【深度】浅述:从 Minimax 到 AlphaZero,完全信息博弈之路(1)
【导读】本文从Minimax算法开始,一直到最新的 AlphaGo Zero 和 AlphaZero,旨在介绍完全信息博弈上人们一路走来得到的算法,以及背后的思路,还将重点介绍 DeepMind Alpha 系列的背后的思想和种种细节,并对某些问题提出作者个人的思考。
本文授权转载于知乎专栏作者 SIY.Z
https://zhuanlan.zhihu.com/p/31809930

专知公众号转载已获知乎作者SIY.Z授权。
原文地址:https://zhuanlan.zhihu.com/p/31809930
▌摘要
这篇文章从Minimax算法开始,一直到最新的 AlphaGo Zero 和 AlphaZero,旨在介绍完全信息博弈上人们一路走来得到的算法,以及背后的思路。这篇文章还将重点介绍 DeepMind Alpha 系列的背后的思想和种种细节,并对某些问题提出个人的思考。
话说最近DeepMind又搞了不大不小的新闻,他们使用了完全类似 AlphaGo Zero 的同一套算法框架,在完全没有人类下棋数据的情况下,解决了诸多困难的棋类问题,包括国际象棋,将棋以及围棋;在国际象棋,将棋方面轻松碾压当前最强的框架(国际象棋甚至连续100局不败,并且很明显体现了先后手造成的巨大差距)。
他们将这个框架命名为 AlphaZero,也就是简单地比AlphaGo Zero少一个Go。AlphaZero 证实了 ResNet + MCTS 的方法不仅适用于围棋,也适用于大多人类可以掌控玩法的棋类。
至此我们可以认为,简单的完全信息博弈问题可以说是基本被 AlphaZero 解决了(鉴于海量的博弈状态,完全解决几乎是不可能的,但是解决到人们“看不懂在干什么”的程度是可以的,在这个程度以上的解决其实已经没有特别实在的意义了,因此说“基本解决”也不为过)。
更准确的说,AlphaZero解决的是 “有限状态零和完全信息两人博弈” 问题。
注:标准的说法是“有限策略”,但是个人认为对目前大部分棋类而言,“有限状态”可能更切合,因为“有限状态”包含了策略有限,而且基于这一点,大部分棋类可以使用额外的规则使得步数也有限(像围棋就通过各种劫的规则阻止状态的重复,而象棋等都有类似的规则阻止重复或者判定和局)。
这里我们梳理一下后面会提及的一些软件版本:
Stockfish,当今最强的开源国际象棋软件,2016 TCEC 计算机国际象棋锦标赛冠军。人类顶级棋手一般只能和它的弱化版本对抗。
Elmo,日本将棋 Computer Shogi Association (CSA) 世界冠军。
AlphaGo-Fan,DeepMind 第一篇 Nature 论文 Mastering the game of Go with deep neural networks and tree search 中提及的围棋软件,其多次击败欧洲围棋冠军樊麾,最强实力可达职业5段,这是第一个击败职业围棋手的软件。其需要学习人类的围棋对弈,运行时需要数千CPU和数百GPU才能发挥最强性能。
AlphaGo-Lee,在国际公开赛上以4-1击败李世石的版本,引起世界轰动。基本和 AlphaGo-Fan 相同,可能使用了更强的算力(后来的论文中作为基准线时,使用了48个TPU)。其段位约为9.5。
AlphaGo-Master,在野狐等在线围棋对局平台上以快棋(限时1分钟)的形式60连胜世界范围内的顶级职业围棋手,引起棋界轰动,并在乌镇比赛上3-0击败柯洁。其学习的对战棋局来自 AlphaGo-Lee,运行时仅需4个TPU和2个CPU(单个计算节点,也就是只要一个小机箱就够了,峰值功耗预计500W)。棋力据称可以让 AlphaGo-Lee 3子(被戏称为职业20段)
AlphaGo-Zero,DeepMind 第二篇 Nature 论文 Mastering the game of Go without human knowledge 的主角,不使用任何直接间接来自人类的对战棋谱,不使用除了对战规则以外的任何围棋知识,仅用时3天就以100-0的战绩完胜AlphaGo-Lee(黄士杰称“人类千年围棋,zero三天走过”)。其硬件配置同 Master。AlphaGo-Zero 的最强版本对 AlphaGo-Master 100局胜率为 89%
AlphaZero,DeepMind最近的作品,硬件配置和算法基本同 AlphaGo-Zero,但是其同一套算法除了解决围棋外,还能够解决国际象棋和日本将棋问题,并击败了 Stockfish(Stockfish使用了版本 8,64个CPU线程,并调节哈希表至其战力最强)。并且其用仅用8个小时就超过了 AlphaGo-Lee。
具体的 Elo 评分(来自 AlphaGo-Zero 论文):
AlphaGo-Zero: 5185
AlphaGo-Zero(仅含网络,不用任何搜索): 3055
AlphaGo-Master: 4858
AlphaGo-Lee: 3739
AlphaGo-Fan: 3144
200 分的 Elo 差距对应 75% 胜率。
以及它们的功耗对比(按照硬件散热设计功耗TDP计,一般达不到这些样的功耗):
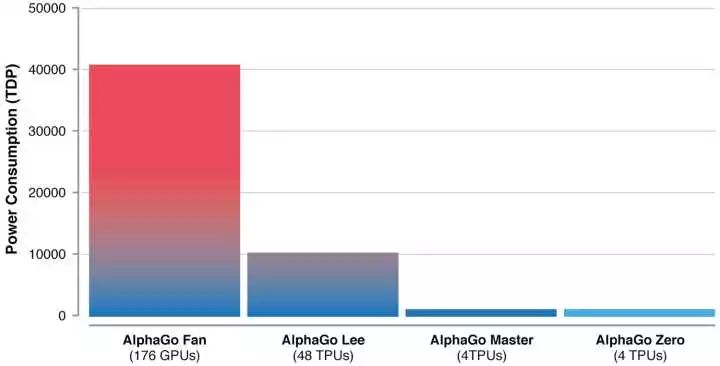
其中 AlphaGo Lee 的功耗大幅下降得益于硬件(TPU 取代 GPU),而 Master 和 Zero 得益于算法 (删除了 Rollout)。
▌有限状态零和完全信息两人博弈
所谓零和完全信息博弈,是指在任意时刻,双方玩家都知道游戏的全部状态(“完全信息”),并且有限步(“有限状态”)之后游戏的结果非胜即负(“零和”),至多加上平局。而双方在游戏中对抗,目的是自己获得尽可能好的结果(“两人博弈”)。
下面为了简单起见,我们假定不可能平局,
知道游戏的全部状态+有限状态意味着,玩家可以通过暴力枚举,来计算所有可能的下法,形成一棵搜索树(习惯称为“Game tree”)。
Game tree 从上而下,第 k 层(最上面的树根计为0层)代表下了 k 步后的游戏局面(即状态)。而边代表不同的走法,同一层的边是同一个玩家的走法,并且不同层间两个玩家交替下棋。
这里初识者可能有疑问:如果某个游戏允许一个玩家一次走多步呢?这个并没有问题,我们只是关心某个玩家的走法对状态的影响。如果一个玩家走了很多步,我们将它当成“复杂的一大步”就行了。
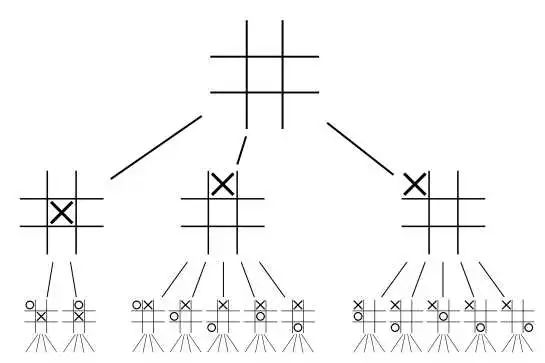
而零和意味着,在某个状态下计算所有可能的下法时,对于某一方,总有一系列后续的应对策略,能够达到最终胜利(或者至少平局);也就是有所谓的“必胜策略”。
这一点一开始会让人觉得有点反直觉:是不是某些状态下,我们无法确认能够有必胜策略呢?
