【论文推荐】最新六篇知识图谱相关论文—全局关系嵌入、时序关系提取、对抗学习、远距离关系、时序知识图谱
【导读】专知内容组整理了最近六篇知识图谱(Knowledge Graph)相关文章,为大家进行介绍,欢迎查看!
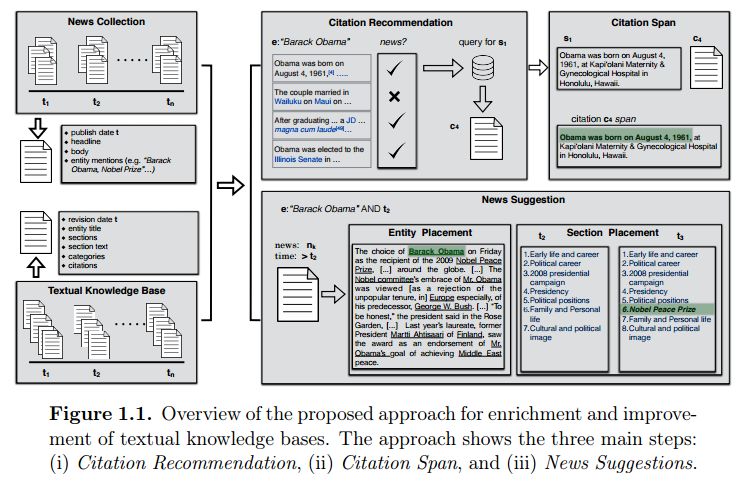
1. Approaches for Enriching and Improving Textual Knowledge Bases(丰富和改进文本知识库的方法)
作者:Besnik Fetahu
机构:der Gottfried Wilhelm Leibniz Universität Hannover
摘要:Verifiability is one of the core editing principles in Wikipedia, where editors are encouraged to provide citations for the added statements. Statements can be any arbitrary piece of text, ranging from a sentence up to a paragraph. However, in many cases, citations are either outdated, missing, or link to non-existing references (e.g. dead URL, moved content etc.). In total, 20\% of the cases such citations refer to news articles and represent the second most cited source. Even in cases where citations are provided, there are no explicit indicators for the span of a citation for a given piece of text. In addition to issues related with the verifiability principle, many Wikipedia entity pages are incomplete, with relevant information that is already available in online news sources missing. Even for the already existing citations, there is often a delay between the news publication time and the reference time. In this thesis, we address the aforementioned issues and propose automated approaches that enforce the verifiability principle in Wikipedia, and suggest relevant and missing news references for further enriching Wikipedia entity pages.
期刊:arXiv, 2018年4月20日
网址:
http://www.zhuanzhi.ai/document/d414a76c4b97a6c3c04e89e5c79cf28e
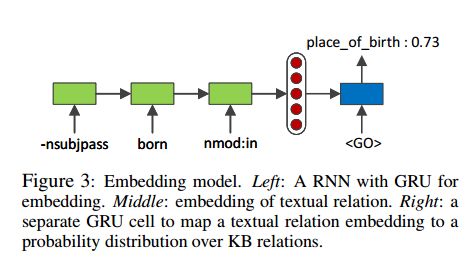
2. Global Relation Embedding for Relation Extraction(关系提取的全局关系嵌入)
作者:Yu Su,Honglei Liu,Semih Yavuz,Izzeddin Gur,Huan Sun,Xifeng Yan
机构:University of California
摘要:We study the problem of textual relation embedding with distant supervision. To combat the wrong labeling problem of distant supervision, we propose to embed textual relations with global statistics of relations, i.e., the co-occurrence statistics of textual and knowledge base relations collected from the entire corpus. This approach turns out to be more robust to the training noise introduced by distant supervision. On a popular relation extraction dataset, we show that the learned textual relation embedding can be used to augment existing relation extraction models and significantly improve their performance. Most remarkably, for the top 1,000 relational facts discovered by the best existing model, the precision can be improved from 83.9% to 89.3%.
