【论文推荐】最新7篇视觉问答(VQA)相关论文—解释、读写记忆网络、逆视觉问答、视觉推理、可解释性、注意力机制、计数
【导读】专知内容组整理了最近七篇视觉问答(Visual Question Answering)相关文章,为大家进行介绍,欢迎查看!
1.VQA-E: Explaining, Elaborating, and Enhancing Your Answers for Visual Questions(VQA-E:解释、阐述并增强你对视觉问题的回答)
作者:Qing Li,Qingyi Tao,Shafiq Joty,Jianfei Cai,Jiebo Luo
机构:University of Science and Technology of China,Nanyang Technological University,University of Rochester
摘要:Most existing works in visual question answering (VQA) are dedicated to improving the accuracy of predicted answers, while disregarding the explanations. We argue that the explanation for an answer is of the same or even more importance compared with the answer itself, since it makes the question and answering process more understandable and traceable. To this end, we propose a new task of VQA-E (VQA with Explanation), where the computational models are required to generate an explanation with the predicted answer. We first construct a new dataset, and then frame the VQA-E problem in a multi-task learning architecture. Our VQA-E dataset is automatically derived from the VQA v2 dataset by intelligently exploiting the available captions. We have conducted a user study to validate the quality of explanations synthesized by our method. We quantitatively show that the additional supervision from explanations can not only produce insightful textual sentences to justify the answers, but also improve the performance of answer prediction. Our model outperforms the state-of-the-art methods by a clear margin on the VQA v2 dataset.

期刊:arXiv, 2018年3月20日
网址:
http://www.zhuanzhi.ai/document/f39b8adecd703b04ad2dd62e94427325
2.A Read-Write Memory Network for Movie Story Understanding(一个为电影故事理解的读写记忆网络)
作者:Seil Na,Sangho Lee,Jisung Kim,Gunhee Kim
机构:Seoul National University
摘要:We propose a novel memory network model named Read-Write Memory Network (RWMN) to perform question and answering tasks for large-scale, multimodal movie story understanding. The key focus of our RWMN model is to design the read network and the write network that consist of multiple convolutional layers, which enable memory read and write operations to have high capacity and flexibility. While existing memory-augmented network models treat each memory slot as an independent block, our use of multi-layered CNNs allows the model to read and write sequential memory cells as chunks, which is more reasonable to represent a sequential story because adjacent memory blocks often have strong correlations. For evaluation, we apply our model to all the six tasks of the MovieQA benchmark, and achieve the best accuracies on several tasks, especially on the visual QA task. Our model shows a potential to better understand not only the content in the story, but also more abstract information, such as relationships between characters and the reasons for their actions.
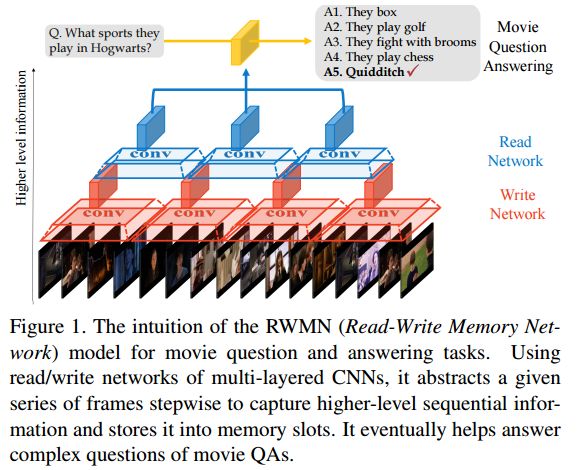
期刊:arXiv, 2018年3月16日
网址:
http://www.zhuanzhi.ai/document/bce2b92d8c8684b5308fbf6b7b39f25f
3.iVQA: Inverse Visual Question Answering(iVQA:逆视觉问题回答)
作者:Feng Liu,Tao Xiang,Timothy M. Hospedales,Wankou Yang,Changyin Sun
机构:Southeast University,Queen Mary University of London,University of Edinburgh,
摘要:We propose the inverse problem of Visual question answering (iVQA), and explore its suitability as a benchmark for visuo-linguistic understanding. The iVQA task is to generate a question that corresponds to a given image and answer pair. Since the answers are less informative than the questions, and the questions have less learnable bias, an iVQA model needs to better understand the image to be successful than a VQA model. We pose question generation as a multi-modal dynamic inference process and propose an iVQA model that can gradually adjust its focus of attention guided by both a partially generated question and the answer. For evaluation, apart from existing linguistic metrics, we propose a new ranking metric. This metric compares the ground truth question's rank among a list of distractors, which allows the drawbacks of different algorithms and sources of error to be studied. Experimental results show that our model can generate diverse, grammatically correct and content correlated questions that match the given answer.
