【干货】Dropout在RNN中的应用综述
【导读】这篇文章中,提供了Dropout的背景和概述,以及应用于使用LSTM / GRU递归神经网络的语言建模的参数分析。
作者|Adrian G
编译|专知
整理|Yingying
Dropout
受性别在进化中的作用的启发,Hinton等人最先提出Dropout,即暂时从网络中移除神经网络中的单元。 Srivastava等人将Dropout应用于前馈神经网络和受限玻尔兹曼机,并注意到隐层0.5,输入层0.2的 dropout 率 适用于各种任务。
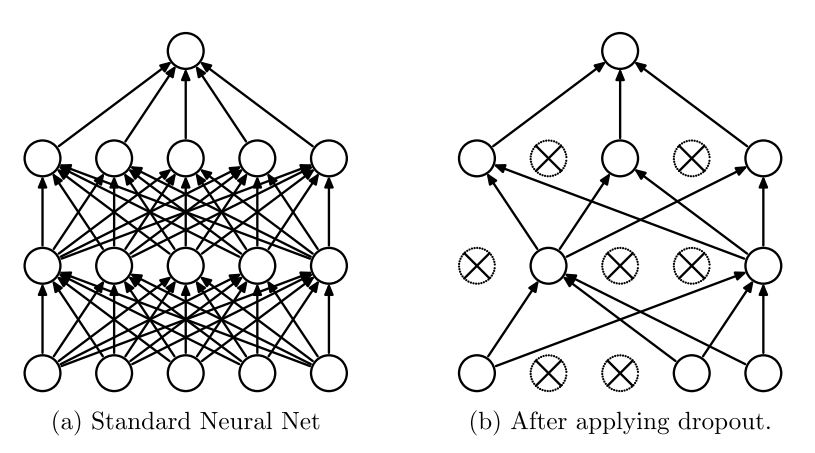
图1. a)标准神经网络,没有dropout。 b)应用了dropout的神经网络。
Srivastava等人的工作的核心概念是“在加入了dropout的神经网络在训练时,每个隐藏单元必须学会随机选择其他单元样本。这理应使每个隐藏的单元更加健壮,并驱使它自己学到有用的特征,而不依赖于其他隐藏的单元来纠正它的错误“。在标准神经网络中,每个参数通过梯度下降逐渐优化达到全局最小值。因此,隐藏单元可能会为了修正其他单元的错误而更新参数。这可能导致“共适应”,反过来会导致过拟合。而假设通过使其他隐藏单元的存在不可靠,dropout阻止了每个隐藏单元的共适应。
对于每个训练样本,重新调整网络并丢弃一组新的神经元。在测试时,权重需要乘以相关单元的dropout率。
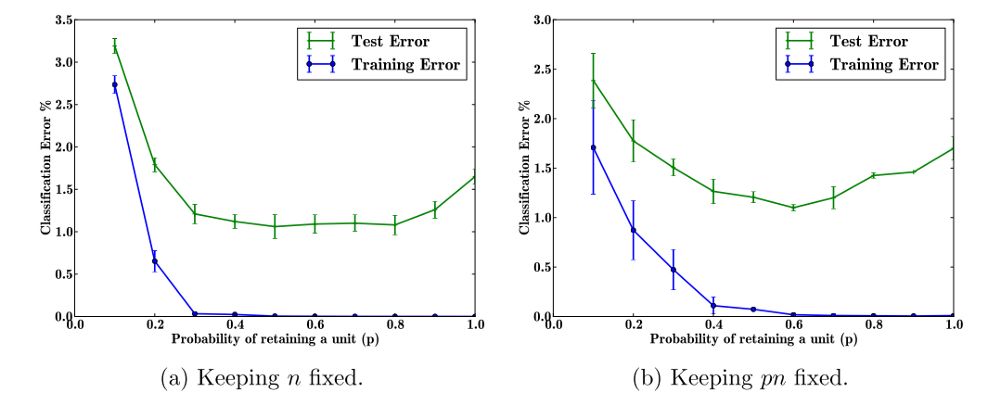
图2. (a) 隐藏单元数(n)固定时的误差 (2)dropout后隐藏单元数固定。
