【前沿】R-FCN每秒30帧实时检测3000类物体,马里兰大学Larry Davis组最新目标检测工作
点击上方“专知”关注获取专业AI知识!

【导读】美国马里兰大学、复旦大学和Gobasco人工智能实验室联合提出R-FCN-3000实时3000类目标检测框架,对R-FCN框架中的物体检测和分类进行解耦。本文对R-FCN体系结构进行修改,其中位置敏感滤波器在不同的目标类之间共享来进行定位。对于细粒度的分类,这些位置敏感的滤波器是不需要的。因此,R-FCN-3000学习到了通用的物体性,也达到了更快的速度。R-FCN-3000在ImageNet检测数据集上获得34.9%的mAP,在每秒处理30帧图像的同时,可以以18%的优势超过YOLO-9000。作者相信,未来R-FCN-3000可以适用于更为广阔的目标检测场景(如十万类目标检测),并可以更好的整合目标类别先验。代码将会公开。
▌作者
Bharat Singh 马里兰大学计算机系博士生,主要研究方向为目标及动作识别
http://www.cs.umd.edu/~bharat/
Hengduo Li 复旦大学在读本科生
https://www.linkedin.com/in/hengduo-li-50588032/
Abhishek Sharma 印度德里农业供应链科技初创公司Gobasco联合创始人
https://www.linkedin.com/in/abhishek-sharma-a1204921/
Larry S. Davis 马里兰大学教授
http://www.umiacs.umd.edu/~lsd/
论文:R-FCN-3000 at 30fps: Decoupling Detection and Classification

