【论文读书笔记】自动驾驶新思路:现实域到虚拟域统一的无监督方法
【导读】近日,针对无人驾驶中端到端模型缺乏训练数据以及训练数据噪声大、模型难解释等问题,来自卡内基梅隆大学、Petuum公司的Eric P. Xing等学者发表论文提出基于无监督现实到虚拟域统一的端到端自动驾驶方法。该方法具有如下优势:1)将从不同源分布中收集的驾驶数据映射到一个统一的域; 2)充分利用标注的虚拟数据,这些数据是可以自由获取的; 3)学习除了一个可解释的、标注的驾驶图像表示方法,其可以专门用于车辆指挥预测。所提出的方法在两个公路行驶数据集的大量实验表明了方法的性能优势和可解释能力。
论文:Unsupervised Real-to-Virtual Domain Unification for End-to-End Highway Driving

▌摘要
在基于视觉的自动驾驶领域中,端到端模型在性能上表现不佳并且是不可解释的,而中介感知模型(mediated perception models)需要额外的中间表示,例如分割的masks或检测边界框(bounding boxes),在进行大规模数据训练时,这些大量的标签信息的获取可能是非常昂贵的。 原始图像和现有的中间表示中可能夹杂着与车辆命令预测无关的琐碎的细节,例如,前方车辆的风格或超过了道路边界的视野。 更重要的是,如果合并从不同来源收集的数据,所有以前的工作都不能有效应对这种域转移问题,这极大地阻碍了模型的泛化能力。
在这项工作中,本文利用从驾驶模拟器收集的虚拟数据来解决上述问题,并且提出了DU-驱动,一种无监督的真实到虚拟域的统一框架,用于端到端驾驶。 它将实际驾驶数据转换为虚拟域中的规范表示,从中预测车辆控制命令。 提出的框架有几个优点:1)将从不同源分布中收集的驾驶数据映射到一个统一的域; 2)利用标注的虚拟数据,这些数据是可以自由获取的; 3)它学习除了一个可解释的、标注的驾驶图像表示方法,其可以专门用于车辆指挥预测。 两个公路行驶数据集的大量实验表明了DU驱动的性能优势和可解释能力。
▌介绍
基于视觉的自动驾驶系统是一个长期的研究问题。在已有的各种解决方案中,将单个正面摄像机图像映射到车辆控制命令的端到端驾驶模型吸引了许多研究兴趣,因为它消除了特征工程的繁琐过程。 也有许多方法尝试了利用中间表示来提高端到端模型的性能(图1)。 例如,[33]使用语义分割作为一个辅助任务来提高模型的性能,而[8]在进行驾驶决策之前,首先训练一个检测器来检测附近的车辆。 然而,随着我们向更大的规模迈进,驾驶数据的收集和中间表示的标注可能会非常昂贵。
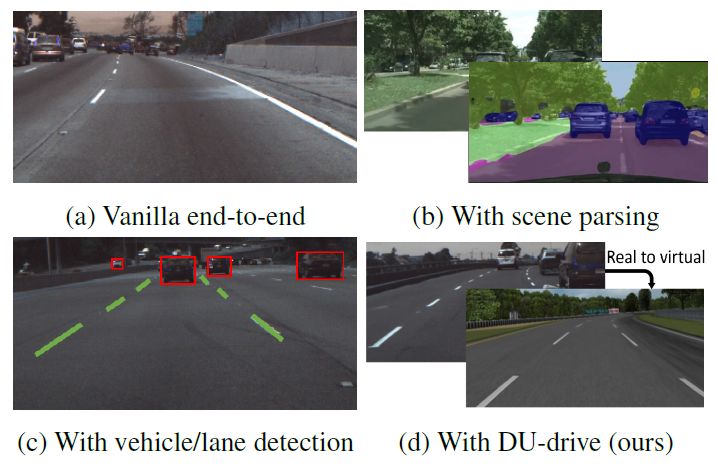
图1:各种已经提出的基于视觉的驾驶模型的方法。 标准的端到端模型(a)在性能上不可解释且不是最理想的,场景解析(b)或对象检测(c)需要昂贵的注释数据。 提出的方法(d)将不同数据集的真实图像统一到虚拟领域的规范化表示中,避免了多余的细节,提高了车辆指令预测任务的性能。
