【论文笔记】具有深度注意力网络的协同Bundle(项目组合)推荐
导读
随着深度学习技术的发展,出现了越来越多的推荐方法。但是,大多数推荐研究都集中在向用户推荐单个项目上,而在许多实际情况中,平台需要向用户显示一组项目,来进行捆绑销售。本文主要介绍在一个名为DAM(Deep Attentive Multi-Task)的推荐方法,旨在对用户与一组项目之间进行交互建模。

论文地址:
https://www.ijcai.org/proceedings/2019/0290.pdf
动机
在现实生活中,许多应用程序需要为用户推荐一套商品(例如旅行包,音乐播放列表),以供整体消费。因此需要构建 Bundle(项目组合) 推荐系统,预测用户对于一组商品的偏好。但是传统的将 “bundles ”视为多个“item”的协同过滤(CF)的方法存在如下两个缺点,不能很好的预测用户-bundle之间的交互。

图1 bundle推荐示例
1)项目组合(bundle)由多个(至少两个)项目组成,不能将bundles作为用户-bundles 矩阵中的单独列来运行诸如矩阵分解的协同过滤方法。
2)用户-bundle交互数据比用户-项目交互数据更加的稀疏。
3)利用传统的推荐方法,对于新的bundle很容易造成冷启动问题。
因此,作者提出了新的协同 bundle模型——深度注意力多任务模型(DAM),来解决上述传统CF算法进行bundles推荐的困难。
核心思想
深度注意力多任务模型(DAM)旨在通过适当地合并用户-项目交互矩阵H,从用户-bundle交互矩阵R中学习个性化bundle排名函数。主要包括两部分内容:1)首先通过分解注意力网络来得到用户对构成项目的偏好,并且聚合项目嵌入以形成bundles的嵌入表示(并未使用bundles商品ID进行嵌入);2)在得到bundle的embedding之后通过多任务学习(用户-bundle交互预测任务与用户-项目交互预测任务)的用户-bundle和用户-项目交互的联合建模,来聚合用户-项目交互,并且在联合模型中共享相同用户嵌入去预测用户-bundle交互与用户-项目交互,将一项任务(用户-项目建模)的收益转移到另一项任务( 用户-bundle模型)。
符号表示
用户:U={u_1,u_2,...u_N}
项目:V={v_1,v_2,.......v_M}
bundle:表示项目的组合(至少两个),B={b_1,b_2,......b_K}
i,j,s分别表示用户、项目、bundle的ID
每一组项目b_s表示为 G_s = {g_{s,1},g_{s,2},...,g_{s,| bs |}}
| bs | :表示bundle的大小(大于1)
H=[h_{i,j}]:用户-项目交互矩阵
R=[r_{i,s}]:-bundle交互矩阵
Factorized Attention Network
在Bundle推荐中,使用ID对bundle进行编码会使模型难以推广到新的bundle。因此,文中提出使用bundle的组成项目对bundle进行表示,即聚合项目嵌入v_j到bundle中来获得bundles上的嵌入。为了获得bundle中的组成项目在bundle中扮演的不同角色,文中设计了一种自适应加权和运算,将bundle 的 embedding 值b_s表示为:
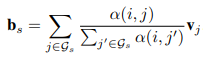
其中:
α(i, j)表示用户u_i考虑是否与bundle互动时项目v_j的权重
v_j为项目j的embedding
至此,在获得bundle的表示中最重要的就是获得权重α(i, j),之前的推荐算法(例如ACF中)是将多层感知机(MLP)放在用户嵌入与项目嵌入的上方,将α(i,j)估计为:
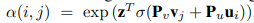
其中:
u_i表示用户u_i的embedding
P_u、P_v、z是MLP的参数
丨点击ACF查看ACF框架详解
但是,用户和项目之间的交互本质上是稀疏的,它们很可能遵循低维结构,而MLP的结构无法有效的学习用户-项目之间低维(乘法)关系,因此,作者提出了分解注意力网络(Factorized Attention Network),使用一个低维的模型来参数化α(i,j),即将注意力加权矩阵A = [α(i,j)]分解为低秩模型,然后进行softmax 运算。
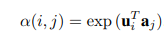
a_j称为项目注意向量,来表征v_j的向量
Joint User-Bundle and User-Item Model