答案是否定的。如果我们并不能找到这样一个必胜策略,就意味着无论如何走棋,对手总有办法阻止你必胜,由于游戏是零和的,这也意味着对手有必胜策略。
这种反直觉实质上是因为我们的无能,我们在刚开局的时候,都会觉得最终是否胜利来自于“之后下的棋的好坏”,因为我们难以看清所有的可能下法。
下面我们会看到,一个枚举了所有的可能下法的对手,是何其地冷酷。
▌冷酷的“上帝”和 Minimax
假设你有一个非常强大的对手,他能够枚举所有可能的下法,那么他就可以画出一个上文说的 Game tree,他可以给所有的终局打分(比如分越高越成功,分越低越失败)。
为了简单起见,我们假设一个游戏4步后就可以结束,并能够得到一个数字表示结果。
不妨令自己先手,枚举所有可能的走法,我们可以得到一棵 Game tree:
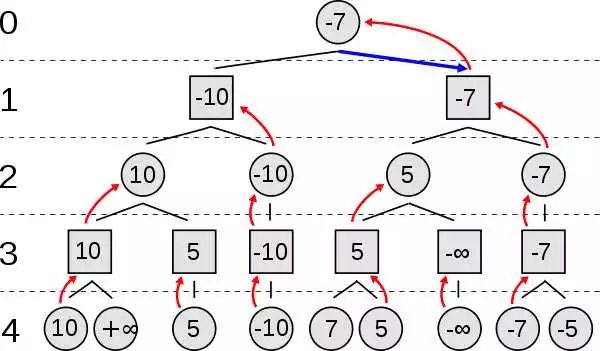
第 4 层是结果。
然后我们使用回溯的思想,反向推导。假如到了第3层,这是对手走棋,对手会怎么走?对手一定会走使得最后结果最小的那步对吧?于是在第3层,我们可以填上下一层相连节点中的最小值(所谓MIN);同理,在第二层,我们会选择最大的值,因为自己总是希望更好(所谓MAX)。于是两方反复形成了MIN-MAX的“对抗”,一直到树的根节点。这个时候你发现结果是-7,这意味着,如果对手一旦做了同样的推理,你是必输的;而你最好的可以取得的结果就是使得结果的评分为-7。
这就意味着,两个“围棋上帝(能够算出围棋的完整Game tree的人)”的对弈,最关键的部分就是猜先,然后两个神陷入沉思,不久后其中一个直接投子认输。
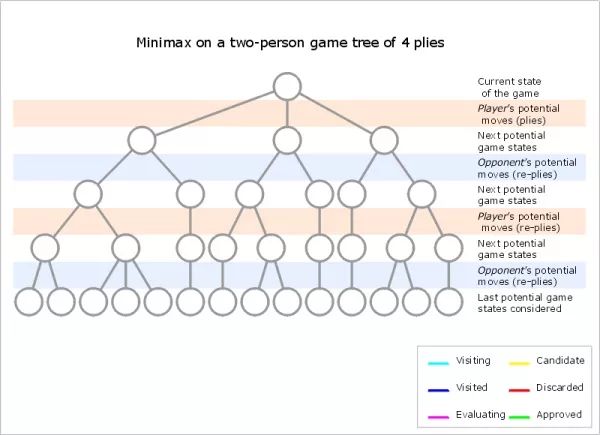
由于其MIN-MAX的特性,对应算法也叫做 Minimax (Min-i-max)。实际中为了效率算法的运行是遵循“深度优先”的原则的,具体见下图(非常慢的GIF)
当然了,现实中还有另外一个冷酷的“上帝”,那就是 Murphy's law (墨菲定律)。如果将墨菲定律视为自己的对手(当然那是极度保守者的行为),那么最好的做法还是采取最稳妥的行为——选择最坏的选择中最好的那个,任何侥幸的心理都会导致更大的损失。
▌Minimax 的复杂性分析:难以企及的完美
Minimax 的关键在于要能够计算出整个 Game tree,而计算出 Game tree 的代价正比于 Game tree 的大小。
Game tree 的大小主要由两个数字决定:
特征深度 d,这代表了游戏典型的走棋步数
分支因子 b,,这代表了游戏典型的每步走棋的可行走法
很容易得出,一个游戏的 Game tree 的大小,约为
只要是一个不太 toy 的游戏, 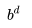
Game tree 过于庞大,使得我们难以枚举树上的所有节点,进而难以达到“完美”的境界。
但是正是难以达到完美,才是游戏的有趣之处,一个靠猜先来赢的游戏并不具备足够的吸引力。
*注:需要着重强调“可观测宇宙”。 “超过了宇宙中的原子数”是个很严谨的说法,因为可观察宇宙大小有限,大尺度结构也大致清楚,我们可以根据可观测的部分较为准确地估计原子数。而“宇宙”就很宽泛了,我们现今仍了解不足。
▌Minimax 的改进:宽度方向和深度方向
由于 Minimax 非常完美的理论特性,后续的改进几乎都是基于 Minimax 的框架。
既然 Minimax 的复杂度主要取决于特征深度 和分支因子 ,那么改进思路主要就是试图减少这两个数。
减少特征深度 的主要方式是有三个:
函数近似。我们构造一个所谓的估值函数(evaluation function),它的目的是估计某个局面的 Minimax 评分,这样我们我们就不用搜索到终盘才能得知结果。一般而言,越接近终盘估计会越准确(因为游戏往往越到残局越简单),所以估值函数不能完全替代搜索。这是 AlphaGo-Zero 和 AlphaZero 的方式。
模拟估计。我们可以从某个局面开始,使用一个相对简单的对弈系统(如果和主程序一样复杂就没有意义了),快速下到终局,用得到的结果作为这个局面的 Minimax 评分的近似。显然这个方法也往往越到终盘越准确。此方法又称为 rollout。
上面两种方法的混合。比如两个的结果加权平均,这是 AlphaGo-Fan 和 AlphaGo-Lee使用的方式。
可以看出,减少特征深度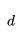
而减少分支因子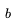
