【论文推荐】最新四篇CVPR2018 视频描述生成相关论文—双向注意力、Transformer、重构网络、层次强化学习
【导读】专知内容组在昨天推出八篇视频描述生成(Video Captioning)相关文章,今天为大家推出CVPR2018最新视频描述生成相关论文,欢迎查看!
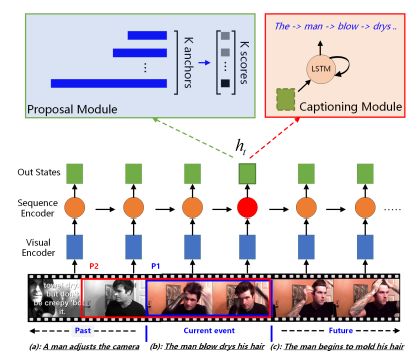
9.Bidirectional Attentive Fusion with Context Gating for Dense Video Captioning(基于双向注意力机制融合上下文控制的密集视频描述生成)
作者:Jingwen Wang,Wenhao Jiang,Lin Ma,Wei Liu,Yong Xu
CVPR2018 spotlight paper
机构:South China University of Technology
摘要:Dense video captioning is a newly emerging task that aims at both localizing and describing all events in a video. We identify and tackle two challenges on this task, namely, (1) how to utilize both past and future contexts for accurate event proposal predictions, and (2) how to construct informative input to the decoder for generating natural event descriptions. First, previous works predominantly generate temporal event proposals in the forward direction, which neglects future video context. We propose a bidirectional proposal method that effectively exploits both past and future contexts to make proposal predictions. Second, different events ending at (nearly) the same time are indistinguishable in the previous works, resulting in the same captions. We solve this problem by representing each event with an attentive fusion of hidden states from the proposal module and video contents (e.g., C3D features). We further propose a novel context gating mechanism to balance the contributions from the current event and its surrounding contexts dynamically. We empirically show that our attentively fused event representation is superior to the proposal hidden states or video contents alone. By coupling proposal and captioning modules into one unified framework, our model outperforms the state-of-the-arts on the ActivityNet Captions dataset with a relative gain of over 100% (Meteor score increases from 4.82 to 9.65).
期刊:arXiv, 2018年4月3日
网址:
http://www.zhuanzhi.ai/document/d410c5011c532c5091904599bda61669
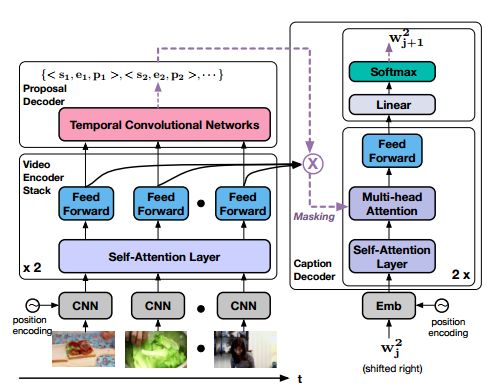
10.End-to-End Dense Video Captioning with Masked Transformer(端到端Masked Transformer密集视频描述生成)
作者:Luowei Zhou,Yingbo Zhou,Jason J. Corso,Richard Socher,Caiming Xiong
To appear at CVPR18
机构:University of Michigan,Salesforce Research
摘要:Dense video captioning aims to generate text descriptions for all events in an untrimmed video. This involves both detecting and describing events. Therefore, all previous methods on dense video captioning tackle this problem by building two models, i.e. an event proposal and a captioning model, for these two sub-problems. The models are either trained separately or in alternation. This prevents direct influence of the language description to the event proposal, which is important for generating accurate descriptions. To address this problem, we propose an end-to-end transformer model for dense video captioning. The encoder encodes the video into appropriate representations. The proposal decoder decodes from the encoding with different anchors to form video event proposals. The captioning decoder employs a masking network to restrict its attention to the proposal event over the encoding feature. This masking network converts the event proposal to a differentiable mask, which ensures the consistency between the proposal and captioning during training. In addition, our model employs a self-attention mechanism, which enables the use of efficient non-recurrent structure during encoding and leads to performance improvements. We demonstrate the effectiveness of this end-to-end model on ActivityNet Captions and YouCookII datasets, where we achieved 10.12 and 6.58 METEOR score, respectively.