我们可以在图2a中看到,测试误差在保持神经元(1-dropout)的概率为0.4到0.8之间是稳定的。 随着dropout率降低到c以下 0.2(P> 0.8),测试时间误差会增加。Dropout率过高时(p <0.3),网络欠拟合。
Srivatava等进一步发现“随着数据集变大,dropout的增益增加到一个点然后下降。 这表明,对于任何给定的网络结构和dropout率,存在一个“最佳点”。
Srivastava等用伯努利分别来表示隐藏单元被激活的概率,其中值1为概率p,否则为0。
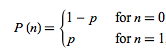
dropout的示例代码如下:
class Dropout():
def __init__(self, prob=0.5):
self.prob = prob
self.params = []
def forward(self,X):
self.mask = np.random.binomial(1,self.prob,size=X.shape) / self.prob
out = X * self.mask
return out.reshape(X.shape)
def backward(self,dout):
dX = dout * self.mask
return dX,[]
DropConnect
在Dropout之后,Wan等人的进一步提出了DropConnect,它“通过随机丢弃权重而不是激活来扩展Dropout”。 “使用Drop Connect, drop的是每个连接,而不是每个输出单元。”与Dropout一样,该技术仅适用于全连接层。
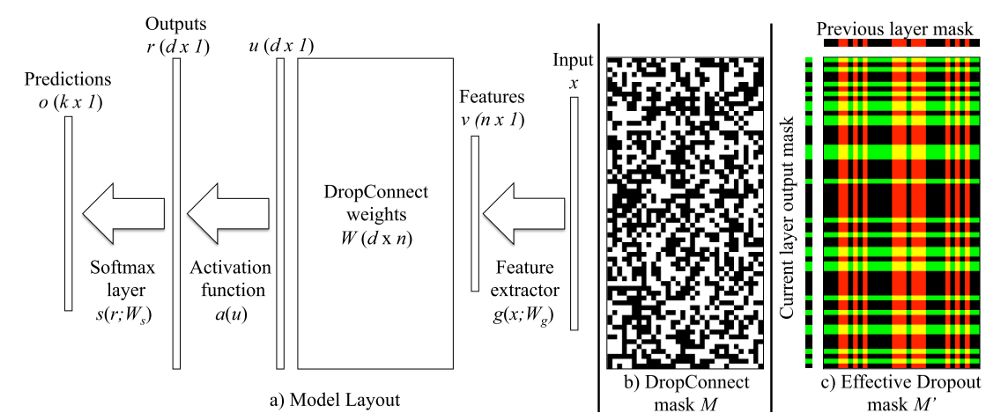
