Richard S. Sutton经典图书:《强化学习导论》第二版(附PDF下载)
【导读】Richard S. Sutton就职于iCORE大学计算机科学系,是强化学习领域的专家,其在强化学习领域的著作“Reinforcement Learning”一直是认为是强化学习方面的圣经,近期Sutton分享了该书的第二版“Reinforcement Learning: An Introduction”的最新版,经过了三年多的撰写和完善,相信这个版本也一定不负众望。
作者介绍

Richard S. Sutton是加拿大的一个计算机科学家,当前任职于iCORE大学计算机科学系。Sutton是强化学习领域巨擘,在temporal difference learning, policy gradient methods, the Dyna architecture等方面都有重大贡献。自2003年起,Sutton就出任iCORE大学计算机科学系的教授,在这里他领导了强化学习和人工智能实验室(RLAI)。
https://www.ualberta.ca/science/about-us/contact-us/faculty-directory/rich-sutton

Andrew Barto 是Massachusetts大学Amherst分校的教授, 已于2012年退休.
退休前, 他是Massachusetts大学Amherst分校自治学习实验室主任.
目前, 他是Massachusetts大学神经科学和行为项目的准会员, Neural Computation 副主编, Machine Learning Research杂志顾问, Adaptive Behavior的编辑.
Barto教授是美国科学促进会会员,IEEE Fellow, 以及神经科学学会会员.
他因强化学习领域的贡献而获得2004年IEEE神经网络协会先锋奖, IJCAI-17杰出研究奖.
他在期刊,书籍,会议和研讨会中发表论文一百多篇。 他与Richard Sutton共同编写了 "Reinforcement Learning: An Introduction," MIT Press 1998,迄今已收到超过25,000次引用。 本书的第二版即将发布。
履历:
Massachusetts大学的计算机科学系主任----- 2007-2011年
Massachusetts大学的计算机科学系教授----- 1991年
Massachusetts大学的计算机科学系副教授----- 1982年
Massachusetts大学的计算机科学系博士后----- 1977年
获Michigan大学数学专业学士学位----- 1970年
获Michigan大学计算机科学专业博士学位----- 1975年
http://www-all.cs.umass.edu/~barto/

