春节充电系列:李宏毅2017机器学习课程学习笔记20之支持向量机(support vector machine)
【导读】我们在上一节的内容中已经为大家介绍了台大李宏毅老师的机器学习课程的迁移学习(transfer learning),这一节将主要针对讨论支持向量机(support vector machine)。本文内容涉及机器学习中support vector machine的若干主要问题:hinge loss,kernel method,radial basis function kernel和sigmoid kernel。话不多说,让我们一起学习这些内容吧。
春节充电系列:李宏毅2017机器学习课程学习笔记02之Regression
春节充电系列:李宏毅2017机器学习课程学习笔记03之梯度下降
春节充电系列:李宏毅2017机器学习课程学习笔记04分类(Classification)
春节充电系列:李宏毅2017机器学习课程学习笔记05之Logistic 回归
春节充电系列:李宏毅2017机器学习课程学习笔记06之深度学习入门
春节充电系列:李宏毅2017机器学习课程学习笔记07之反向传播(Back Propagation)
春节充电系列:李宏毅2017机器学习课程学习笔记08之“Hello World” of Deep Learning
春节充电系列:李宏毅2017机器学习课程学习笔记09之Tip for training DNN
春节充电系列:李宏毅2017机器学习课程学习笔记10之卷积神经网络
春节充电系列:李宏毅2017机器学习课程学习笔记11之Why Deep Learning?
春节充电系列:李宏毅2017机器学习课程学习笔记12之半监督学习(Semi-supervised Learning)
春节充电系列:李宏毅2017机器学习课程学习笔记13之无监督学习:主成分分析(PCA)
春节充电系列:李宏毅2017机器学习课程学习笔记14之无监督学习:词嵌入表示(Word Embedding)
春节充电系列:李宏毅2017机器学习课程学习笔记15之无监督学习:Neighbor Embedding
春节充电系列:李宏毅2017机器学习课程学习笔记16之无监督学习:自编码器(autoencoder)
春节充电系列:李宏毅2017机器学习课程学习笔记17之深度生成模型:deep generative model part 1
春节充电系列:李宏毅2017机器学习课程学习笔记18之深度生成模型:deep generative model part 2
春节充电系列:李宏毅2017机器学习课程学习笔记19之迁移学习(Transfer Learning)
课件网址:
http://speech.ee.ntu.edu.tw/~tlkagk/courses_ML17_2.html
http://speech.ee.ntu.edu.tw/~tlkagk/courses_ML17.html
视频网址:
https://www.bilibili.com/video/av15889450/index_1.html
李宏毅机器学习笔记20 支持向量机(support vector machine)
我们在上一节的内容中已经为大家介绍了台大李宏毅老师的机器学习课程的transfer learning,这一节将主要针对讨论support vector machine。本文内容涉及机器学习中support vector machine的若干主要问题:hinge loss,kernel method,radial basis function kernel和sigmoid kernel。话不多说,让我们一起学习这些内容吧
1.hinge loss
支持向量机主要由两部分组成,一个是hinge loss,一个是kernel method。
回顾之前的二分类问题,我们是采用三步来解决这个问题

有很多loss function的方法
Sigmoid + cross entropy 和sigmoid loss对待不正确位置的态度的不同。结果越不正确,sigmoid cross entropy梯度越,然而sigmoid loss梯度越小。
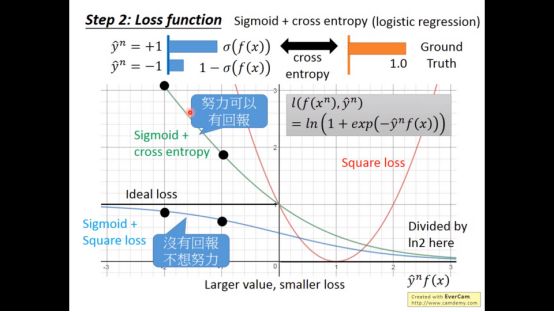
Hinge loss 和sigmoid +cross entropy 最大的不同是对于好的example态度的不同。Sigmoid+cross entropy是好还要更好,hinge loss 要求及格就行。
于是linear SVM三步模型如下图所示