剪枝。剪枝就是去除掉某些明显劣势的走法。最著名的是 Alpha–beta 剪枝,它充分利用了 Minimax 算法的特点,并且仍然可以得到和 Minimax相同的结果(也就是不是近似),是首选的优化。另外也可以用估值函数减掉某些非常坏的走法的分支。
采样估计。其思路是蒙特卡洛(monte-carlo)模拟。我们可以先预估出一个先验概率分布 P,然后再根据 P 采样部分路径用作估计。这种手段对分支因子的减少比较激进,在围棋等分支因子较大的棋类中较常用。Alpha系列采用的就是此类方法。
下面我们将提及这些技术。
下面几小节将介绍一些著名的以减少分支因子为目的的机制
▌Alpha–beta 剪枝
可以说,在AlphaGo系列之前,alpha-beta剪枝是棋类游戏游戏中最主要的优化技术之一(可能即使以后也是如此)。alpha-beta剪枝可以在minimax的基础上无缝地(即不大幅修改原算法,不会降低算法的效力)进行优化。
alpha-beta 的核心思想在于剪去某些明显非最优的分支,其原理基于是Minimax算法的特性,本质上是利用了 min 和 max 的“单调性”。
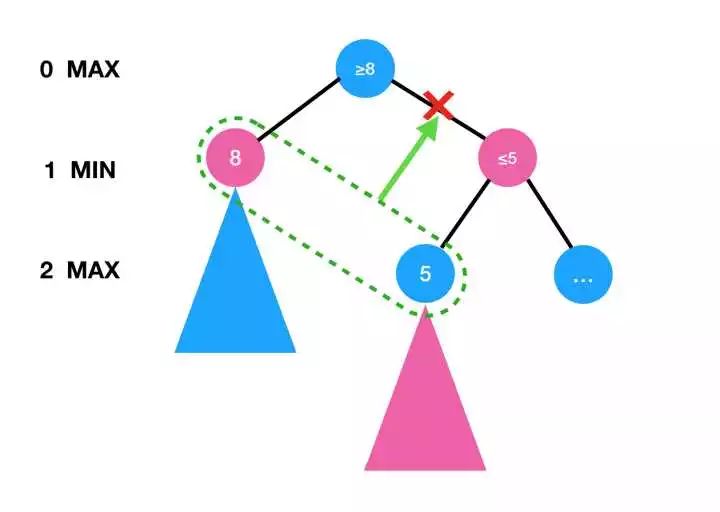
如上图所示,如果在下层的MAX节点发现得到的值为5,那么意味着上层的MIN节点的数值一定不大于5。而如果本层的MAX节点的值已经至少为8(比如因为下层的MIN节点为8),那么就可以剪掉右边的分支(即右边的分支不必继续探索)。
可以看到,如果我们运气很好(实际中依赖估值函数预先猜几个),直接搜到了最好的情况,alpha-beta可以剪去大部分分支。在这种情况下,复杂度可以约化为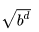
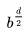
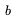
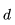
▌蒙特卡洛树搜索(Monte-Carlo Tree Search, MCTS)
蒙特卡洛法的思想非常简单:用随机采样来估计某些数值。最经典的是下面的估算圆周率 π的例子:
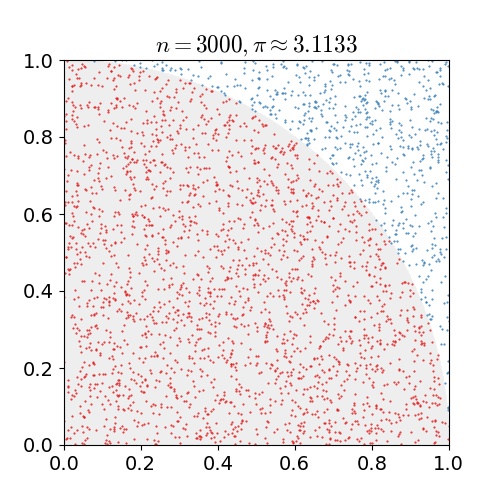
在这个例子中,我们随机向正方形内均匀投点,然后我们计算有多少点在 1/4 圆内(这很容易,比如判断点离原点的欧氏距离),进而可以算出在1/4圆内的点所占的总点数的比例,然后带入圆面积公式就可以估计出 π。
但是,怎么样将蒙特卡洛法用于Game Tree呢?先看一个简单的情况(多臂摇臂机问题):

假设你面前有一排摇臂机,它们的期望回报有差别,显然你希望在最终博弈时尝试胜率更高的那个。
幸运的是,你被允许事先尝试这些摇臂机,但是由于受到时间和精力的限制,你只能尝试一个有限的次数。这实际上就是下棋的情景:你希望走胜率最高的那步,并且你有有限的时间来尝试不同下法(被称为 Exploration,探索),来决定最终使用哪个走法。
Monte-Carlo 法希望这些尝试过程能够最终让(平均价值)最好的选择获得最多次尝试(或者说,让尝试次数和其真正的价值对应;就好像前面示例中投入 1/4 圆的点的个数和其面积对应类似)。一个很简单的方法是,让获得获得回报越高的选择重复选择的可能性越大(被称为 Exploitation,利用)。并且我们在每次利用时顺便也更新平均价值。
但是这个问题有一些麻烦之处:
如果我们把太多的选择放到一个一开始回报很大的选项上,因为尝试次数有限,我们很有可能受到统计涨落的影响,错失一个我们碰巧没有选中或者碰巧头几回价值低但是期望价值很高的选项。这就是 Exploitation & Exploration (E & E) 问题,即我们需要在探索和利用中取得一个平衡。这个平衡要求我们对探索过多的选择进行适当贬值,但是这个贬值又不能降低其“真正价值”,因为一个选择被探索多次后,其平均价值接近真实价值,我们不应为了某个不甚了解的“后起之秀”轻易抛弃一个身经百战的“长老”。
如果我们简单地像 Monte-Carlo 一样一开始简单地对所有的节点均匀采样,效率实在太低了,这对于围棋等复杂问题是不能忍受的(类似完全不剪枝)。如果我们先验地觉得,某个选择更好(比如因为我们已有的经验,朋友的推荐等等),可以提供一个更大的先验概率P用来引导采样。
下面我们介绍 AlphaGo Zero 使用的策略,它是传统的PUCT中策略的改进和简化:
首先,我们定义每个选择的“可利用价值”为(平均)动作价值Q和置信上界U之和。Q 是每次利用时得到的价值的平均, U代表某种“潜在可利用性”。
那么U应该和什么有关呢?首先,更大的先验概率P,对应更大的U ;而如果被利用次数N太多,那么U 应该“贬值”。所以一个初步的设想是:
