DeepMind最新深度学习研究:超参选择利器-引入基于群体的训练
【导读】机器学习的训练和优化是现代深度学习模型中最具有挑战性的方面,本文首先介绍了常用的深度学习超参数优化方法:随机搜索和手动优化,然后引入DeepMind关于深度学习模型超参数优化的最新研究进展:基于群体的训练(population based training), 它能够在更短的时间和更低的计算资源占用的情况下找到好的超参. 相信会被引入到更多的深度学习框架中,文末附有paper地址和GitHub地址,感兴趣的朋友可以详细了解一下。

What’s New in Deep Learning Research: Introducing Population Based Training
深度学习研究的新进展:基于群体的训练
深度学习模型的训练和优化是任何现代机器智能(MI)解决方案中最具挑战性的方面。在许多情况下,数据科学家能够迅速为特定问题找到正确的算法集,然后要花费若干月找到模型的最优解。最近,DeepMind发表了一篇新的研究论文,其中提出了一种新的方法,用于训练和优化深度学习模型——称为基于群体的训练(population based training)。
传统深度学习模型的优化致力于:在避免急剧改变模型的核心组件的前提下最大限度地减少测试误差。深度学习优化中最重要的方法之一是调整与模型本身正交的元素。深度学习理论通常将这些元素称为超参数。通常,深度学习程序中的超参数包括诸如隐藏单元的数量、可以调整学习速率等要素以提高特定模型的性能等。
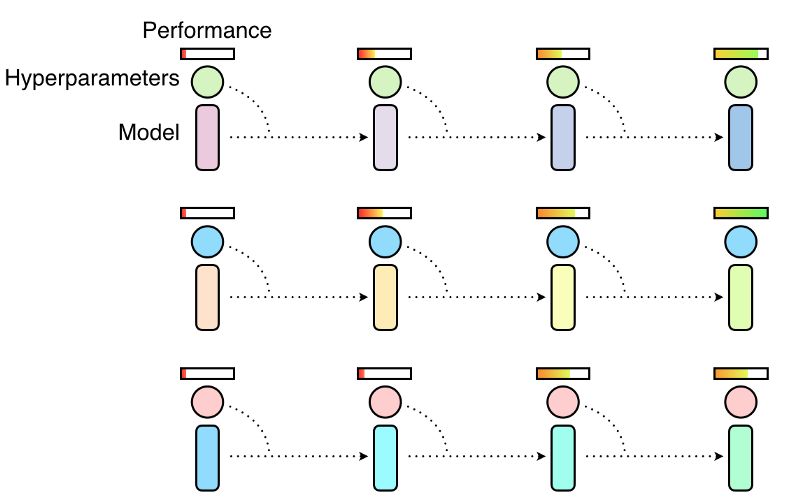
优化超参数是在深度学习功能的性能与其成本之间找到平衡的博弈。诸如随机梯度下降及其变种算法已成为深度学习优化的核心,但在大规模场景中应用时仍面临重大挑战。通常,深度学习超参数优化有两种主要方法:随机搜索和手动优化。在随机搜索场景中,采用不同超参数的模型将各自独立并行训练,训练结束时选择性能最高的那个模型。通常情况下,这意味着只有小部分模型是拿着较好的超参数去训练的,而其余模型的超参数是有问题的结果而然不好,甚至可以说是在浪费计算资源, 如下图所示。
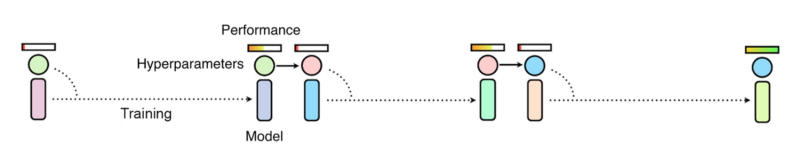
手动寻找方法本质上是基于顺序优化过程(sequential optimization)。顺序优化需要完成多次训练, 也就是一个接一个的试, 根据实验结果认为调整新的超参数,再重新训练模型。这是一个顺序过程,使用最少的计算资源,然而导致参数优化时间变长。
正如你所看到的,随机搜索和手动搜索技术都有其优点和局限性。最近,DeepMind团队发表了一篇研究论文,主张采用新的优化技术,试图结合两种方法得到最佳的方法。
引入基于群体的训练
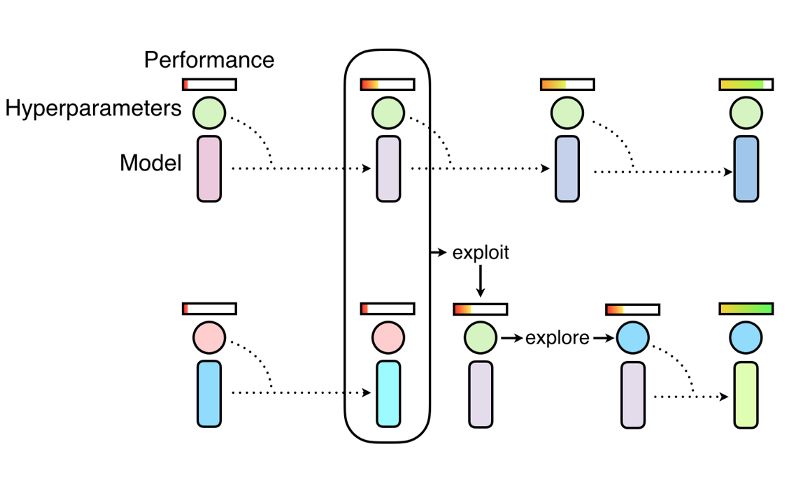
基于群体的训练(PBT)使用类似随机搜索那样的方法来对超参数和权重初始化进行随机采样。与传统方法不同,PBT会异步训练然后定期评估模型性能。如果群体中的一个模型表现不佳,它将评估其余的模型,并用更优化的模型取而代之。同时,在继续训练之前,PBT将在群体中表现的更好的模型的超参的基础上再做修改.
PBT过程允许超参数在线优化,计算资源集中在超参数和权重空间上,这些空间有很大的机会产生好的结果。这将生成一个更快的学习速度,更低的计算资源以及更好的超参调整方案。
在研究论文中,DeepMind团队将PBT应用于不同场景,如深度强化学习或机器翻译。最初的结果非常令人鼓舞,PBT显示出对传统技术的巨大改进。
我们期待可以很快将PBT纳入流行的深度学习框架。Github中有一个初始实现,我们很快会看到其他框架采用这个工作。
相关材料:
DeepMind论文:https://arxiv.org/abs/1711.09846

PBT GitHub实现:https://github.com/MattKleinsmith/pbt
原文链接:
https://towardsdatascience.com/whats-new-in-deep-learning-research-introducing-population-based-training-35c3e5526a90
-END-
专 · 知
人工智能领域主题知识资料查看获取:【专知荟萃】人工智能领域26个主题知识资料全集(入门/进阶/论文/综述/视频/专家等)
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

请加专知小助手微信(Rancho_Fang),加入专知主题人工智能群交流!
点击“阅读原文”,使用专知
展开全文