期刊:arXiv, 2018年4月19日
网址:
http://www.zhuanzhi.ai/document/f18e8240ce087b972a8c9f67059d6826
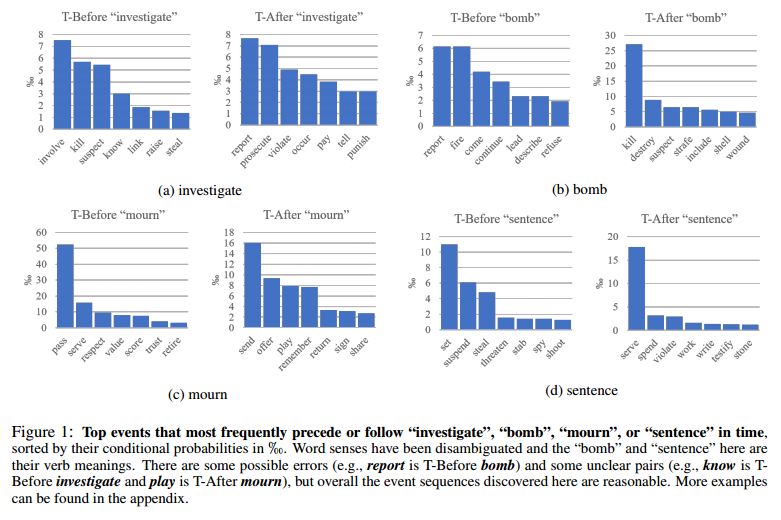
3.Improving Temporal Relation Extraction with a Globally Acquired Statistical Resource(利用全局获得的统计资源改善时序关系提取)
作者:Qiang Ning,Hao Wu,Haoruo Peng,Dan Roth
机构:University of Illinois at Urbana-Champaign
摘要:Extracting temporal relations (before, after, overlapping, etc.) is a key aspect of understanding events described in natural language. We argue that this task would gain from the availability of a resource that provides prior knowledge in the form of the temporal order that events usually follow. This paper develops such a resource -- a probabilistic knowledge base acquired in the news domain -- by extracting temporal relations between events from the New York Times (NYT) articles over a 20-year span (1987--2007). We show that existing temporal extraction systems can be improved via this resource. As a byproduct, we also show that interesting statistics can be retrieved from this resource, which can potentially benefit other time-aware tasks. The proposed system and resource are both publicly available.
期刊:arXiv, 2018年4月17日
网址:
http://www.zhuanzhi.ai/document/0f06d52ab1185faaf2f85cfdc70f1c76
4.KBGAN: Adversarial Learning for Knowledge Graph Embeddings(KBGAN:基于对抗学习的知识图谱嵌入)
作者:Liwei Cai,William Yang Wang
机构:University of Washington
摘要:We introduce KBGAN, an adversarial learning framework to improve the performances of a wide range of existing knowledge graph embedding models. Because knowledge graphs typically only contain positive facts, sampling useful negative training examples is a non-trivial task. Replacing the head or tail entity of a fact with a uniformly randomly selected entity is a conventional method for generating negative facts, but the majority of the generated negative facts can be easily discriminated from positive facts, and will contribute little towards the training. Inspired by generative adversarial networks (GANs), we use one knowledge graph embedding model as a negative sample generator to assist the training of our desired model, which acts as the discriminator in GANs. This framework is independent of the concrete form of generator and discriminator, and therefore can utilize a wide variety of knowledge graph embedding models as its building blocks. In experiments, we adversarially train two translation-based models, TransE and TransD, each with assistance from one of the two probability-based models, DistMult and ComplEx. We evaluate the performances of KBGAN on the link prediction task, using three knowledge base completion datasets: FB15k-237, WN18 and WN18RR. Experimental results show that adversarial training substantially improves the performances of target embedding models under various settings.