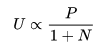
但是对于树搜索而言,有一个问题在于它是有分支的。这意味着分支间还有竞争。因此我们还要考虑到“分支优势”,即一个分支的邻居(即同一局面下的一组选择)也需要给U做贡献,以体现“邻居优势”。毕竟我们得到一个局面下的一个优秀的选择,我们更有兴趣去尝试这个局面下其他选择到底如何。邻居贡献显然要小于自己的贡献,因此我们不妨加个根号(为什么加根号在PUCT等地方有推导):
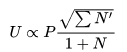
,(上面没有加一,第一次访问这个分支的时候应该要特殊处理一下)。
那么完整的公式的常数应该是什么呢?这是一个超参数,记为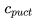
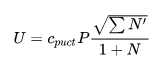
注意到,由于U会导致贬值,所以我们在探索的时候可以采用最贪心的方式:直接选择最大的Q+U,反正随着U 的贬值会导致探索其他的Game Tree上的路径。
那么最后一个问题:Q是价值的平均,那么这些“价值”怎么来?——很简单,搜索到一定深度时直接用估值函数得到一个价值V即可, 然后使用V更新上面所有节点的Q值,同时 N增加1。
我们整理一下思路,就有了整个算法:
选择Q+U 最大的走法,一直往下走,直到碰到还没有计算Q和U值的节点。(称为Select)
遇到还没有计算Q和U值的节点,设置 Q和U为0,并计算这个节点的盘面下的先验概率P,这样 U就有了值。(称为 Expand )
直到到限定深度 L,用估值函数/Rollout直接得出该节点的 Minimax 值V,这个节点是此次树搜索中的叶节点。(称为 Evaluate)
通过回溯,更新从叶节点到根节点路径所有节点的 N全部加1)和 Q(更新平均值)。(称为 Backup)
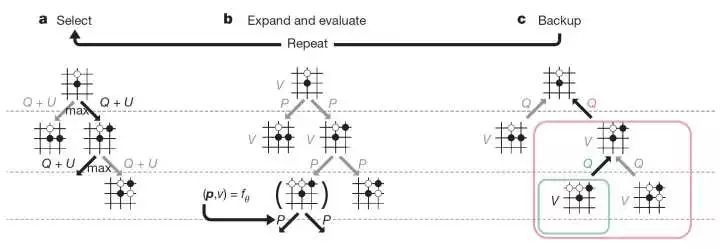
通过若干次这样的迭代(迭代搜索次数也是个超参数),根节点的各个选择的利用次数N(更新平均值)。(称为 Backup)
▌“胜天半目”
看完 MCTS 后,你或许就可以理解为什么 AlphaGo 下棋时常常有半目胜,以及下到接近赢或者接近输的时候,常常各种自损。
最开始人们以为是AlphaGo和人类差距不大,或者 AlphaGo 官子能力很差,所以才常常半目胜。但是到了 Master 版本后,从各种对战中可以发现,即使发生了沧海桑田的大转换后,AlphaGo 无论对人还是对己,大多数棋局依然半目胜。鉴于 AlphaGo Master 从来没有直接输给人类,特别是有些时候能够将半目胜从中盘持续到官子,这基本否认了前面的看法。
其实 “胜天半目” 的理由很简单,在围棋中,赢棋和赢多少比分并没有特别的关联,甚至赢少的目数的情形下,对赢棋更加有利(显然要求你至少半目赢,和要求你至少7目赢,前者简单很多)。
举个例子。试想一下搜索树中有2个可选择分支A和B,而它们的后续分支的输赢目数如下:
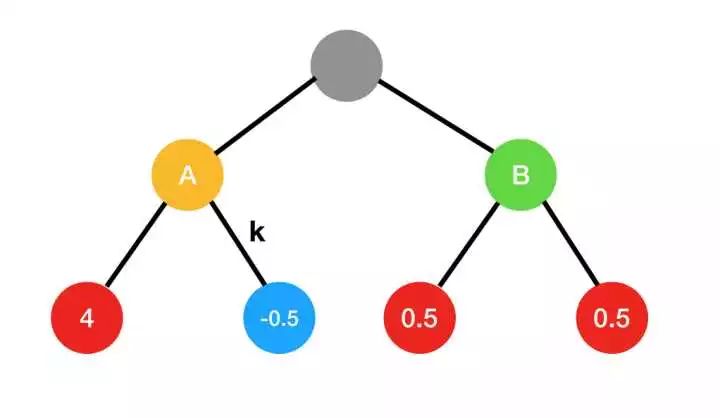
如果下面4个分支到达的概率相同,那么显然A分支的赢的目数的期望更高,为1.75;相应的右边的期望为0.5。也就是希望赢得目数多,应该选择A分支。
而按照胜率而言,A分支胜率50%,B分支胜率100%,尽管都是半目胜。
在实战中,人们往往被A分支巨大的期望吸引,而因为算力不足,无法发现导致轻微输的 k 分支,所以大幅胜出是常见的;而面对AlphaGo这种算力极深的软件,就会无情的被带入 k 分支,因而觉得形势大好,但是莫名其妙输了,而对于AlphaGo而言,很多和人的对局到中盘就已经半目胜了。
▌Alpha-beta 剪枝 vs 蒙特卡洛树搜索(MCTS)
在这一小节,我希望读者能够对这两种减少分支因子b的方法有个比较。
Alpha-beta 剪枝是非常简洁高效、很“硬”的算法,在理论上有着很好的保证(不会出现忽视某个重要分支的情况,除非人给的估值函数太糟),不依赖超参数。Alpha-beta 剪枝不进行特意优化时每一步都要重新计算搜索树,因为其缺乏持续更新的性质,到下一步棋时搜索树底层的估值函数得到的值发生变化,之前所有的结果都需要更新,这会增大计算开销。(当然有支持持续搜索的变种算法,不过肯定要比当前算法复杂很多,或者不能保持原来所有的优良性质,比如 aspiration windows)。
而 MCTS 显然复杂的多,它的“剪枝”力度大很多(由迭代搜索次数这个超参数限定,和棋类无关),从而使得其更加适用于围棋之类分支因子 b特别大的棋类;但是这也使得它性能的保证却不是绝对的(毕竟又要少又要准这种免费午餐是没有的);同时它有很多超参数,比如显式的是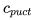