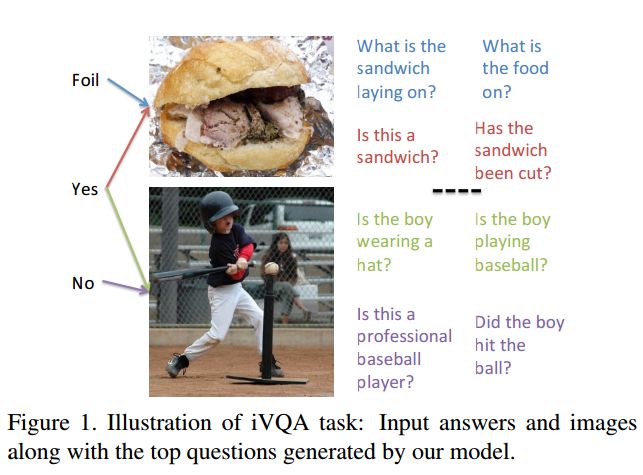
期刊:arXiv, 2018年3月16日
网址:
http://www.zhuanzhi.ai/document/92ea4a9253cf26e085bbee1374040be6
4.A dataset and architecture for visual reasoning with a working memory(具有工作记忆的视觉推理的数据集和架构)
作者:Guangyu Robert Yang,Igor Ganichev,Xiao-Jing Wang,Jonathon Shlens,David Sussillo
机构:Google Brain,New York University,Columbia University
摘要:A vexing problem in artificial intelligence is reasoning about events that occur in complex, changing visual stimuli such as in video analysis or game play. Inspired by a rich tradition of visual reasoning and memory in cognitive psychology and neuroscience, we developed an artificial, configurable visual question and answer dataset (COG) to parallel experiments in humans and animals. COG is much simpler than the general problem of video analysis, yet it addresses many of the problems relating to visual and logical reasoning and memory -- problems that remain challenging for modern deep learning architectures. We additionally propose a deep learning architecture that performs competitively on other diagnostic VQA datasets (i.e. CLEVR) as well as easy settings of the COG dataset. However, several settings of COG result in datasets that are progressively more challenging to learn. After training, the network can zero-shot generalize to many new tasks. Preliminary analyses of the network architectures trained on COG demonstrate that the network accomplishes the task in a manner interpretable to humans.