▌摘要
我们提出了R-FCN-3000,一个大规模的实时目标检测器,其中的目标检测和分类是解耦的。为了获得RoI的检测分数,我们将物体性分数(objectnessscore)乘以细粒度的类别分数。我们的方法是对R-FCN体系结构进行修改,其中位置敏感滤波器在不同的目标类之间共享来进行定位。对于细粒度的分类,这些位置敏感的滤波器是不需要的。R-FCN-3000在ImageNet检测数据集上获得34.9%的mAP,在每秒处理30帧图像的同时,超过YOLO-9000 18%。我们还表明,R-FCN-3000学习的物体性可以被推广到新的类中,并且性能随着训练目标类的数量增加而增加。这个结论证明了我们可以学习通用目标检测器。本文将随后提供代码。
▌详细内容
随着深度CNNs的出现,目标检测在基准数据集上的性能取得了重大飞跃。这归功于CNN结构的强大的学习能力。在过去的五年中,PASCAL和COCO 的mAP得分分别从33%提高到88%和从37%提高到73%(在重叠率50%的评价标准上)。虽然在有数十个类别的基准数据库上有了很大的改进,但是对于需要实时检测数千个类别的现实生活中的目标检测进展甚微。最近的一些努力已经构建了了大规模的检测系统,但是以牺牲准确度为代价。
这篇文章提出了一个新颖的解决方案,能够在比YOLO-9000提高18%的精度来完成大规模目标检测问题,每秒可以处理30帧图像,同时检测3000个类别,被称为R-FCN-3000。
R-FCN-3000是对最近的一些目标检测体系结构[文章中文献6,5,23,25,29]进行修改以实现实时大规模目标检测的任务。最近提出的全卷积(fullyconvolutional)分类检测器计算给定图像中目标的每类分数。其在有限的计算预算中显示出惊人的准确性。虽然全卷积方式为诸如目标检测[6],实例分割[22],跟踪[10],关系检测[41]等任务提供了一个有效的解决方案,但他们需要为每个类设置类特定的过滤器,以禁止他们应用于其他的类。例如,R-FCN [5] / Deformable-R-FCN [6]要求每个类别有49/197个位置特定的滤波器。Retina-Net [23]对于每个卷积特征映射,每个类需要9个滤波器。
因此,这样的结构将需要数十万个用于检测3000个类的过滤器,这将使得它们在实际应用中速度非常慢。
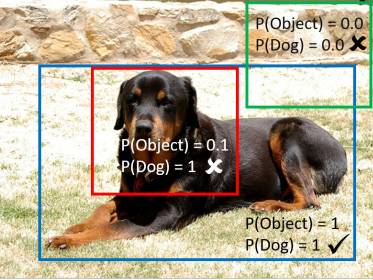
图1:这篇文章建议通过独立地预测物体性和类别得分来解耦分类和定位两个过程。这些分数相乘得到一个检测器。
这篇文章提出的R-FCN-3000结构背后的重要启发是解耦物体性检测和对被检测物体的分类,使得即使随着类别数量的增加,对于定位的计算需求保持不变-参见图1。这篇文章利用这样的事实,即许多目标类别在视觉上相似并共享部件。例如,不同品种的狗都有共同的身体部位;因此,学习一套不同的滤波器来检测每个种类是矫枉过正的。因此,R-FCN-3000为固定数量的超类执行目标检测(使用位置敏感滤波器),然后在每个超类内进行细粒度分类(不使用位置敏感滤波器)。
通过对图像的深层语义特征进行聚类(在这种情况下是ResNet-101的2048维特征)获得超类。因此,这篇文章不需要语义层次的结构。通过将超类概率与超类内的细粒度类别的分类概率相乘,获得给定位置处的细粒度类别的概率。
为了研究使用超类而不是单个目标类别的效果,这篇文章将超类的数量从1改变到100,并评估ImageNet检测数据集的性能。令人惊讶的是,即使有一个超类,检测器也表现的很好!这一结果表明,位置敏感滤波器可以学习检测通用的物体性。它也重新验证了过去很好的研究概念[1,2,39]:目标是一个通用的概念,可以学习一个通用的目标检测器。因此,为了执行目标检测,将RoI的物体性分数乘以给定类别的分类概率就足够了。
该结果可用于数千个类别的快速检测器,因为不再需要每个类别的位置敏感滤波器。在PASCAL-VOC数据集中,只用本文提出的基于物体性的检测器,作者观察到,与可变形的R-FCN [6]检测器相比,所有20个目标类别的类别特定滤波器(class-specific filters)的mAP下降了1.5%。R-FCN-3000训练了3000个类,与ImageNet数据集上当前最先进的大型目标检测器(YOLO-9000)相比,获得了18%的mAP提升。
最后,这篇文章在看不见的类(zero-shot 设定)上评估提出的目标检测器的普适性,并观察到当在更大数量的类上训练物体检测器时,泛化误差减小。
▌模型简介
(1)框架
如图2所示,R-FCN-3000使用RPN产生proposals。对于每个超类k有P*P个位置敏感的滤波器。在进行位置敏感的RoIpooling和对预测进行平均之后,本文可以得到网络对于分类和定位的得分。
为了得到超类概率,网络在K个超类上进行softmax。为了得到细粒度的类别概率,作者增加了两个卷积层,再使用softmax。
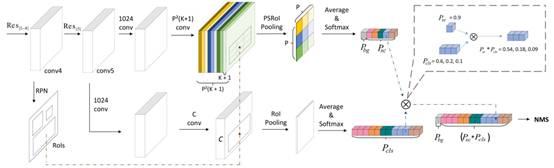
图2:R-FCN-3000首先生成region proposals,这些region proposals作为输入提供给超类检测分支(如R-FCN),其,整体的预测每个超类(sc)的检测分数。另外,本文使用类无关的边界框回归步骤来改进每个RoI的位置(这个步骤在图中没有显示)。为了获得语义类别,本文不使用位置敏感滤波器,而是以全卷积的方式预测每个类的分数。最后,作者将RoI中的每个类别分数进行averagepooling,得到分类概率。分类概率乘以超类检测概率来检测3000个类别。当K是1时,超级检测器来预测物体性。
(2)目标函数
为了训练检测器,作者使用在线难样本挖掘(OHEM),并使用smooth L1 loss来进行检测框定位。
对于细粒度的分类,作者只在C个目标类中使用softmax loss来进行正样本分类。由于相比于proposal的数量,positive ROI的数量非常少,因此作者对这个分支的loss进行了一个因子为0.05的加权,以保证这些梯度不会制约整个网络训练。这种设置是重要的,因为这篇文章中的训练中使用了多任务损失。
▌实验结果
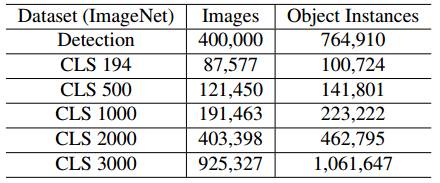
表1:ImageNet中图像的数量和对象实例的数量和以及ImageNet分类(CLS)训练集的不同版本。