我们可以进一步对比一下在国际象棋中 MCTS 算法和 Alpha-beta 算法的搜索的节点数:
AlphaZero 使用上文介绍的 MCTS 每步搜索了 80000 个节点
Stockfish(目前最强开源国际象棋软件) 使用改进的 Alpha-beta 每步搜索了 70000000 个节点
后者是前者的 875 倍。这就意味着 AlphaZero 中的 MCTS 要在仅有千分之一的值的情况下得到更好的结果。由此可见,MCTS 的有效性强烈依赖于其概率分布生成和估值函数。
▌其他的剪枝策略
这些策略来自 Stockfish,它是当今最强的开源国际象棋软件。
Quiescence Search(”静态搜索“):其对于初始子数比较固定,且存在吃子的棋类比较适用(比如国际象棋)。搜索到一定深度后,其只选择造成吃子或者将军等结果的分支。这是因为吃子或者将军后,盘面变得简单,且明显向终局接近(分支因子和搜索深度都会减小);而且很多情况下会出现兑子,这又大大约束了选择。Quiescence Search 某种意义上就是我们棋理上常说的”简明的下法“。
Null move pruning :很多棋类都有”不走棋“这个选项,这个剪枝假定一般情况下”不走棋“是很糟的策略,如果检测没有出现”迫移“的情形, 就剪去”不走棋“的分支。
Futility pruning: 当我们知道估值的最大可能的变动范围后,可以剪去一些无效的分支(比如超出变动范围的)。可以认为是某种精细化的 alpha-beta 剪枝。
Aspiration windows:其试图复用 alpha-beta 的剪枝结果,避免每次到下一步棋都要重新搜索。
Principal variation search:其可以被认为是 alpha-beta 的一个启发式改进。如果我们能够经常猜中最好的选择,那么 principal variation search 可以大大提高速度;否则其会带来很高的代价。
其他一些领域相关的剪枝:比如根据被吃棋子的重要程度进行剪枝,这在国际象棋等各个棋子价值差异很大的游戏中常见。
下面几小节是关于上文提及的几种减少搜索深度的机制
▌Rollout
Rollout 的思想在于用较简单的策略快速走到终局,用这个分值辅助估计当前局面的 Minimax 值。
显然 rollout 需要消耗大量的运算资源。使用 Rollout 的 AlphaGo-Fan 版本使用了 40 个搜索线程, 1202 个 CPU 和 176 个 GPU 才达到 3140 的 Elo (职业3-5段水平);而后来仅使用估值函数的 AlphaGo-Master 和 AlphaGo-Zero 使用1个计算节点(4个TPUv1+2个CPU*)直接对局职业9段从来没有输过。
由此可见估值函数相对于Rollout高效得多。AlphaGo-Fan 和 AlphaGo-Lee 使用 Rollout 的原因一个是因为 Rollout 在 MCTS 中比较常见,另外一个原因是当时的估值函数很弱,所以他们平均 Rollout 和估值函数的结果来提升效果。AlphaGo-Master 以后 DeepMind 得到了更强的估值函数,于是就放弃了 Rollout*。
*注:具体的CPU信息没有公开,但是一般一个高性能计算节点双路的居多,很少超过4路CPU
DeepMind也没有具体透露Master版本的算法,但是说了“Master版本的算法有了很大的改进,效率明显提高,对战时可以在单个节点上使用4个TPU运行,而不需要分布式版本”,这和AlphaGo Zero的配置完全相同,显然是删掉了 Rollout,并改进了估值函数。
▌估值函数(Evaluation function)及其设计
AlphaGo 系列突破点之一就在于使用神经网络作为估值函数,虽然早先 GNU-Go 等围棋已经将神经网络应用到了围棋中,但是 AlphaGo 系列使用了更深更复杂的网络,并且使用足够的算力证实了神经网络作为估值函数的极大优势。
我么先看看经典的估值函数设计,比如 Stockfish,它是当今最强的开源国际象棋软件。
首先人工选取一些特征,比如剩余可活动的棋子数,被卡住的棋子,最靠前的棋子的攻击态势,国王的潜在威胁,双象的交互,以及各种人工经验得到的表,比如残局状态表,中局评估表,棋子走位表,等等等等。(AlphaZero 论文中给的叙述是:midgame/endgame-specific material point values, material imbalance tables, piece-square tables, mobility and trapped pieces, pawn structure, king safety, outposts, bishop pair, and other miscellaneous evaluation patterns)