期刊:arXiv, 2018年4月3日
网址:
http://www.zhuanzhi.ai/document/bcf3e93f272ef1faba1d5517c77b8df6
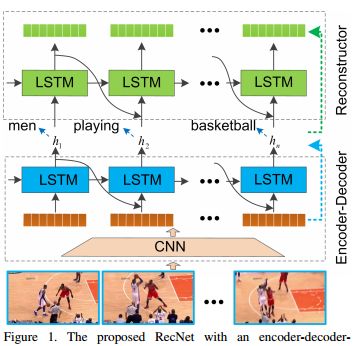
11.Reconstruction Network for Video Captioning(基于重构网络的视频描述生成)
作者:Bairui Wang,Lin Ma,Wei Zhang,Wei Liu
Accepted by CVPR 2018
机构:Shandong University
摘要:In this paper, the problem of describing visual contents of a video sequence with natural language is addressed. Unlike previous video captioning work mainly exploiting the cues of video contents to make a language description, we propose a reconstruction network (RecNet) with a novel encoder-decoder-reconstructor architecture, which leverages both the forward (video to sentence) and backward (sentence to video) flows for video captioning. Specifically, the encoder-decoder makes use of the forward flow to produce the sentence description based on the encoded video semantic features. Two types of reconstructors are customized to employ the backward flow and reproduce the video features based on the hidden state sequence generated by the decoder. The generation loss yielded by the encoder-decoder and the reconstruction loss introduced by the reconstructor are jointly drawn into training the proposed RecNet in an end-to-end fashion. Experimental results on benchmark datasets demonstrate that the proposed reconstructor can boost the encoder-decoder models and leads to significant gains in video caption accuracy.
期刊:arXiv, 2018年3月30日
网址:
http://www.zhuanzhi.ai/document/f978de77187ed42e968388f608cc90c9
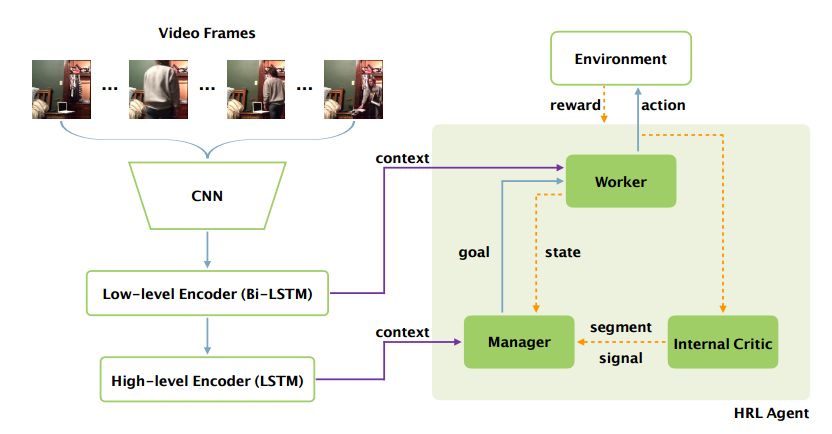
12.Video Captioning via Hierarchical Reinforcement Learning(基于层次强化学习的视频描述生成)
作者:Xin Wang,Wenhu Chen,Jiawei Wu,Yuan-Fang Wang,William Yang Wang
CVPR 2018
机构:University of California
摘要:Video captioning is the task of automatically generating a textual description of the actions in a video. Although previous work (e.g. sequence-to-sequence model) has shown promising results in abstracting a coarse description of a short video, it is still very challenging to caption a video containing multiple fine-grained actions with a detailed description. This paper aims to address the challenge by proposing a novel hierarchical reinforcement learning framework for video captioning, where a high-level Manager module learns to design sub-goals and a low-level Worker module recognizes the primitive actions to fulfill the sub-goal. With this compositional framework to reinforce video captioning at different levels, our approach significantly outperforms all the baseline methods on a newly introduced large-scale dataset for fine-grained video captioning. Furthermore, our non-ensemble model has already achieved the state-of-the-art results on the widely-used MSR-VTT dataset.
期刊:arXiv, 2018年3月29日
网址:
http://www.zhuanzhi.ai/document/0e06d68487c1f38c870eed320088047e
-END-
专 · 知
人工智能领域主题知识资料查看与加入专知人工智能服务群:
【专知AI服务计划】专知AI知识技术服务会员群加入与人工智能领域26个主题知识资料全集获取。欢迎微信扫一扫加入专知人工智能知识星球群,获取专业知识教程视频资料和与专家交流咨询!

请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请加专知小助手微信(扫一扫如下二维码添加),加入专知主题群(请备注主题类型:AI、NLP、CV、 KG等)交流~

请关注专知公众号,获取人工智能的专业知识!
点击“阅读原文”,使用专知
展开全文



