【论文推荐】最新5篇情感分析相关论文—深度学习情感分析综述、情感分析语料库、情感预测性、上下文和位置感知的因子分解模型、LSTM
【导读】专知内容组整理了最近五篇情感分析(Sentiment Analysis)相关文章,为大家进行介绍,欢迎查看!
1. Deep Learning for Sentiment Analysis : A Survey(深度学习情感分析综述)
作者:Lei Zhang,Shuai Wang,Bing Liu
摘要:Deep learning has emerged as a powerful machine learning technique that learns multiple layers of representations or features of the data and produces state-of-the-art prediction results. Along with the success of deep learning in many other application domains, deep learning is also popularly used in sentiment analysis in recent years. This paper first gives an overview of deep learning and then provides a comprehensive survey of its current applications in sentiment analysis.
期刊:arXiv, 2018年1月24日
网址:
http://www.zhuanzhi.ai/document/311d7737ff78accde6ed4ad4881a5364
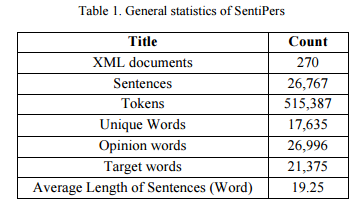
2. SentiPers: A Sentiment Analysis Corpus for Persian(SentiPers:波斯的情感分析语料库)
作者:Pedram Hosseini,Ali Ahmadian Ramaki,Hassan Maleki,Mansoureh Anvari,Seyed Abolghasem Mirroshandel
摘要:Sentiment Analysis (SA) is a major field of study in natural language processing, computational linguistics and information retrieval. Interest in SA has been constantly growing in both academia and industry over the recent years. Moreover, there is an increasing need for generating appropriate resources and datasets in particular for low resource languages including Persian. These datasets play an important role in designing and developing appropriate opinion mining platforms using supervised, semi-supervised or unsupervised methods. In this paper, we outline the entire process of developing a manually annotated sentiment corpus, SentiPers, which covers formal and informal written contemporary Persian. To the best of our knowledge, SentiPers is a unique sentiment corpus with such a rich annotation in three different levels including document-level, sentence-level, and entity/aspect-level for Persian. The corpus contains more than 26000 sentences of users opinions from digital product domain and benefits from special characteristics such as quantifying the positiveness or negativity of an opinion through assigning a number within a specific range to any given sentence. Furthermore, we present statistics on various components of our corpus as well as studying the inter-annotator agreement among the annotators. Finally, some of the challenges that we faced during the annotation process will be discussed as well.
期刊:arXiv, 2018年1月24日
网址:
http://www.zhuanzhi.ai/document/f0820c5d86bac376282ac7a6cf752922
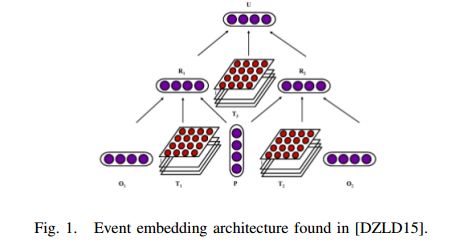
3. Sentiment Predictability for Stocks(基于股票的情感预测性研究)
作者:Jordan Prosky,Xingyou Song,Andrew Tan,Michael Zhao
摘要:In this work, we present our findings and experiments for stock-market prediction using various textual sentiment analysis tools, such as mood analysis and event extraction, as well as prediction models, such as LSTMs and specific convolutional architectures.
期刊:arXiv, 2018年1月19日
网址:
http://www.zhuanzhi.ai/document/580ac48a828f12033f2f484304affae2
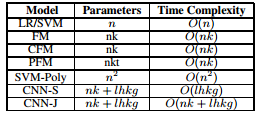
4. Contextual and Position-Aware Factorization Machines for Sentiment Classification(情感分类:基于上下文和位置感知的因子分解模型)
作者:Shuai Wang,Mianwei Zhou,Geli Fei,Yi Chang,Bing Liu
摘要:While existing machine learning models have achieved great success for sentiment classification, they typically do not explicitly capture sentiment-oriented word interaction, which can lead to poor results for fine-grained analysis at the snippet level (a phrase or sentence). Factorization Machine provides a possible approach to learning element-wise interaction for recommender systems, but they are not directly applicable to our task due to the inability to model contexts and word sequences. In this work, we develop two Position-aware Factorization Machines which consider word interaction, context and position information. Such information is jointly encoded in a set of sentiment-oriented word interaction vectors. Compared to traditional word embeddings, SWI vectors explicitly capture sentiment-oriented word interaction and simplify the parameter learning. Experimental results show that while they have comparable performance with state-of-the-art methods for document-level classification, they benefit the snippet/sentence-level sentiment analysis.
期刊:arXiv, 2018年1月19日
网址:
http://www.zhuanzhi.ai/document/0d976d27d9a807207642445ba90c82b9
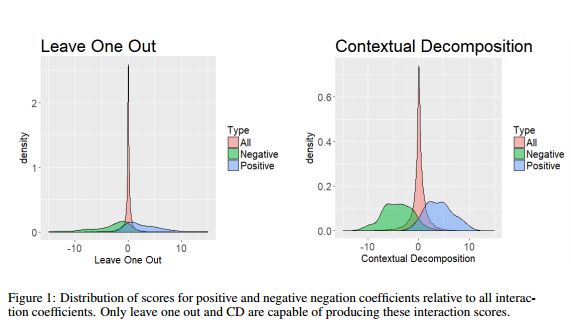
5. Beyond Word Importance: Contextual Decomposition to Extract Interactions from LSTMs(超越单词重要性:上下文分解的方式从LSTMs中提取交互性)
作者:W. James Murdoch,Peter J. Liu,Bin Yu
摘要:The driving force behind the recent success of LSTMs has been their ability to learn complex and non-linear relationships. Consequently, our inability to describe these relationships has led to LSTMs being characterized as black boxes. To this end, we introduce contextual decomposition (CD), an interpretation algorithm for analysing individual predictions made by standard LSTMs, without any changes to the underlying model. By decomposing the output of a LSTM, CD captures the contributions of combinations of words or variables to the final prediction of an LSTM. On the task of sentiment analysis with the Yelp and SST data sets, we show that CD is able to reliably identify words and phrases of contrasting sentiment, and how they are combined to yield the LSTM's final prediction. Using the phrase-level labels in SST, we also demonstrate that CD is able to successfully extract positive and negative negations from an LSTM, something which has not previously been done.
期刊:arXiv, 2018年1月17日
网址:
http://www.zhuanzhi.ai/document/5f3ec47b431c41cf1a2974480fa9f20d
-END-
专 · 知
人工智能领域主题知识资料查看获取:【专知荟萃】人工智能领域26个主题知识资料全集(入门/进阶/论文/综述/视频/专家等)
同时欢迎各位用户进行专知投稿,详情请点击:
【诚邀】专知诚挚邀请各位专业者加入AI创作者计划!了解使用专知!
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

请加专知小助手微信(Rancho_Fang),加入专知主题人工智能群交流!
点击“阅读原文”,使用专知!
展开全文