给每个特征进行评分(人工设计评分规则),并加权求和(权重是可调节和学习的参数)。得到的结果作为估值结果。
引入 Quiescence Search(上文提到的),在原搜索树的底部尝试继续搜索吃子或者将军的分支,但是这个时候会额外使用一些人工设计的战术以及其他调整,并更新原先的估值结果;如果没有吃子等情形,就直接采用原先的估值结果。
但是这些估值方式,对于围棋是基本无效的。围棋中棋子就黑白两类,因此没有办法设计针对某种棋子的特征设计特别的估值方式;中局和残局(收官)状态非常多,很难打表,而且甚至人本身都很难估计中局的局势,围棋中难以预料的逆转是很常见的事;围棋很难判断”卡住的棋子“,对应于围棋中的死活问题,即使对于职业选手,这也一直是个难题;围棋中吃子并不明确意味着带来巨大的优势,或者把局面变得更简单,甚至吃子造成的劫争会把局面变得更加复杂;围棋的终局目标也很复杂,并不是象棋中”将死“这个非常简单直接的条件,对于初学者而言判断何时已经可以分出胜负也不是一个简单的问题,计算机一般只用 Tromp–Taylor 计分法来判断终局,而这要求一直进行到底才比较准确。
可以说围棋的关键在于整体结构之间那些复杂的,从局部到全局的耦合,而非棋子本身。这导致长期人们难以设计出一个优秀的估值函数,人们估计20年内围棋软件都不是职业选手的对手。
但是”整体结构之间那些复杂的,从局部到全局的耦合“,似乎恰恰对应了另外一类问题的结构?——对,图像。
围棋最小的单位是棋子,对应于图像的像素;而围棋的小局部(靠,扳,断,飞,跳,挂),对应了图像中的简单结构(边缘,角,线条);而围棋的大局部,对应了图像的复杂结构,(窗子,门);而这些复杂的结构以复杂的方式进行作用,形成了整体。
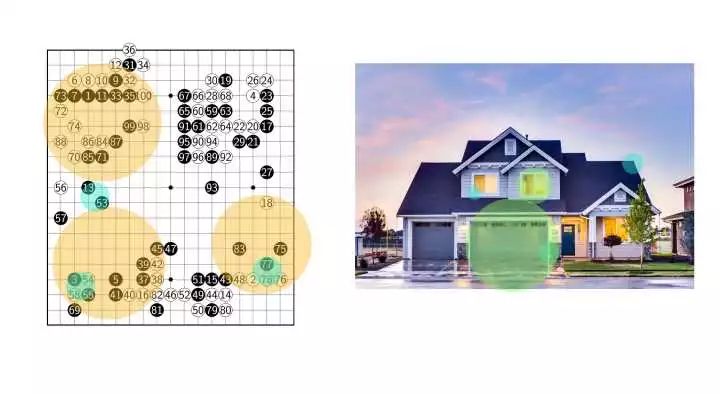
更大的特征,都是由更小的部分有机结合起来的,而这些复杂的结合方式组成了围棋的大局面,或者图像中的主体。
而在图像识别和分析方面,自2012年以来,CNN(卷积神经网络)在 ImageNet 等比赛上一举成名,成为了现在主流方法之一。所以将CNN应用到围棋上也是很自然的想法。
▌卷积神经网络作为估值函数
如果你并不是特别了解卷积神经网络,那么只需要记住它是一个强大的多层非线性变换函数,并且对于图像等的处理非常有效,因此下面我们将它表示为一个函数。
如果棋盘的当前状态记为s,神经网络记为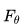
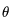
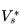
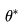
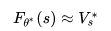
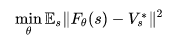
这实质上就是一个非常复杂的拟合问题,拟合的目标是让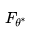
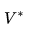
不过,一般而言,卷积神经网络还要分为两个部分,前面的“主体部分”是卷积层(所以叫卷积神经网络),能够抽取“对输入的良好的表示”;而后面的“头”对这个表示进行简单的变换,得到最终的输入。一般而言,“主体部分”越深,神经网络的表示能力越强(这也是“深度学习”的含义之一),因而作为估值函数越接近最有解。从AlphaGo-Lee 到后面版本的最主要区别之一就是网络的加深:

AlphaGo-Lee 使用了较浅的网络用来估值,显然出现了类似“欠拟合”的问题,需要 Rollout 辅助估值;而之后的 Master 和 Zero 就直接扔掉了 Rollout,因为深网络本身足以估值。
除了网络主体外,我们说过还需要一个“头”用来将中间特征转化为值,对于估值而言,这个“头“长这样(以AlphaGo-Zero为例):
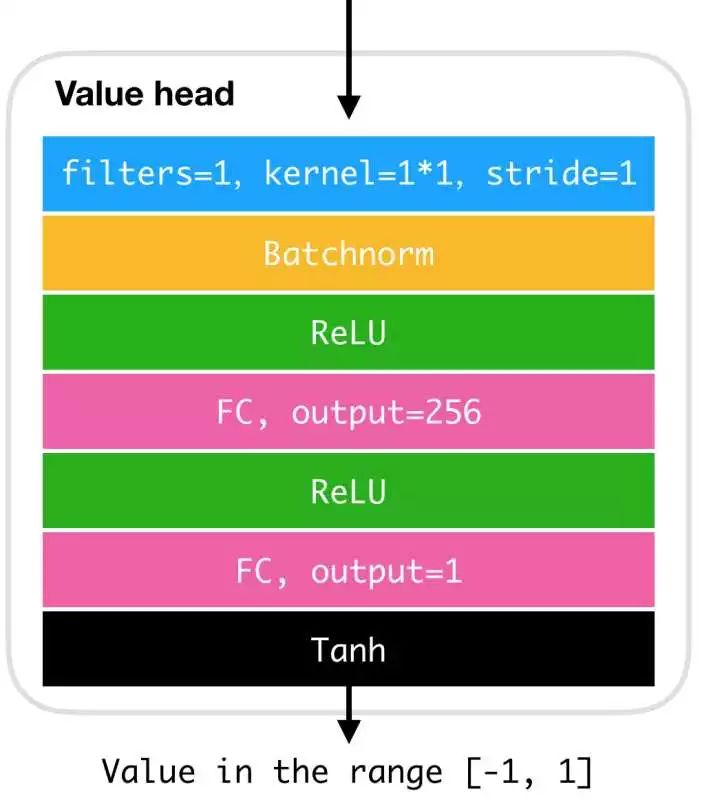
其将上面卷积层的输出”压扁“,然后通过两个全连接层变换后通过 Tanh 得到一个-1到1之间的值,这就是最终的估值。
▌卷积神经网络作为策略函数
上面我们说过,为了减少 MCTS 的选择,我们在选择分支的时候会考虑到一个先验概率分布。这个先验分布告诉我们走每步棋的先验概率,而求解这个这个概率的函数被称为 ”策略函数“。