书籍目录
第一章:简介
1.1 增强学习
1.2 实例
1.3 增强学习要素
1.4 限制和范围
1.5 一个扩展案例:Tic-Tac-Toe
1.6 摘要
1.7 增强学习发展历史
第二章: Muti-armed Bandits问题
2.1 K-armed Bandits问题
2.2 行动值方法
2.3 10-armed Testbed
2.4 增量实现
2.5 追踪一个非稳态解
2.6 优化初始值
2.7 置信上界行为选择
2.8 梯度Bandit算法
2.9 关联检索
2.10 小结
第三章:有限马尔可夫决策过程
3.1代理-环境接口
3.2目标和奖励
3.3返回和插值
3.4情节和连续任务的统一符号
3.5策略和价值函数
3.6最优策略与价值函数
3.7最优化与近似
3.8总结
第四章:动态编程
4.1 策略估计(预测)
4.2 策略提升
4.3 策略迭代
4.4 迭代值
4.5 异步动态编程
4.6 泛化的策略迭代
4.7 动态编程的效率
4.8 总结
第五章:蒙特卡洛方法
5.1 蒙特卡洛预测
5.2 蒙特卡洛对行为值的评估
5.3 蒙特卡洛控制
5.4 无开始探索的蒙特卡洛控制
5.5 通过重要抽样进行无策略(off-Policy)预测
5.6 增量编程
5.7 Off-Policy 蒙特卡洛控制
5.8 Discounting-aware 重要性采样
5.9 Per-decision 重要性采样
5.10 总结
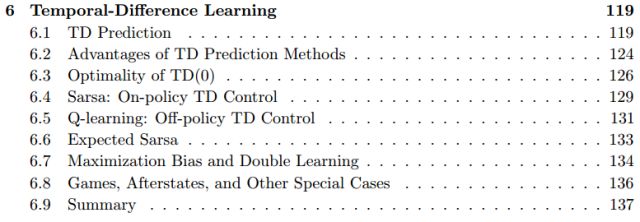
第六章:时序差分学习(Temporal-Difference Learning)
6.1 时序差分预测
6.2 时序差分预测方法的优势
6.3 TD(o)的最佳性
6.4 Sarsa:在策略(On-Policy) TD 控制
6.5 Q-Learning:连策略TD 控制
6.6 期待的Sarsa
6.7 偏差最大化和双学习
6.8 游戏、afterstates 和其他具体案例
6.9 总结
第七章:n-step Bootstrapping
7.1 n-step TD 预测
7.2 n-step Sarsa
7.3 通过重要性抽样进行 n-step 离策略学习
7.4 Per-decision Off-policy Methods with Control Variates
7.5无重要性抽样下的离策略学习:n-step 树反向算法
7.6 一个统一的算法:n-step Q( σ)
7.7 总结
第八章:用表格方法进行计划和学习
8.1 模型和计划
8.2 Dyna:融合计划、行动和学习
8.3 模型错了会发生什么
8.4 优先扫除 (prioritized sweeping)
8.5 Expected vs. Sample Updates
8.6 Trajectory Sampling
8.7 Real-time Dynamic Programming
8.8 计划作为行动选择的一部分
8.9 启发式搜索
8.10 Rollout Algorithms
8.11 蒙特卡洛树搜索
8.12 本章总结
8.13 Summary of Part I: Dimensions
近似法解决方案
第九章:使用近似法的在政策预测
9.1 价值函数的近似
9.2 预测目标(MSVE)
9.3 随机梯度和半梯度的方法
9.4 线性方法
9.5 线性方法中的特征构建
9.5.1 多项式
9.5.2 傅里叶基础
9.5.3 课程代码
9.5.4 Tile Coding
9.5.5 径向基函数
9.6 手动选择步长参数
9.7 非线性函数近似:人工神经元网络
9.8 最小平方TD
9.9 基于内存的函数近似
9.10 Kernel-based函数近似
9.11 更深入地研究策略学习:兴趣和重点。
9.12 总结
第十章:用近似法控制on-policy 在策略
10.1 插入式的半梯度控制
10.2 n-step 半梯度Sarsa
10.3 平均回馈:连续任务中的新问题设定
10.4 “打折”的设置要考虑可用性
10.5 n-step 差分半梯度Sarsa
10.6 总结
第十一章:使用近似法的离策略方法
11.1 半梯度的方法
11.2 Barid 的反例
11.3 The deadly triad
11.4 线性几何值函数
11.5 在Bellman错误中梯度下降
11.6 The Bellman Error is Not Learnable
11.7 Gradient-TD Methods
11.8 Emphatic-TD Methods
11.9 减少方差
11.10 总结
第十二章:合格性追踪
12.1 λ-返回
12.2 TD(λ)
12.3 n-step Truncated λ-return Methods
12.4 Redoing Updates: The Online λ-return Algorithm
12.5 真实的在线TD(λ)
12.6 蒙特卡洛学习中的Dutch Traces
12.7 Sarsa(λ)
12.8 λ 和γ变量
12.9 带有控制变量的偏离策略的资格
12.10 Watkins’s Q(λ) to Tree-Backup(λ)
12.11 带有跟踪的稳定的非策略方法
12.12 实现中的若干问题
12.13 结论
第十三章:策略梯度方法
13.1 策略近似及其优势
13.2 策略梯度的原理
13.3 增强:蒙特卡洛策略梯度
13.4 使用基准增强
13.5 评估-决策方法(Actor-Critic)
13.6 连续问题中的策略梯度(平均回馈率)
13.7 连续行动中的策略参数化
13.8 总结
长远展望
第十四章:心理学
14.1 预测和控制
14.2 经典的调节
14.2.1 Blocking and Higher-order Conditioning
14.2.2 rescorla wagner 方法
14.2.3 TD模型
14.2.4 TD 模型模拟
14.3 有用条件
14.4 延迟的增强
14.5 认知图
14.6 习惯和目标导向的行为
14.7 总结
第十五章:神经科学
15.1 神经科学基础
15.2 回馈信号、价值、预测误差和增强信号
15.3 回馈预测误差假设
15.4 回馈预测误差假设的实验支持
15.6 TD 误差/ 多巴胺对应
15.7 神经评估-决策
15.8 评估-决策的学习规则
15.9 快乐主义的神经元
15.10 集体增强学习
15.11 大脑中基于模型的方法
15.12 上瘾
15.13 总结
第十六章:应用和案例分析
16.1 TD-Gammon
16.2 Samuel 的西洋棋玩家
16.3 Watson的 Daily-Double
16.4 优化记忆控制
16.5 人类水平的电子游戏
16.6 下围棋
16.6.1 AlphaGo
16.6.2 AlphaGo Zero
16.7 个性化网页服务
16.8 热气流滑翔
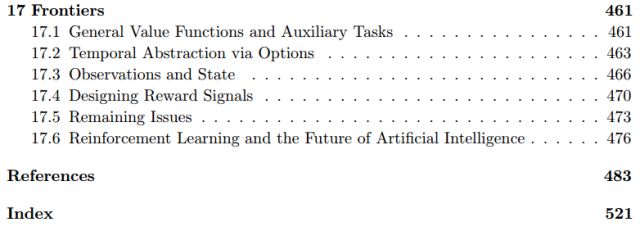
第十七章:前沿
17.1一般值函数和辅助任务
17.2通过选项进行时态抽象
17.3观察和状态
17.4设计奖励信号
17.5遗留问题
17.6强化学习与人工智能的未来
英文目录















书中对应的Python 代码(GitHub链接):
https://github.com/ShangtongZhang/reinforcement-learning-an-introduction
请关注专知公众号(扫一扫最下面专知二维码,或者点击上方蓝色专知),
后台回复“RLD” 就可以获取 书籍《Reinforcement Learning: An Introduction》最新版本下载链接~
-END-
专 · 知
人工智能领域主题知识资料查看获取:【专知荟萃】人工智能领域26个主题知识资料全集(入门/进阶/论文/综述/视频/专家等)
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

请加专知小助手微信(Rancho_Fang),加入专知主题人工智能群交流!加入专知主题群(请备注主题类型:AI、NLP、CV、 KG等)交流~
点击“阅读原文”,使用专知
展开全文