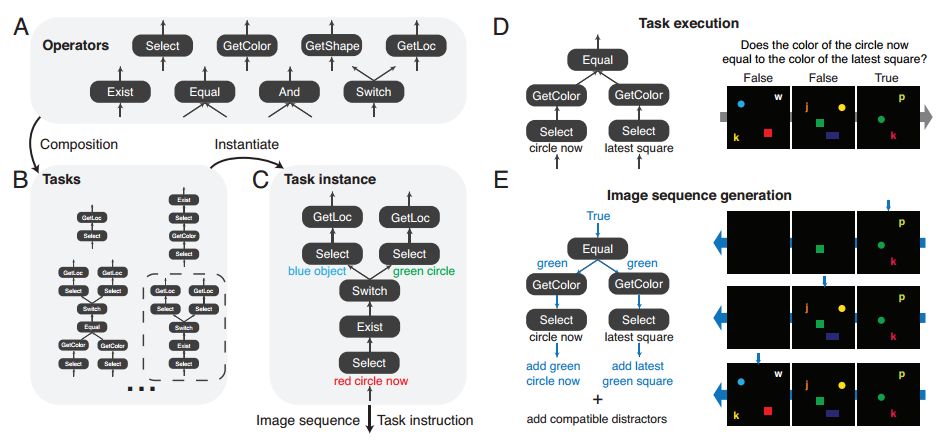
期刊:arXiv, 2018年3月16日
网址:
http://www.zhuanzhi.ai/document/581fcd7b86474896a801300e4f46ef78
5.Transparency by Design: Closing the Gap Between Performance and Interpretability in Visual Reasoning(透明性设计:在视觉推理中缩小性能和可解释性之间的差距)
作者:David Mascharka,Philip Tran,Ryan Soklaski,Arjun Majumdar
机构:MIT Lincoln Laboratory,Planck Aerosystems
摘要:Visual question answering requires high-order reasoning about an image, which is a fundamental capability needed by machine systems to follow complex directives. Recently, modular networks have been shown to be an effective framework for performing visual reasoning tasks. While modular networks were initially designed with a degree of model transparency, their performance on complex visual reasoning benchmarks was lacking. Current state-of-the-art approaches do not provide an effective mechanism for understanding the reasoning process. In this paper, we close the performance gap between interpretable models and state-of-the-art visual reasoning methods. We propose a set of visual-reasoning primitives which, when composed, manifest as a model capable of performing complex reasoning tasks in an explicitly-interpretable manner. The fidelity and interpretability of the primitives' outputs enable an unparalleled ability to diagnose the strengths and weaknesses of the resulting model. Critically, we show that these primitives are highly performant, achieving state-of-the-art accuracy of 99.1% on the CLEVR dataset. We also show that our model is able to effectively learn generalized representations when provided a small amount of data containing novel object attributes. Using the CoGenT generalization task, we show more than a 20 percentage point improvement over the current state of the art.
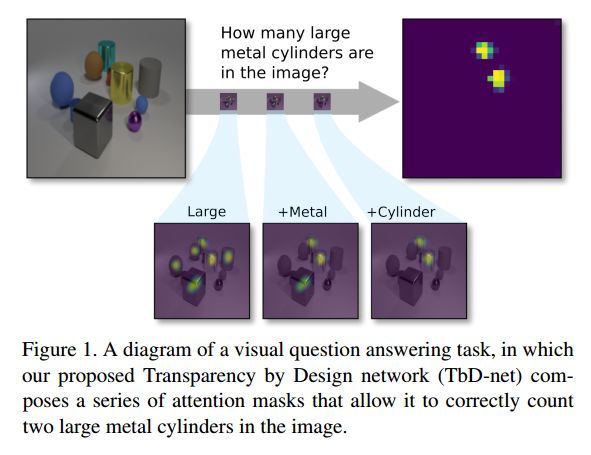
期刊:arXiv, 2018年3月14日
网址:
http://www.zhuanzhi.ai/document/687e4e6f8dff600d060ff4c188eb566e
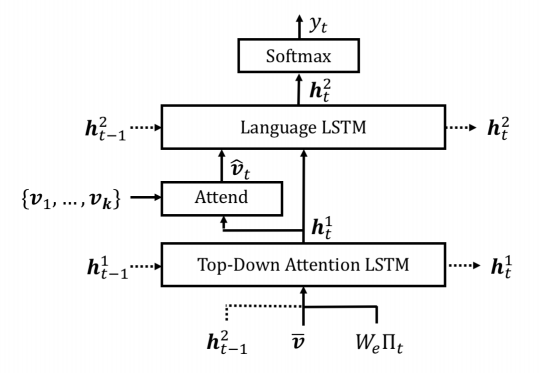
6.Bottom-Up and Top-Down Attention for Image Captioning and Visual Question Answering(用于图像描述和视觉问题的回答的自底向上和自顶向下的注意力)
作者:Peter Anderson,Xiaodong He,Chris Buehler,Damien Teney,Mark Johnson,Stephen Gould,Lei Zhang
机构:Australian National University,Microsoft Research,University of Adelaide,Macquarie University
摘要:Top-down visual attention mechanisms have been used extensively in image captioning and visual question answering (VQA) to enable deeper image understanding through fine-grained analysis and even multiple steps of reasoning. In this work, we propose a combined bottom-up and top-down attention mechanism that enables attention to be calculated at the level of objects and other salient image regions. This is the natural basis for attention to be considered. Within our approach, the bottom-up mechanism (based on Faster R-CNN) proposes image regions, each with an associated feature vector, while the top-down mechanism determines feature weightings. Applying this approach to image captioning, our results on the MSCOCO test server establish a new state-of-the-art for the task, achieving CIDEr / SPICE / BLEU-4 scores of 117.9, 21.5 and 36.9, respectively. Demonstrating the broad applicability of the method, applying the same approach to VQA we obtain first place in the 2017 VQA Challenge.