此外,由于现实场景的复杂性,驾驶场景的一般图像和中间表示中含有多余的细节。这些细节中的许多信息既不相关,也对预测任务没有帮助。例如,高速驾驶的人类驾驶者不会根据前面的汽车品牌或道路边界外的视野来改变自己的行为。理想情况下,模型应该能够通过观察人类驾驶数据来学习关键信息,但是由于深度神经网络的黑盒性质,我们难以分析模型是否学会了基于正确的信号进行预测。
文献 [6]可视化了神经网络的激活,并表明,模型不仅学习驾驶关键信息,如车道标记,同时也学到了不需要的特征,如不规则类型的车辆类别。文献 [18]提出了由因果滤波器改进的注意力map的结果,它包括相当随机的注意力blob。很难证明学习这些信息是否有助于驾驶,而且本文认为从驾驶图像中有效地提取最少的且足够的信息的能力对于提高预测任务的性能是至关重要的。
相比之下,来自于驾驶模拟器的数据自然地避免了这两个问题。 一方面,通过设置一个机器人汽车,我们可以很容易地获得用于控制信号标注的、源源不断的驾驶数据。 另一方面,我们可以控制虚拟世界的视觉外观,并通过将多余的细节保持在最低限度,来构建规范的驾驶环境。
这促使作者开发一个能够在虚拟领域有效地将真实的驾驶图像转化为规范表示的系统,从而促进车辆指挥预测任务。许多现有的工作利用了虚拟数据,通过生成对抗网络将虚拟图像转化为类似于真实的图像,同时在辅助目标的辅助下保持标注的完整。
本文的方法虽然也基于GAN,但在几个方面有所不同:首先,有别于其他方法,作者尝试将真实图像转换为虚拟域中的规范表示。通过规范表示,作者参考了像素级表示,其从背景中分离出预测任务所需的最小的足量信息。由于任何图像只能有一个规范表示,因此在生成过程中不会引入任何噪声变量。其次,本文并不直接保留标注,因为图像中确定车辆命令的确切信号是不清楚的。相反,本文提出了一种新的联合训练方案,将预测关键信息逐渐提取到生成器中,同时提高模型训练的稳定性,防止驾驶关键信息的模型崩溃。
这次工作有三个贡献:
首先,作者引入一个无监督的真实到虚拟域的统一框架,将真实的驾驶图像转换成虚拟域的规范表示,并从中预测车辆命令。
其次,作者开发了一种新的训练方案,不仅逐步将预测关键信息提取到生成器中,而且有选择地防止生成对抗网路的模型崩溃。
第三,作者给出了实验结果,证明了在虚拟域中使用统一的、规范的表示来进行端到端自动驾驶是具备优越性的。
▌模型简介:
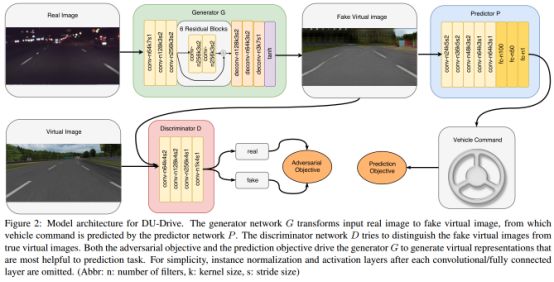
图2:DU-Drive的模型架构。 生成器网络G将输入的真实图像转换成虚拟图像,由预测器网络P预测车辆指令。 判别器网络D试图将假虚像与真虚像区分开来。 对抗目标和预测目标都驱使生成者G生成最有助于预测任务的虚拟表示。 为了简单起见,省略了每个卷积/全连接层之后的实例标准化和激活层。 (缩写:n:filters数量,k:kernel大小,s:stride大小)
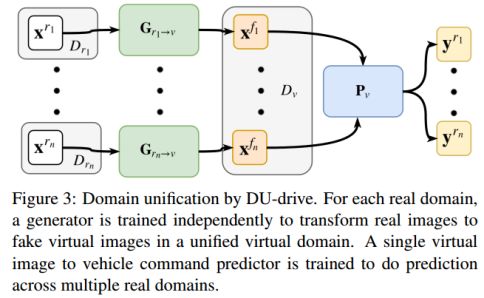
图3:DU-Drive的域统一框架。 对于每一个真实域,训练一个独立的生成器,以将真实图像转换成虚拟域中的虚拟图像。 训练单个虚拟图像进行车辆指令预测,并在多个真实域上进行预测。
▌实验结果
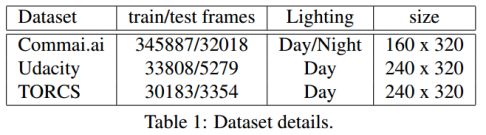
表1:数据集的细节