图3. (a)单个DropConnect层的示例模型布局。 在输入x上运行特征提取器g()之后,随机实例化掩码M(例如(b)。掩蔽的权重与该特征向量相乘以产生u,其是 激活函数a和softmax层s的输入。 为了进行比较,c)显示了Dropout在应用于前一层的输出(列)和该层的输出(行)时使用的元素的有效权重掩码。
如下图所示,我们可以形象说明Droput的DropConnect的差异。 通过将dropout应用于输入权重而不是激活,DropConnect可以推广到全连接网络层的整个连接结构。
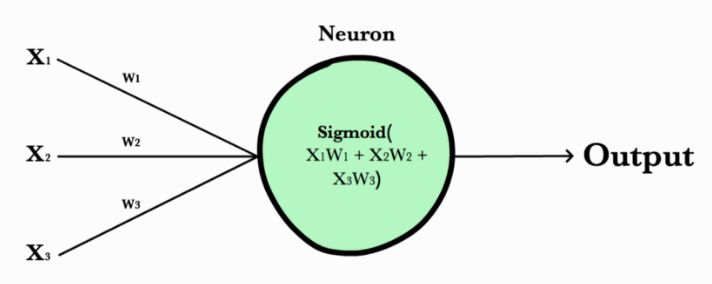
图4. 神经元将一系列权重作为输入,并应用非线性激活函数来生成输出。
上面提到的两种dropout方法被应用于前馈卷积神经网络。 RNN与仅前馈神经网络的不同之处在于先前的状态反馈到网络中,允许网络保留先前状态。 因此,将标准dropout应用于RNN会限制网络保留先前状态的能力,从而阻碍其性能。 Bayer等人指出了将dropout应用于递归神经网络(RNN)的问题。如果将完整的输出权重向量设置为零,则“在每次前向传递期间导致RNN动态变化是非常显著的。”
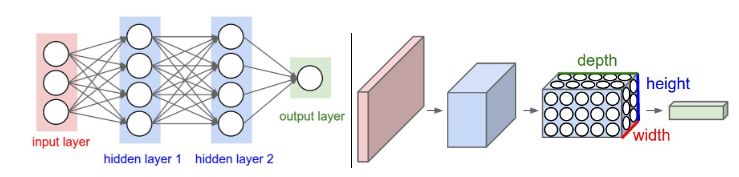
图5. 常规前馈和(前馈)卷积神经网络(ConvNet)的示例。
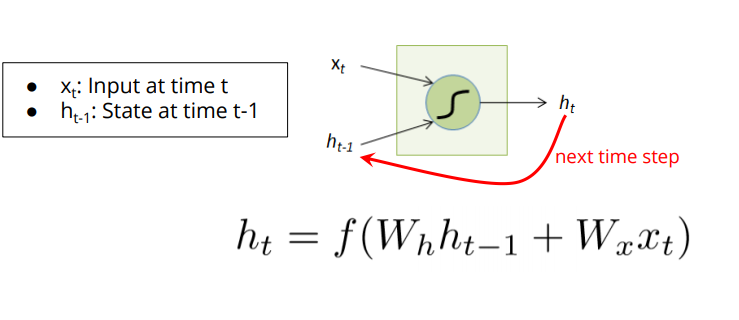
图6. RNN中应用dropout
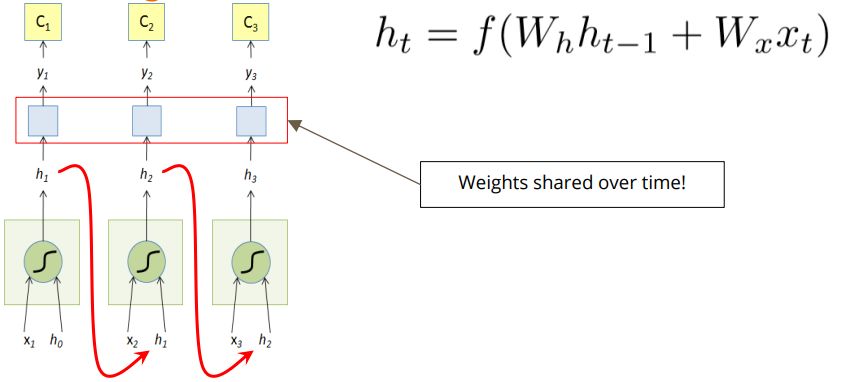
图7.上述模型展开RNN后
将Dropout应用于RNN的代码
class RNN:
# ...
def step(self, x):
# update the hidden state
self.h = np.tanh(np.dot(self.W_hh, self.h) + np.dot(self.W_xh, x))
# compute the output vector
y = np.dot(self.W_hy, self.h)
return y
rnn = RNN()
y = rnn.step(x) # x is an input ve
Dropout用于RNN
作为克服应用于RNN的dropout性能问题的一种方法,Zaremba和Pham等仅将dropout应用于非循环连接(Dropout未应用于隐藏状态)。 “通过不对循环连接使用dropout,LSTM可以从dropout正则化中受益,而不会牺牲其宝贵的记忆能力。”
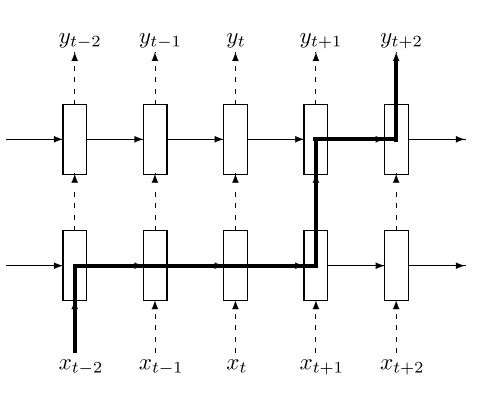
图8. 规则化多层RNN。 Dropout仅适用于非循环连接(即仅应用于前馈虚线)。 粗线显示了LSTM中典型的信息流路径。 信息受到dropoutL + 1次的影响,其中L是网络的深度。
变分Dropout
Gal和Ghahramani(2015)分析了将Dropout应用于仅前馈RNN的部分,发现这种方法仍然导致过拟合。 他们提出了“变分Dropout”,通过重复“输入,输出和循环层的每个时间步长相同的dropout掩码(在每个时间步骤丢弃相同的网络单元)”,使用贝叶斯解释,他们看到了语言的改进 建模和情感分析任务超过'纯dropout'。
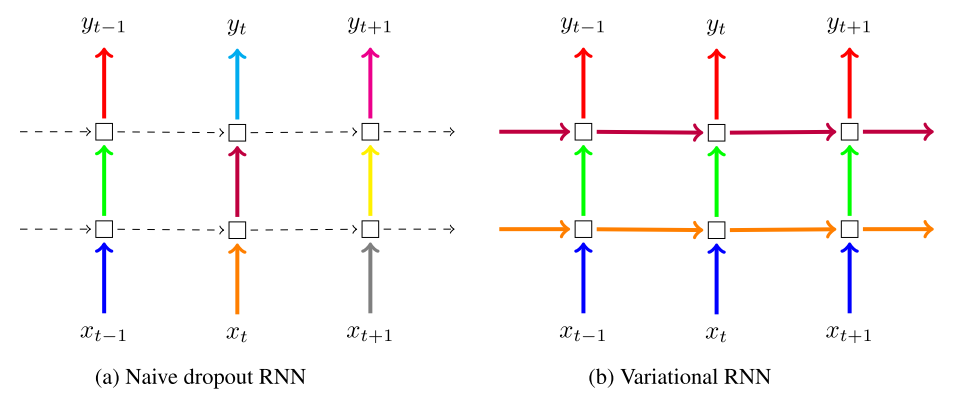
图9. 朴素dropout(a)在不同的时间步长使用不同的掩模,在循环层上没有dropout。 变分dropout(b)在每个时间步长使用相同的压差掩模,包括循环层(颜色表示Dropout掩模,实线表示dropout,虚线表示没有dropout的标准连接)。
循环Dropout
与Moon和Gal和Ghahramani一样,Semeniuta等人提出将dropout应用于RNN的循环连接,以便可以对循环权重进行正则化以提高性能。 Gal和Ghahramani使用网络的隐藏状态作为计算门值和小区更新以及使用dropout的子网络的输入来正则化子网络(图9b)。 Semeniuta等人的不同之处在于他们认为“整个架构以隐藏状态为关键部分并使整个网络正则化”。 这类似于Moon等人的概念(如图9a所示),但Semeniuta等人发现根据Moon等人直接丢弃先前的状态产生了混合结果,而将dropout应用于隐藏状态更新向量是一种更有原则的方法。
“我们的技术允许在模型权重上添加强大的正则化器,负责学习短期和长期依赖性,而不会影响捕获长期关系的能力,这对于处理自然语言时的模型尤其重要。“
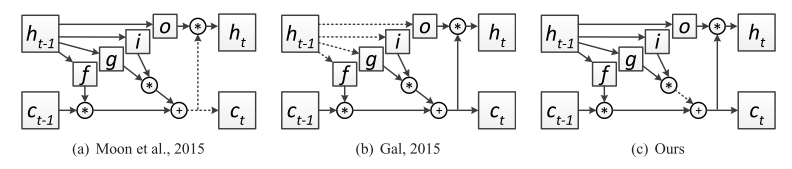
图10. Semeniuta等人。 “在LSTM网络的循环连接中三种类型的dropout的例证。 虚线箭头表示断开的连接。 为清楚起见,省略了输入连接。“ 注意Semeniuta等人如何。 (2016)将重复dropout应用于LSTM存储器单元的更新。
“我们证明,当应用于LSTM中的隐藏状态更新矢量而非隐藏状态时,循环 dropout最有效; (ii)当我们的,循环 dropout率与标准的前向dropout率相结合时,我们观察到网络性能有所改善,尽管这种改善的程度取决于dropout率的值; (iii)与我们的期望相反,使用我们的递归dropout方法时,使用逐步和序列掩模采样训练的网络产生类似的结果,两者都优于Moon等人提出的dropout方案。
Zoneout
作为dropout的一个变种,Krueger等人提出了Zoneout,它“不是将某些单位的激活设置为0,Zoneout随机替换某些单位的激活与他们从前一个时间步的激活。”这“使网络更容易保留以前时间步的信息向前发展,促进而不是阻碍梯度信息向后流动“。
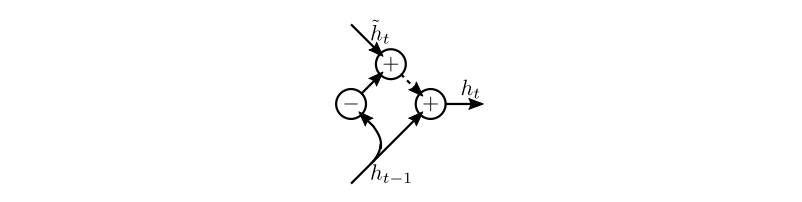