期刊:arXiv, 2018年3月14日
网址:
http://www.zhuanzhi.ai/document/ccf862349b06541be2dc5312a84fc2db
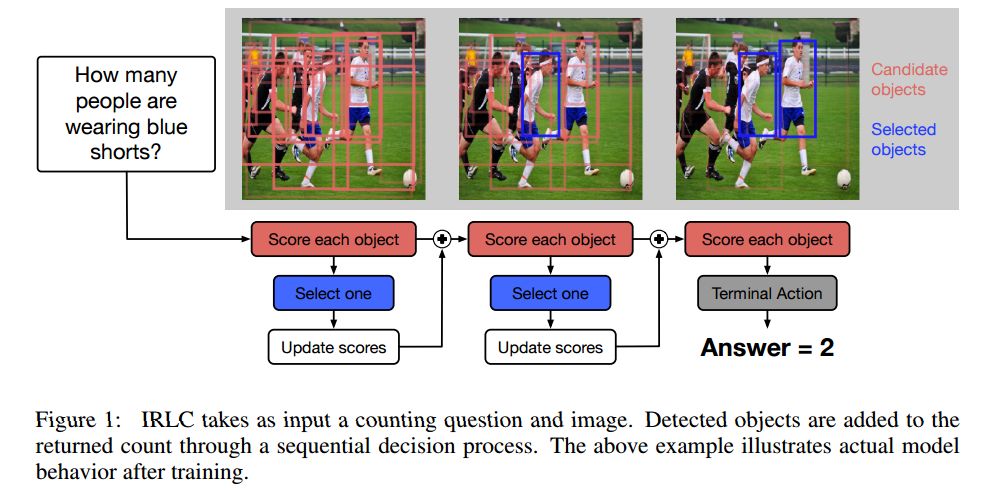
7.Interpretable Counting for Visual Question Answering(可解释计数的视觉问题回答)
作者:Alexander Trott,Caiming Xiong,Richard Socher
机构:Salesforce Research
摘要:Questions that require counting a variety of objects in images remain a major challenge in visual question answering (VQA). The most common approaches to VQA involve either classifying answers based on fixed length representations of both the image and question or summing fractional counts estimated from each section of the image. In contrast, we treat counting as a sequential decision process and force our model to make discrete choices of what to count. Specifically, the model sequentially selects from detected objects and learns interactions between objects that influence subsequent selections. A distinction of our approach is its intuitive and interpretable output, as discrete counts are automatically grounded in the image. Furthermore, our method outperforms the state of the art architecture for VQA on multiple metrics that evaluate counting.
期刊:arXiv, 2018年3月2日
网址:
http://www.zhuanzhi.ai/document/2efb2987a89a520de3af9a7ae2c01aea
-END-
专 · 知
人工智能领域主题知识资料查看获取:【专知荟萃】人工智能领域26个主题知识资料全集(入门/进阶/论文/综述/视频/专家等)
同时欢迎各位用户进行专知投稿,详情请点击:
【诚邀】专知诚挚邀请各位专业者加入AI创作者计划!了解使用专知!
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

请加专知小助手微信(Rancho_Fang),加入专知主题人工智能群交流!加入专知主题群(请备注主题类型:AI、NLP、CV、 KG等)交流~

点击“阅读原文”,使用专知!
展开全文