我们当然可以把每一步都试试,然后用估值函数估计每步走后的 Minimax 值,然后反推出每一步的先验概率。但是这样问题很多:
效率极低。对于围棋这种一步走法很多的,需要数百次估值。
固然更高的 Minimax 值对应了更大的先验概率,但是具体怎么对应不清楚。
所以说我们不妨再搞一个神经网络单独用于估计概率分布(在一个局面下一次直接输出整个分布),这个网络又称为 ”策略网络“。
AlphaGo-Fan 和 Lee 都是使用了两个网络(价值网络+策略网络)。
但是按照”表示学习“的思想,围棋局面的”高级表示“是可以复用的,既可以用来判断价值,也可以用来作为策略,所以,为什么我们不共享一个主体呢?
所以我们给策略网络一个单独的头(AlphaGo-Zero中):
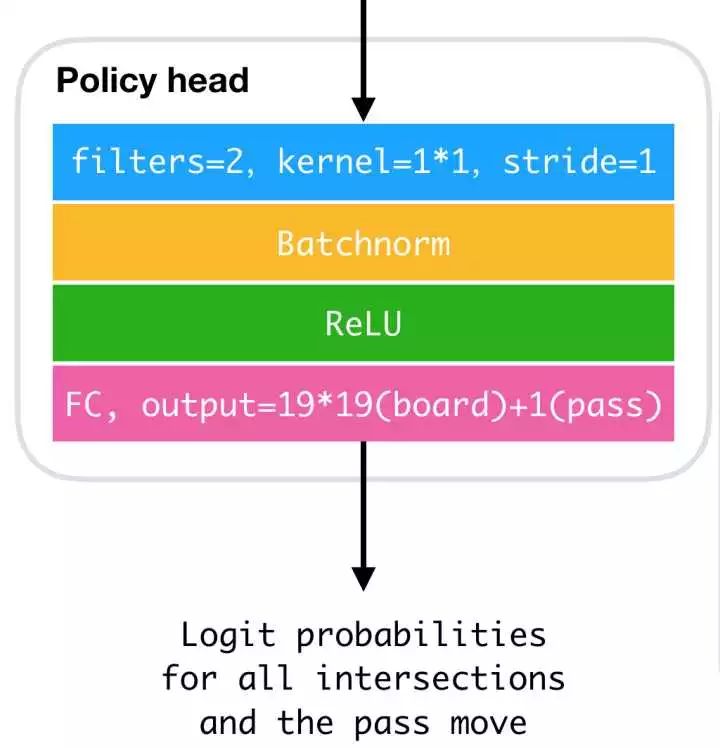
这个头先将前面的”高级特征“压扁,然后通过一个全连接层,直接得到概率分布(注意,直接输出的是Logit分布,变成一般意义上的概率分布需要加一个Softmax层。Logit分布主要是方便神经网络优化,提高数值稳定性并减少计算量)
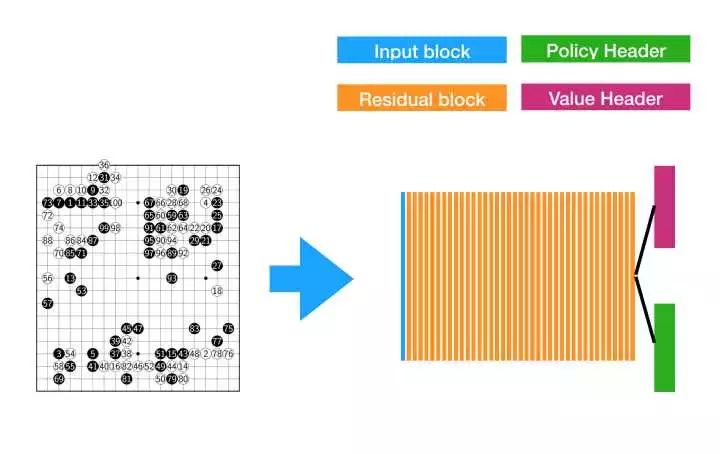
整个网络结构看上去就是这样的:
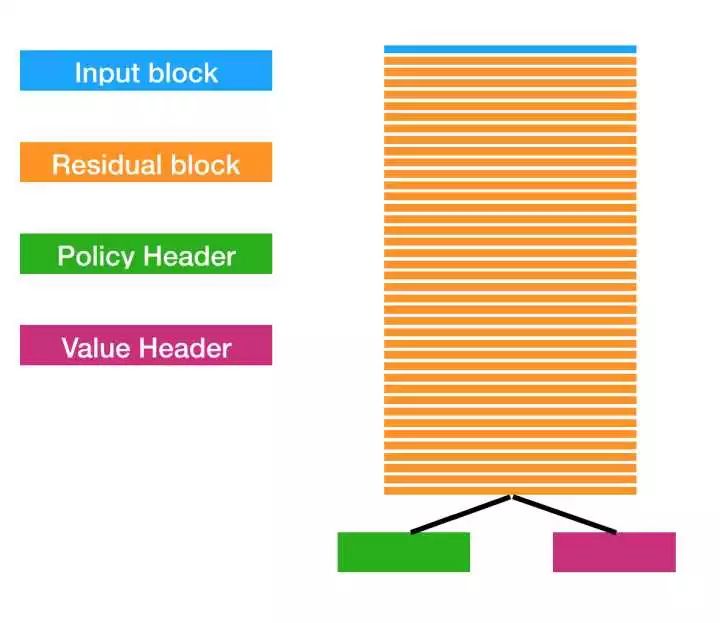
此外还需要注意的是,”主体部分“是由一些称为 Residual Block(残差块)的部分组成的,这是由于特别深的神经网络难以优化,一个解决技巧是引入”残差“,形成残差结构。Residual 几乎是深层 CNN 的标配结构之一。AlphaGo 里面使用的 Residual Block 的结构是:
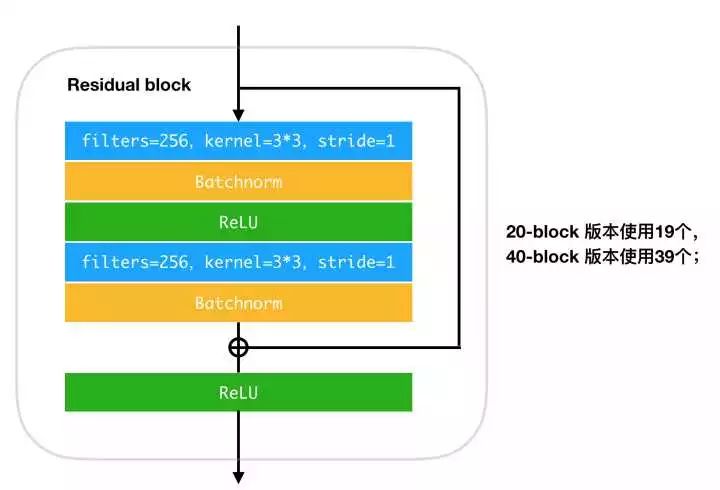
▌估值函数/策略函数:神经网络vs人工设计
”估值函数(Evaluation function)及其设计“ 一节中,我们提到了 Stockfish 中复杂的估值函数设计。这些设计基于人工经验,对国际象棋等比较有效,而对围棋就显得很囧。
而通过”卷积神经网络作为估值函数“一节,我们看到,神经网络作为估值函数时,几乎不关心棋本身,而是网络自身的结构,而这种结构都是非常成熟的,不需要太多刻意设计。通过足够多样本的学习,我们就能够得到一个足够好的估值函数。于是数据和算力取代了设计。
正是这一点让 DeepMind 意识到,这一套方法不仅适用于围棋,同样适用于国际象棋和日本将棋等多数棋类。于是他们稍微改变了一下 AlphaGo-Zero,得到了一个通用的解决此类问题的版本 AlphaZero。
最初人们觉得国际象棋和将棋并不是特别适合 AlphaGo,因为它们的各个棋子差异很大,而且规则比围棋复杂很多,局面上也缺乏围棋的结构性,且存在长距离的攻击。但是 AlphaZero 依然轻松战胜了 Stockfish 和 Elmo,并且搜索时采用的估值次数只有它们的千分之一,这说明只要足够的数据(无论是人给的,还是自己对弈产生的)和算力,神经网络就可以学到足够好的,远超出人们设计能力的估值函数。
我想,用数据和算力取代人工设计这件事情,还会持续发生。
▌估值,搜索和学习:本质何在?
再次回顾最早的 Minimax 算法,我们可以发现一个极大的问题:
要得到一个准确的估值,需要 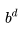
这说明对于极其复杂的棋类,越在线(online)的算法,其实是越不利的,因为尽管付出了巨大的搜索代价,最终用到的决策却很少很少。Minimax 可以说是一种极端的在线方案。
于是各种各样的优化,本质上都是进行某种离线(offline)。这种离线的思想在于压缩搜索树中极大的信息冗余:
alpha-beta 剪枝:利用 Minimax 中 MIN和MAX函数的单调性造成的冗余,从而进行剪枝
MCTS: 期望有限次数随机搜索的统计结论几乎总是和真实的 Minimax 值一致(这样也是说明遍历整个 Game Tree 是冗余的),从而减少遍历次数
估值函数:Minimax算法的执行过程充满冗余,能够被有限参数和步骤的函数或者经验所近似。
Null move pruning: “不走棋”操作往往是冗余的
Aspiration windows:上一步中Alpha-Beta剪枝得到的alpha-beta值构成的窗口往往能够复用,因而重新进行alpha-beta存在冗余性
Quiescence Search:(象棋中)简明的、消灭对方棋子并造成威胁的局面往往足够有利,可以优先探索;相比那种很多步都完全不吃子到处晃的情况可能是冗余。
而神经网络作为一个强大的估值函数,可以认为其是整个Game Tree上的Minimax数值的压缩表示。这点怎么理解呢?