表2:作者在有bounding-box监督信息的分类数据上训练的解耦R-FCN并与弱监督方法进行比较,这些弱监督方法使用知识转移方法利用来自ImageNet检测集上的100个预先训练的检测器的信息。

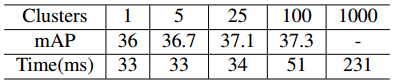
表3:对于1000个类别检测器在不同数量的簇下的mAP分数和每幅图运行时间(毫秒)。

表4:基于1000个类目标的检测器的在NMS中不同数量的超类的mAP和NMS的运行时间(以毫秒为单位)。

图4:针对缩放和转换等各种变换的目标对象,显示了其物体性、分类和最终检测分数。
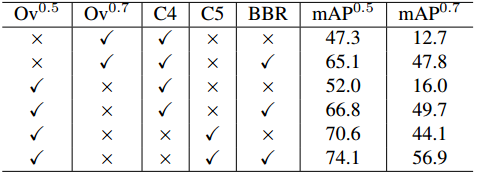
表5:不同版本的RPN进行物体性计算的最终检测分数。
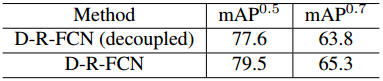
表6:D-R-FCN(ResNet-50)和这篇文章的解耦版本,解耦版本中R-FCN的分类分支只进行物体性预测。

图5:显示ImageNet3K数据集中的类别检测结果,这些类别在通用目标检测数据集中通常不会被发现。

图6:来自ImageNet数据集的包含不可见目标类的图像的物体性分数。
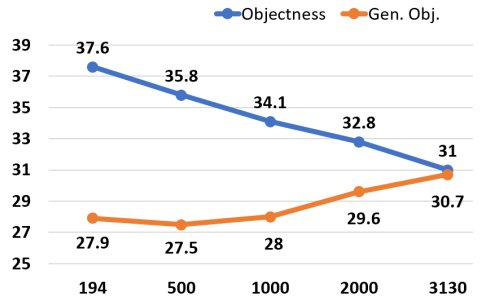
图7:泛化的对象性方法和物体性baseline方法关于一个held out set的20个类别的一组mAP评分结果。
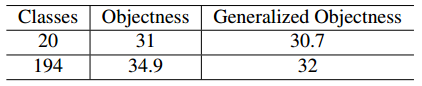
表7:物体性和泛化的物体性关于ImageNet数据集的held out类的mAP。

图8:COCO上的定性结果。由图可知丢失了一些物体,但是该图表明了R-FCN-3000检测到的类别的多样性!
▌结论
这篇文章证明,通过仅使用一组滤波器来进行目标与背景检测,可以预测通用的物体性得分。这种物体性分数可以简单地与检测对象的分类分数相乘,在性能上只有一个较小的下降。最后,作者表明,可将学习到的物体性泛化至未出现的类,并且性能随着训练目标类的数量而增加。它支持物体性具有普遍性的假设。
本文提出了大规模目标检测的重大改进方法,但许多问题仍然没有得到解决。一些有前景的研究问题是:
如何加快R-FCN-3000检测100,000个类别的分类过程?
一个典型的图像包含有限数量的目标类别-如何使用这个先验知识来加速推断?
如果还需要检测对象及其部件,那么在这个架构中需要做什么改变?
由于在每个图像中使用有效的类来标记每个对象是代价很高的,所以如果某些目标没有在数据集中标记出来,可以学习鲁棒的目标检测器吗?
参考文献
https://arxiv.org/abs/1712.01802
▌特别提示-R-FCN-3000 at 30fps: Decoupling Detection and Classification 论文下载:
请关注专知公众号(扫一扫最下面专知二维码,或者点击上方蓝色专知),
后台回复“RFCN3” 就可以获取论文pdf下载链接~
-END-
专 · 知
人工智能领域主题知识资料查看获取:【专知荟萃】人工智能领域25个主题知识资料全集(入门/进阶/论文/综述/视频/专家等)
同时欢迎各位用户进行专知投稿,详情请点击:
【诚邀】专知诚挚邀请各位专业者加入AI创作者计划!了解使用专知!
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

请加专知小助手微信(Rancho_Fang),加入专知主题人工智能群交流!

点击“阅读原文”,使用专知!
展开全文