图11. Zoneout作为dropout的特例; ~ht是下一个时间步的单位h的隐藏激活(如果没有分区)。 可以将Zoneout视为在隐藏状态增量上应用dropout,〜ht - ht-1。 当该更新被删除时(由虚线表示),ht变为ht-1。
虽然循环dropout和Zoneout都能防止在GRU / LSTMS的状态/单元中建立的长期记忆丢失,“zoneout通过精确保留单位的激活来实现这一点。 当分区LSTM的隐藏状态(不是存储器单元)时,这种差异是最显着的,因为LSTM中没有类似的循环dropout。 饱和输出门或输出非线性会导致反复dropout遭受梯度消失,在这种情况下,Zoneout仍然有效地传播梯度。 此外,虽然循环dropout方法特定于LSTM和GRU,但zoneout推广到任何依次建立其输入的分布式表示的模型,包括朴素RNN。“
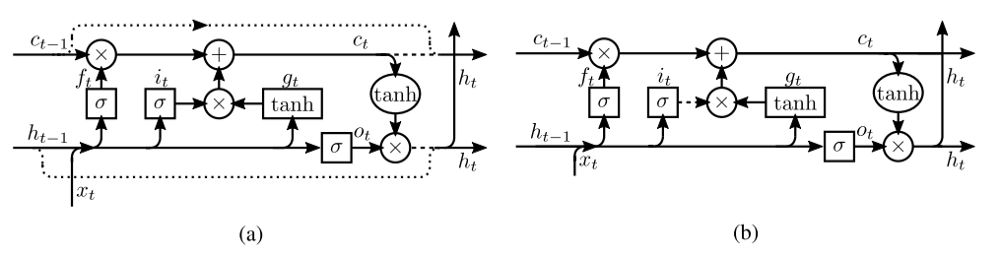
图12. (a)Zoneout,与(b)LSTM中的循环dropout策略。 虚线为零掩码; 在zoneout中,相应的虚线用相应的相反零掩码掩盖。 矩形节点是嵌入层。
用TensorFlow实现Zoneout的核心思想
if self.is_training:
new_state = (1 - state_part_zoneout_prob) * tf.python.nn_ops.dropout(
new_state_part - state_part, (1 - state_part_zoneout_prob),
seed=self._seed) + state_part
else:
new_state = state_part_zoneout_prob * state_part
+ (1 - state_part_zoneout_prob) * new_state_part
AWD-LSTM
在关于语言建模的RNN正规化的开创性工作中,Merity等人提出了一种他们称为AWD-LSTM的方法。在这种方法中,Merity等人使用对隐藏权重矩阵使用DropConnect,而所有其他dropout操作使用变分dropout,以及包括随机长度在内的其他几种正则化策略反向传播到时间(BPTT),激活正则化(AR)和时间激活正则化(TAR)。
关于DropConnect, Metity等人年提到“由于相同的权重在多个时间步长重复使用,同一个权重在整个前向和后向传播中保持下降。结果类似于变分dropout,它通过对ht-1执行dropout,将相同的dropout掩码应用于LSTM内的循环连接,除了将dropout应用于循环权重。“
关于变分dropout的使用,Metity等注意到“mini-batch中的每个示例都使用独特的dropout掩模,而不是在所有示例中使用单个dropout掩模,确保元素的多样性。”
利用Gal&Ghahramani的嵌入式dropout,Metity等人还注意到,这“相当于在字级别对嵌入矩阵执行dropout,其中dropout是在所有字向量的嵌入中广播的。” “由于在用于完整前向和后向传递的嵌入矩阵上发生了dropout,这意味着特定字的所有出现都将在该传递中消失,相当于在one-hot嵌入和之间的连接上执行变分dropout。
Merity等人使用的代码:
class LockedDropout(nn.Module):
def __init__(self):
super().__init__()
def forward(self, x, dropout=0.5):
if not self.training or not dropout:
return x
m = x.data.new(1, x.size(1), x.size(2)).bernoulli_(1 - dropout)
mask = Variable(m, requires_grad=False) / (1 - dropout)
mask = mask.expand_as(x)
return mask * x
因此在RNNModel(nn.Module)中应用前向方法dropout的位置(注意self.lockdrop = LockedDropout(mask = mask)):