我们不妨换个看法来看 Game Tree 各个节点的 Minimax 值:
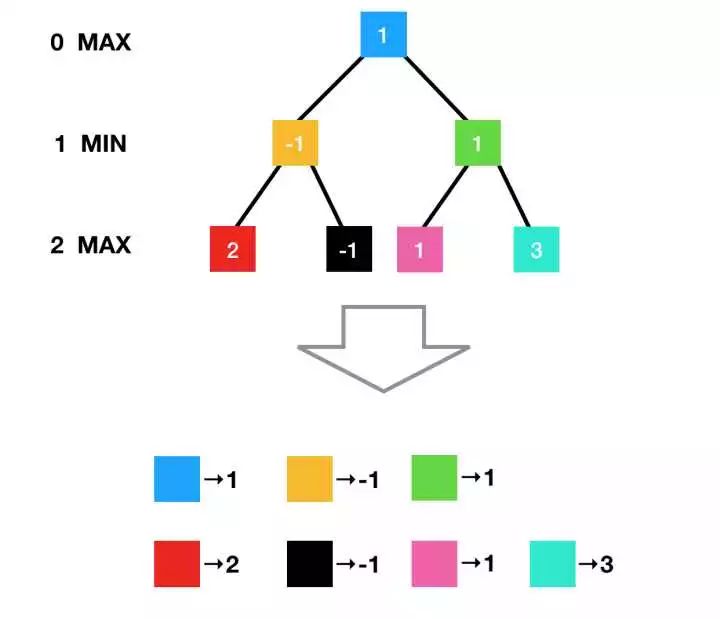
可以看到,Game Tree 上的 Minimax 值完全可以表示为一个“映射表”,即由局面状态映射到一个值。
可以从树上把节点“摘”下来打表并不是显然的,这是因为游戏室“完全状态”的,每个树上的节点都代表了所有的信息,所以它们的估值也是互相独立的。这很容易想象,因为无论你用什么方式下到当前局面,都不会因为之前的方式导致当前局面Minimax值不同;而之后的下法也不会影响Minimax值,如果你感觉下到后面似乎影响到了前面的“估值”,是因为你没有考虑到后面的某些情形造成偏差,而Minimax算法遍历了后面所有的情形,因此当前局面无论如何,Minimax值都不会改变。
很多游戏会对残局进行打表,就是这个原理。但是对整个游戏的 Minimax 值进行打表是不现实的,因为这个表和 Game Tree 的节点一样多,是整个宇宙的原子都可能无法存下的存在。但是所幸的是,这个表和树一样,有大量的冗余,比如:

像上面的表,就可以很简单的由一个正比例函数表示,这是一个极端情况,我们把数据量压缩到了0。
现实情况没有那么简单,我们不能给更复杂的情形找出一个确定的函数打表,但是我们可以给函数一个参数,然后用它代表一个函数系:
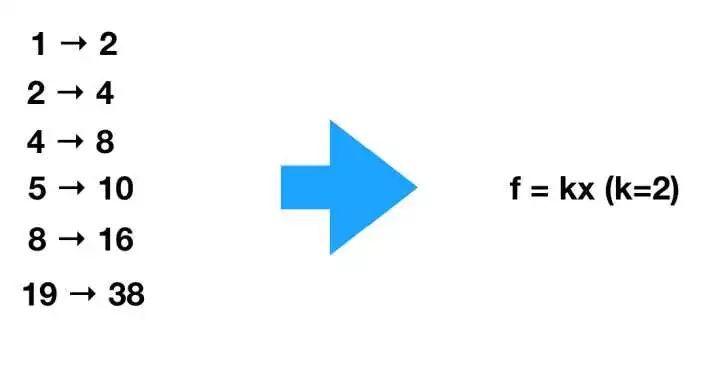
我们可以处理和上面同样的情形,但是我们同时可以处理所有的源和像成比例的表,代价是我们多了一个参数k,但是我们仍然大幅压缩了数据。
围棋找出这样一个函数来代替打表更加困难,但是我们可以提供更复杂的,带更多参数的函数,比如卷积神经网络,然后通过学习的方式找到参数的合适的值(后面会慢慢提):
虽然神经网络具有巨量的参数,但是相比于围棋而言可以忽略不计。可以说卷积神经网络通过学习大幅压缩了围棋搜索树中的冗余,同时保证了失真不是很严重。
同时,神经网络得到任何局面的估值都是常数时间,这和搜索树是非常不同的。这让我想到了李飞飞的得意门生,现任特斯拉人工智能规划师 Andrej Karpathy 在 Medium 上发的“软件 2.0”这篇blog。
Blog 中思考了神经网络等技术作为“第二代软件”等问题。神经网络这些算法最有意思的一点是其时间复杂度往往近似为常数(因为只是简单的函数求值),这和人的行为更加接近:人在很多认知问题上都是和输入无关的,时间近乎固定的处理,而不是像现今的大多数人工设计的算法具有显著的时间复杂度特性;人的直觉思维更像函数查表而不是跑算法。
当然“如何让神经网络学到正确的东西”是个很麻烦的事情,这里我们大多说了神经网络的好处,下面一篇中我们会看到更多乌云。
▌摘要下面一篇的内容
由于发现内容多得超乎我的想象,我决定另起第二篇,这样我也可以尽早收到关于本篇的反馈,下面一篇会有更多尖锐的细节和理论,以及一些反思:
如何迭代数据和神经网络?强化学习是什么?为什么 DeepMind 后来将 Policy Gradient 改为了 Policy Iteration?
在和李世石的比赛中,AlphaGo和李世石都下出了“神之一手”,李世石在第四局凭借他的“神之一手”击败了AlphaGo。那么这些“神之一手”背后的原因是什么?AlphaGo的bug又是什么?为什么后来 Master版本看不到类似的bug?我购买观看了今年 Greg Kohs 的斩获多项奖项和提名的纪录片《AlphaGo》,从背后我们可以推测出很多重要细节。
详细信息不多的 Master 版本采用了怎样的结构?
为什么AlphaZero版本甚至删去了通过比赛选择版本的策略?为什么神经网络在自我对抗训练中没有明显遇到“局部最优”(欠拟合)和“过拟合”的情形?从最近发布的AlphaGo Teach中我们能够推测出哪些重要细节?
为什么选择MCTS+CNN而不是Alpha-Beta剪枝+CNN?MCTS真的比Alpha-Beta剪枝有优势吗?
算法和先验知识:今年NIPS大会之争。NIPS大会上,DeepMind 公布了其围棋程序的最新迭代 AlphaZero。但是 Marcus 激烈地反对 AlphaZero 背后的 “零知识哲学”。又如何评价两方呢?
AlphaZero 和 Stockfish 的比赛“公平”么?如何理解算力差距带来的可能变化?
关于硬件:DeepMind使用的TPU是什么?TPUv1和v2有什么区别?
最近一次修订:12-15 19:08,根据 @阿修比 和 @七彩极光夜 的建议修改了部分事实陈述,在此表示感谢。
上次修订:12-15 14:35,改正了部分错别字和病句,修正了关于 Master 和 Zero 的棋力比较,补充了各个版本 AlphaGo 的 Elo 表以及功耗图。
参考链接:
https://zhuanlan.zhihu.com/p/31809930
-END-
专 · 知
人工智能领域主题知识资料查看获取:【专知荟萃】人工智能领域25个主题知识资料全集(入门/进阶/论文/综述/视频/专家等)
同时欢迎各位用户进行专知投稿,详情请点击:
【诚邀】专知诚挚邀请各位专业者加入AI创作者计划!了解使用专知!
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

请加专知小助手微信(Rancho_Fang),加入专知主题人工智能群交流!

点击“阅读原文”,使用专知!
展开全文



