【最新综述】模型压缩与加速(附论文全文下载)
【导读】深度卷积神经网络(CNN)在最近的很多任务中取得了巨大的成功。然而现有深度模型计算成本过高、内存密集,阻碍了它们的部署过程,在内存资源较低的设备中存在着明显的延迟问题。因此,模型压缩成为了一个不可忽视的研究方向。
介绍:
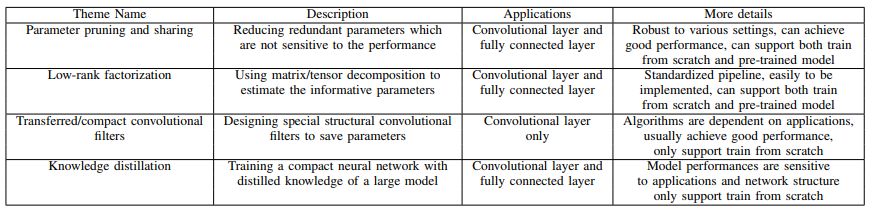
近几年,随着深度学习的深入发展,在多个任务中达到了工业级的标准,但因为模型的复杂性等原因,难以大规模应用至生产环境,特别是那些资源受限的应用程序中。这主要是由于许多工作都依赖于具有数百万甚至数十亿的深层网络,在计算过程中,需要大量的计算资源参与。例如krizhevsky等人2012年ImageNet挑战赛中使用了6000万个参数的网络,其中包括5个卷积层和3个全连接层,从而取得了突破性的成果,但如此大的模型,在实际部署中,很难满足实时性、高效性等需求。因此,一个很自然的想法是,如何在不显著降低模型性能的情况下,来实现模型的加速与压缩。本文主要聚焦于针对CNN的模型压缩加速技术,并将这些技术大致分为4类:参数修剪与共享、低阶分解、transferred/compact卷积滤波器、知识精化。
对于每个方案,我们都提供了关于性能、相应应用程序、优点和缺点等的深入分析。最后,将对本文进行总结,讨论本课题尚存在的挑战与可能的发展方向。
【论文便捷下载】
请关注专知公众号(点击上方蓝色专知关注)
后台回复“SMCAD” 就可以获取《模型压缩综述》的下载链接~
附论文全文:










-END-
专 · 知
专知《深度学习:算法到实战》课程全部完成!480+位同学在学习,现在报名,限时优惠!网易云课堂人工智能畅销榜首位!

请加专知小助手微信(扫一扫如下二维码添加),咨询《深度学习:算法到实战》参团限时优惠报名~

欢迎微信扫一扫加入专知人工智能知识星球群,获取专业知识教程视频资料和与专家交流咨询!

请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

点击“阅读原文”,了解报名专知《深度学习:算法到实战》课程
展开全文