def forward(self, input, hidden, return_h=False):
emb = embedded_dropout(self.encoder, input, dropout=self.dropoute
if self.training else 0)
emb = self.lockdrop(emb, self.dropouti)
raw_output = emb
new_hidden = []
raw_outputs = []
outputs = []
for l, rnn in enumerate(self.rnns):
current_input = raw_output
raw_output, new_h = rnn(raw_output, hidden[l])
new_hidden.append(new_h)
raw_outputs.append(raw_output)
if l != self.nlayers - 1:
raw_output = self.lockdrop(raw_output, self.dropouth)
outputs.append(raw_output)
hidden = new_hidden
output = self.lockdrop(raw_output, self.dropout)
outputs.append(output)
result = output.view(output.size(0)*output.size(1), output.size(2))
if return_h:
return result, hidden, raw_outputs, outputs
return result, hidden
DropConnect应用于上述相同RNNModel的init方法中:
if rnn_type == 'LSTM':
self.rnns = [torch.nn.LSTM(ninp if l == 0 else nhid,
nhid if l != nlayers - 1
else (ninp if tie_weights else nhid),
1, dropout=0) for l in range(nlayers)]
if wdrop:
self.rnns = [WeightDrop(rnn, ['weight_hh_l0'], dropout=wdrop)
for rnn in self.rnns]
WeightDrop类的关键部分是以下方法:
def _setweights(self):
for name_w in self.weights:
raw_w = getattr(self.module, name_w + '_raw')
w = None
if self.variational:
mask = torch.autograd.Variable(torch.ones(raw_w.size(0), 1))
if raw_w.is_cuda: mask = mask.cuda()
mask = torch.nn.functional.dropout(mask, p=self.dropout,
training=True)
w = mask.expand_as(raw_w) * raw_w
else:
w = torch.nn.functional.dropout(raw_w, p=self.dropout,
training=self.training)
setattr(self.module, name_w, w)
https://medium.com/@bingobee01/a-review-of-dropout-as-applied-to-rnns-72e79ecd5b7b
References:
J. Bayer, C. Osendorfer, D. Korhammer, N. Chen, S. Urban, P. van der Smagt. 2013. On Fast Dropout and its Applicability to Recurrent Networks.