图4:我们的工作使用的样本数据。从上到下依次为:从TORCS模拟器捕获的虚拟数据,来自于comma.ai的真实驾驶数据,来自Udacity挑战的真实驾驶数据。

图5:DU-Drive的图像生成结果,考虑了那些对驾驶行为不重要的信息,例如昼/夜照明情况。而视野超出道路边界。有趣的是,车辆也从场景中移除,但是考虑到我们在实验中只预测转向角度,所以这实际上是合理的。另一方面,驾驶车道这样的关键信息得到很好地保存。

图6:在TORCS模拟器中的6个轨道的形状,并从中收集虚拟数据。

图7:条件GAN的图像生成结果。在背景和前景、车道标记发生的模型崩溃不予保存。

图8:CycleGAN的图像生成结果。第一行:真实的源图像和生成的虚拟图像。下一行:虚拟源图像和生成的假的真实图像。
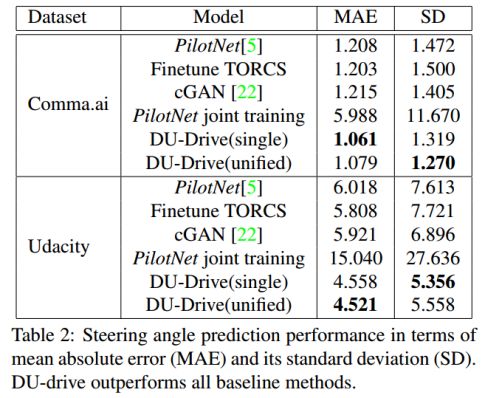
表2:转向角度预测性能。平均绝对误差(MAE)及其标准差(SD)。其中,DU-drive优于所有baseline方法。
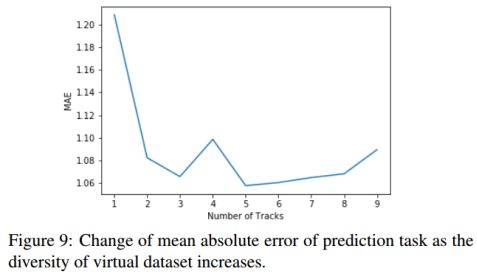
图9:随着虚拟数据集的多样性增加,预测任务的绝对误差平均值的变化。
▌结论
我们针对公路驾驶提出了一种无监督的真实到虚拟域的统一模型,或称为DU-drive,它使用条件生成对抗网络来将真实域中的驾驶图像变换到虚拟领域中的规范表示,并从中预测车辆控制命令。 在存在多个真实数据集的情况下,可以为每个真实域独立地训练生成器(从真实到虚拟域的生成器),并且可以用来自多个真实域的数据来训练全局预测器。 定性实验结果表明,该模型能够将实际图像有效地转换到虚拟域,并且只保留足够的最小信息量,结果证明了这种规范表示能消除域偏移,提高控制指令预测任务的性能。
参考链接:
https://arxiv.org/abs/1801.03458
-END-
专 · 知
人工智能领域主题知识资料查看获取:【专知荟萃】人工智能领域26个主题知识资料全集(入门/进阶/论文/综述/视频/专家等)
同时欢迎各位用户进行专知投稿,详情请点击:
【诚邀】专知诚挚邀请各位专业者加入AI创作者计划!了解使用专知!
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

请加专知小助手微信(Rancho_Fang),加入专知主题人工智能群交流!
点击“阅读原文”,使用专知!
展开全文