在获得bundle表示之后,通过将用户embedding 与bundle embedding 送入映射函数 f_bundle 中可以得到用户-bundle预测模型:
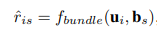
同样地,将用户embedding 与项目 embedding 送入映射函数 f_item 中可以得到用户-项目预测模型:
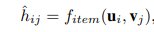
接下来的重点就是选择映射函数 f,文中作者选择使用NCF的框架,利用MLP作为映射函数,并且对于f_bundle与f_item使用两个MLP。
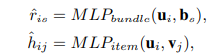
考虑到这两个任务共享相同的用户embedding u_i,作者认为这两个MLP的底层都是根据某些商品属性(例如价格,品牌,主题(或子类别)等)提取有关用户偏好的信号。因此,文中提出了如图2所示的联合建模架构,其中两个MLP的底层是共享的,高层是不同的,以针对特定任务。该体系结构的公式如下:
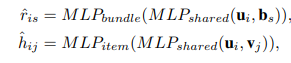
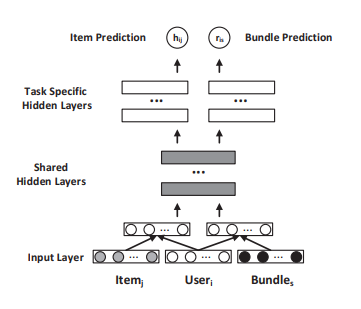
图2 联合建模架构
多任务学习
为了解决对于在u_i与b_s间没有交互(可能是用户不知道这个bundle的存在),而不能得出用户u_i对于b_s不感兴趣的问题,文中假设选择的项目组合比未选择的更可取(与ACF一样)。
作者采用了贝叶斯个性化排名(BPR)损失,联合模型的最终目标函数是两个预测任务的目标函数之和:
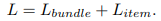
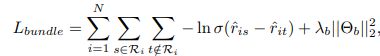
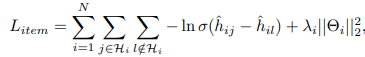
其中:
R_i,H_i分别表示用户u_i交互的所有bundle与item
(i,s)、(i,j)作为正例,(i,t)、(i,l)作为负例
σ(·) 是sigmoid函数
Θ_b、Θ__i是bundle预测任务的模型参数集。
L2正则化用于防止过度拟合
在每次迭代中,首先对用户u_i进行采样。然后,用成对的负样本(i,t)对正例(i,s)进行采样,并用成对的负样本(i,l)对正例(i,j)进行采样。然后执行两个梯度步骤以依次最小化L_bundle和L_item。重复执行以上步骤,直到收敛为止。
实验
数据集
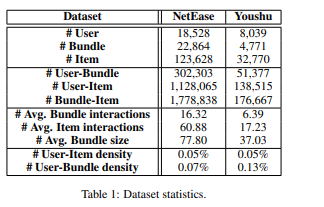
文中使用了NetEase 与 Youshu 这两个数据集
1)NetEase:是 从网易云音乐(Netease Cloud Music)抓取了数据,该数据使用户能够构建具有特定主题的歌曲列表。每个bundle由至少5个项目(即歌曲)组成,每个项目至少出现在5个bundle中,并且用户收听至少10个项目和10个bundle。
2) Youshu:是通过从中国书评网站的 Youshu 爬取数据而构建的。与网易类似,用户可以构建所需的书单。数据集的统计信息如表1所示。
评价指标
文中采用留一法评估方案。对于每个用户,用户的互动之一将被随机删除以进行测试。为了评估模型的前K个推荐性能,文中采用了基于相关性的度量– Recall @ K与基于排名的度量– MAP @ K。
实验设置
学习率:[0.01, 0.005, 0.001, 0.0005]
batch size:1024
优化器:Adam
L2正则化系数:[0.1, 0.01, 0.001, 0.0001]
embedding维度:10的效果更好
实验结果
为了展示DAM的性能,文中对比了BPR、NCF、BR、EFM等方法在不同的embedding维度下的性能,表2为这几种方法的TOPK推荐的性能比较。
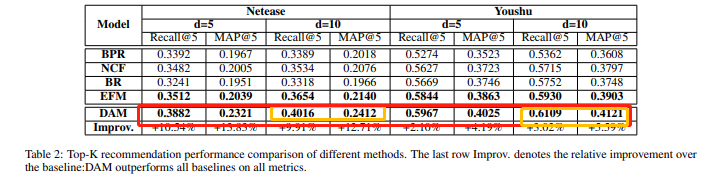
除了对比几个模型的性能外,文中还验证了因子注意力模型的有效性(图3)以及共享层数量对于实验结果的影响(表3)
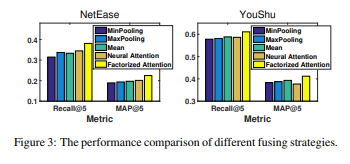
在图3中,尽管神经注意力和分解注意力都为用户学习动态权重,但是分解注意力取得了更好的性能,这表明分解注意力比神经注意力具有更好的泛化性能,通过低维结构来获取用户注意力是有效的。
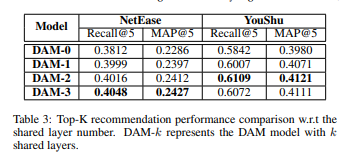
从表3中我们很明显可以看到增加共享层的层数可以获得更好地用户偏好建模以提高模型的性能,但是,太多的共享层可能会引入与bundle推荐无关的噪声,因此应该通过不同的推荐任务选取合适的共享层数。



展开全文



