphaGo Zero达到了超级专家的水平,在与之前开发的AlphaGo(指代和李世石对弈的AlphaGo)的对弈中,取得了100-0的完胜。

▌Github实现代码
用AlphaGo Zero方法实现增强学习下棋
关于 (Keras/TensorFlow)
用AlphaGo Zero方法实现增强学习下棋
本工程主要基于下面两项研究:
DeepMind的10月19号的期刊:Mastering the Game of Go without Human Knowledge
@mokemokechicken在他的repo中做的对DeepMind想法的扩展: https://github.com/mokemokechicken/reversi-alpha-zero
注:该项目仍在建设中!!
环境
Python 3.6.3
tensorflow-gpu: 1.3.0
Keras: 2.0.8
模块
强化学习
AlphaGo Zero接口的实现包含三个变量 self , opt , eval.
self 是通过使用最佳模型(BestModel)自我生成训练数据。
opt 是训练模型的训练器(Trainer ),并生成下一代模型。
eval 是评估器(Evaluator )评估下一代模型是否比BestModel好。如果更好,则替换BestModel。
评估
在评估阶段,你可以用最佳模型(BestModel)下象棋。
数据
data/model/model_best_*: BestModel(最佳模型).
data/model/next_generation/*: next-generation models.(下一代模型)
data/play_data/play_*.json: generated training data(生成的训练数据).
logs/main.log: log file(日志文件).
如果你想从一开始就自己训练模型,就删除上面的目录。
如何使用
安装:
安装库: pip install -r requirements.txt
如果想使用GPU,用下面的语句: pip install tensorflow-gpu
设置环境变量: 创建 .env 文件, 并写文件如下: KERAS_BACKEND=tensorflow
基本用法
对于训练模型,执行Self-Play, Trainer 和 Evaluator
Self-Play
python src/chess_zero/run.py self 当执行上述语句时,Self-Play将开始使用最佳模式。如果最好的模型不存在,那么将创建新的随机模型作为最好的模型。
选项设置
--new: 创建新的最佳模型(BestModel)
--type mini: 为测试使用最小配置 (see src/chess_zero/configs/mini.py)
Trainer
python src/chess_zero/run.py opt
当执行训练器的时候,则开始训练。将从最新保存的下一代模型加在基础模型。如果不存在,则使用最佳模型。训练模型每隔2000次迭代(mini-batch)保存一次。
Trainer 选项设置
--type mini: 使用最小配置进行测试。( src/chess_zero/configs/mini.py)
--total-step: 指定mini-batch总数。mini-batch会影响模型训练的学习速度。
Evaluator
python src/chess_zero/run.py eval
在执行时,评估开始。在进行到200次时,评估BestModel和最近一次的模型。如果下一代模型获胜, 下一代模型就当作BestModel。
Play Game
python src/chess_zero/run.py play_gui
当执行的时候,普通国际象棋棋盘将会显示在ASCII码中,你可以与最好的模型(BestModel)下棋。
技巧和备忘录
GPU 内存
通常情况下,会有内存不足引起的警告,而不是错误。如果发生了错误, 可以尝试改变 src/worker/{evaluate.py,optimize.py,self_play.py}中的 per_process_gpu_memory_fraction 如下语句:
tf_util.set_session_config(per_process_gpu_memory_fraction=0.2)
较少的batch_size 将会减少opt的内存使用,尝试改变NormalConfig中的TrainerConfig #batch_size。
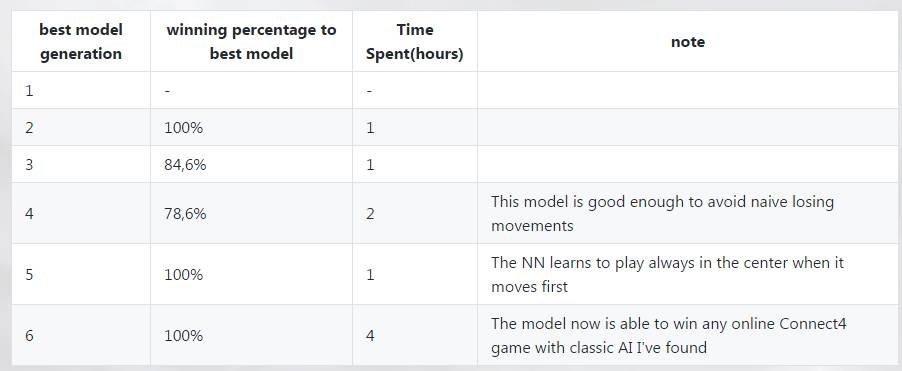
模型性能
下表是最好的模型的记录。
参考文献
文章链接:https://www.nature.com/articles/nature24270
Github代码:https://github.com/Zeta36/chess-alpha-zero
-END-
专 · 知
人工智能领域主题知识资料查看获取:【专知荟萃集合】人工智能领域主题知识资料全集[ 持续更新中](入门/进阶/论文/综述/视频/专家等,附查看)
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!
请扫一扫关注专知公众号,获取人工智能的专业知识。

请扫描下方专知小助手,加入专知主题群(请备注主题类型:AI、NLP、CV、 KG等,或者加小助手咨询入群)交流~


点击“阅读原文”,使用专知!
展开全文