期刊:arXiv, 2018年4月16日
网址:
http://www.zhuanzhi.ai/document/29c85bf5138945822db0c2ed07173bde
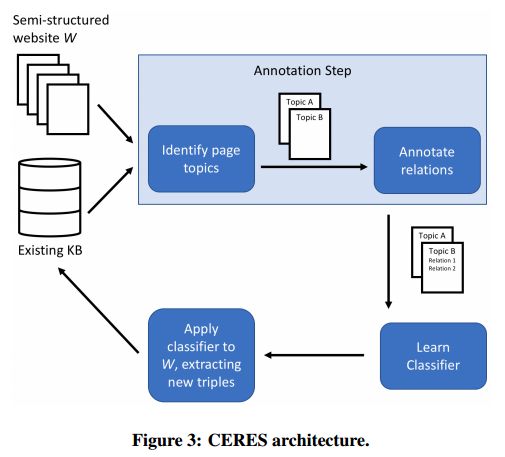
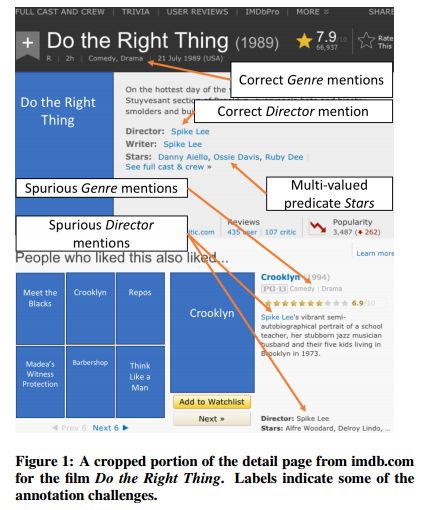
5.CERES: Distantly Supervised Relation Extraction from the Semi-Structured Web(CERES:从半结构化的网络中提取远距离关系)
作者:Colin Lockard,Xin Luna Dong,Arash Einolghozati,Prashant Shiralkar
机构:University of Washington
摘要:The web contains countless semi-structured websites, which can be a rich source of information for populating knowledge bases. Existing methods for extracting relations from the DOM trees of semi-structured webpages can achieve high precision and recall only when manual annotations for each website are available. Although there have been efforts to learn extractors from automatically-generated labels, these methods are not sufficiently robust to succeed in settings with complex schemas and information-rich websites. In this paper we present a new method for automatic extraction from semi-structured websites based on distant supervision. We automatically generate training labels by aligning an existing knowledge base with a web page and leveraging the unique structural characteristics of semi-structured websites. We then train a classifier based on the potentially noisy and incomplete labels to predict new relation instances. Our method can compete with annotation-based techniques in the literature in terms of extraction quality. A large-scale experiment on over 400,000 pages from dozens of multi-lingual long-tail websites harvested 1.25 million facts at a precision of 90%.
期刊:arXiv, 2018年4月13日
网址:
http://www.zhuanzhi.ai/document/d0062d1b0b884311f9141d9db22bb1c3
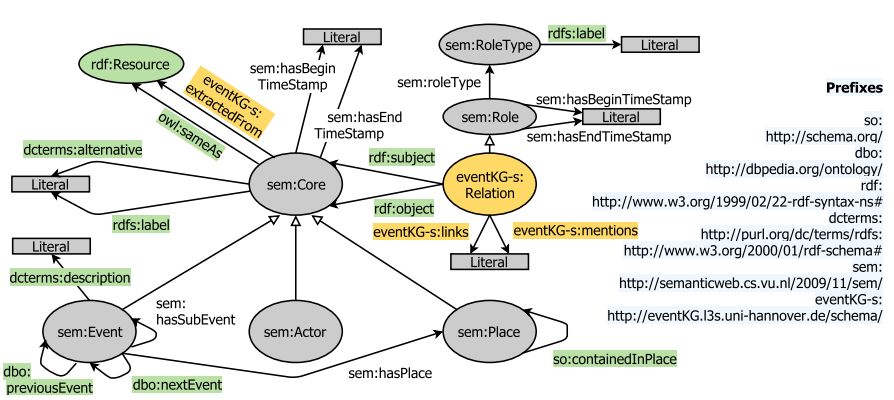
6.EventKG: A Multilingual Event-Centric Temporal Knowledge Graph(EventKG:一个多语言以事件为中心的时序知识图谱)
作者:Simon Gottschalk,Elena Demidova
机构:Leibniz Universit¨at Hannover
摘要:One of the key requirements to facilitate semantic analytics of information regarding contemporary and historical events on the Web, in the news and in social media is the availability of reference knowledge repositories containing comprehensive representations of events and temporal relations. Existing knowledge graphs, with popular examples including DBpedia, YAGO and Wikidata, focus mostly on entity-centric information and are insufficient in terms of their coverage and completeness with respect to events and temporal relations. EventKG presented in this paper is a multilingual event-centric temporal knowledge graph that addresses this gap. EventKG incorporates over 690 thousand contemporary and historical events and over 2.3 million temporal relations extracted from several large-scale knowledge graphs and semi-structured sources and makes them available through a canonical representation.
期刊:arXiv, 2018年4月12日
网址:
http://www.zhuanzhi.ai/document/04a517ce46aeaca5970203a50e07d926
-END-
专 · 知
人工智能领域主题知识资料查看获取:【专知荟萃】人工智能领域26个主题知识资料全集(入门/进阶/论文/综述/视频/专家等)
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

请加专知小助手微信(Rancho_Fang),加入专知主题人工智能群交流!加入专知主题群(请备注主题类型:AI、NLP、CV、 KG等)交流~
投稿&广告&商务合作:fangquanyi@gmail.com
点击“阅读原文”,使用专知
展开全文