Y. Bengio, P. Simard, P. Frasconi. 1994. Learning long-term dependencies with gradient descent is difficult.
cs231n. https://cs231n.github.io/convolutional-networks/
deepnotes.io. https://deepnotes.io/dropout
Y. Gal, abd Z. Ghahramani. 2015. A Theoretically Grounded Application of Dropout in Recurrent Neural Networks.
G. E. Hinton, N. Srivastava, A. Krizhevsky, I. Sutskever and R. R. Salakhutdinov. 2012. Improving neural networks by preventing co-adaptation of feature detectors.
karpathy.github.io. https://karpathy.github.io/2015/05/21/rnn-effectiveness/
D. Krueger, T. Maharaj, J. Kramár, M. Pezeshki, N. Ballas, N. Rosemary Ke, A. Goyal, Y. Bengio, A. Courville, C. Pal. 2016. Zoneout: Regularizing RNNs by Randomly Preserving Hidden Activations.
S. Merity, N. Shirish Keskar, R. Socher. 2017. Regularizing and Optimizing LSTM Language Models.
ml-cheatsheet.readthedocs.io. https://ml-cheatsheet.readthedocs.io/en/latest/nn_concepts.html
T. Moon, H. Choi, H. Lee, I. Song. 2015. Rnndrop: A novel dropout for rnns.
P. Morerio, J. Cavazza, R. Volpi, R.Vidal, V. Murino. 2017. Curriculum Dropout
A. Narwekar, A. Pampari. 2016. Recurrent Neural Network Architectures. http://slazebni.cs.illinois.edu/spring17/lec20_rnn.pdf
V. Pham, T. Bluche, C. Kermorvant, J. Louradour. 2013. Dropout improves Recurrent Neural Networks for Handwriting Recognition
S. Semeniuta, A. Severyn, E. Barth. 2016. Recurrent Dropout without Memory Loss.
N. Srivastava, G. Hinton, A. Krizhevsky, I. Sutskever, R. Salakhutdinov. 2014. Dropout: A Simple Way to Prevent Neural Networks from Overfitting.
L. Wan, M. Zeiler, Matthew, S. Zhang, Y. LeCun, R. Fergus. 2013. Regularization of neural networks using dropconnect.
W. Zaremba, I. Sutskever, O. Vinyals. 2014. Recurrent Neural Network Regularization
K. Zolna, D. Arpit, D. Suhubdy, Y. Bengio. 2017. Fraternal Dropout
-END-
专 · 知
人工智能领域26个主题知识资料全集获取与加入专知人工智能服务群: 欢迎微信扫一扫加入专知人工智能知识星球群,获取最新AI算法各种资料、专业知识教程视频资料和与专家交流咨询!

请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请加专知小助手微信(扫一扫如下二维码添加),加入专知主题群(请备注主题类型:AI、NLP、CV、 KG等)交流~

请关注专知公众号,获取人工智能的专业知识!
点击“阅读原文”,使用专知
展开全文