对于SVM使用梯度下降是可以的得到解的

但SVM还可以用别的方法来解。下图红色方框上下式子不一样

但加了minimizing后,上下两个式子是一模一样的,这时候这个问题变成了一个quadratic programming problem。可以用quadratic programming solver解出来

2.kernel method
再看kernel
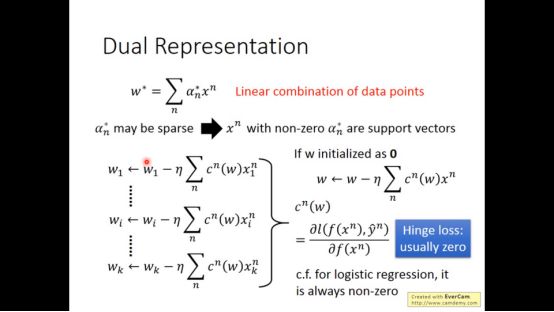
事实上,每个参数w是x的线性组合,怎么证明呢。看梯度下降公式,让w初始化为0,结果就很明显了。
回到step1,将w带入其中,可以得到下图式子。其中K就是kernel
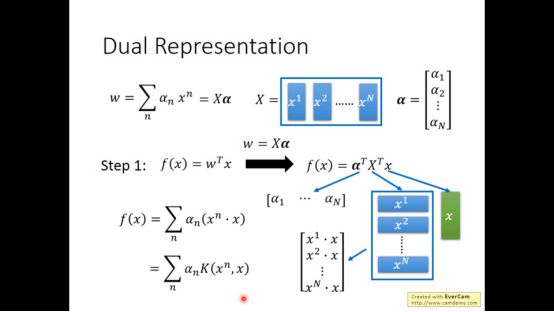
继续代入

这样的好处就是不需要真正知道x,只需要知道x和z的内积。这叫做kernel trick。

φ(x)是x做linear transformation后的结果, ,将k维投影到更高维,每个维度考虑所有feature两两之间的关系。

3.radial basis function kernel
而(x·z)^2可以直接表示feature transformation+inner product,kernel trick更简单更快。
当然K(x·z)不仅仅能表示inner product,还能表示成别的函数的形式

这个kernel衡量x和z之间的相似度,其中φ有无穷多维

4.sigmoid kernel
K(x·z)为tanh(x·z)时就成了sigmoid kernel
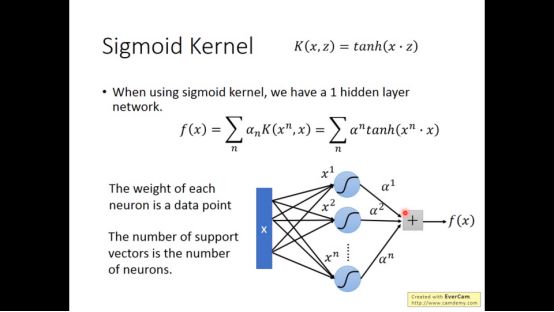
Kernel trick的好处就是可以直接去设计kernel function不用考虑x和z的feature长什么样

SVM还有其他变形

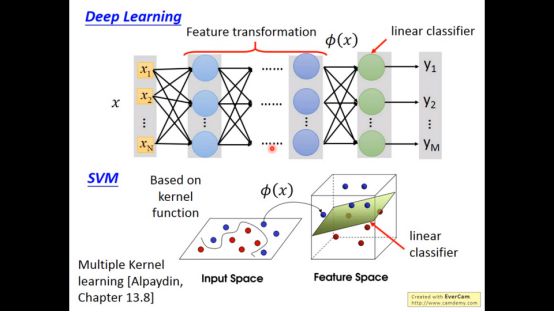
下图为SVM和deep learning的区别
请关注专知公众号(扫一扫最下面专知二维码,或者点击上方蓝色专知),
后台回复“LHY2017” 就可以获取 2017年李宏毅中文机器学习课程下载链接~
-END-
专 · 知
人工智能领域主题知识资料查看获取:【专知荟萃】人工智能领域26个主题知识资料全集(入门/进阶/论文/综述/视频/专家等)
同时欢迎各位用户进行专知投稿,详情请点击:
【诚邀】专知诚挚邀请各位专业者加入AI创作者计划!了解使用专知!
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

请加专知小助手微信(Rancho_Fang),加入专知主题人工智能群交流!
点击“阅读原文”,使用专知!
展开全文



