春节充电系列:李宏毅2017机器学习课程学习笔记09之Tip for training DNN
【导读】我们在上一节的内容中已经为大家介绍了台大李宏毅老师的机器学习课程的简单实践,这一节将主要针对讨论训练DNN的小技巧。本文内容涉及机器学习中训练DNN的若干主要问题:new activation function, adaptive learning rate, early stopping, regularization, dropout。话不多说,让我们一起学习这些内容吧
春节充电系列:李宏毅2017机器学习课程学习笔记01之简介
春节充电系列:李宏毅2017机器学习课程学习笔记02之Regression
春节充电系列:李宏毅2017机器学习课程学习笔记03之梯度下降
春节充电系列:李宏毅2017机器学习课程学习笔记04分类(Classification)
春节充电系列:李宏毅2017机器学习课程学习笔记05之Logistic 回归
春节充电系列:李宏毅2017机器学习课程学习笔记06之深度学习入门
春节充电系列:李宏毅2017机器学习课程学习笔记07之反向传播(Back Propagation)
春节充电系列:李宏毅2017机器学习课程学习笔记08之“Hello World” of Deep Learning
课件网址:
http://speech.ee.ntu.edu.tw/~tlkagk/courses_ML17_2.html
视频网址:
https://www.bilibili.com/video/av15889450/index_1.html

李宏毅机器学习笔记9 Tip for training DNN
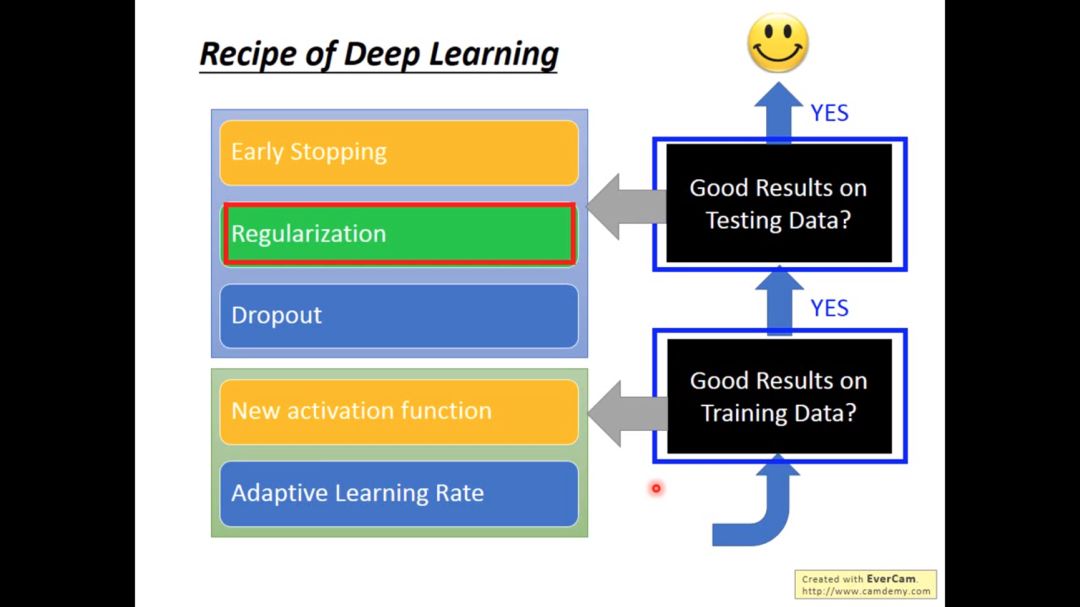
在上一次学习笔记中我们发现在实际写机器学习代码的结果中,极大可能在training data都没有很好的正确率,更不用说在训练集上的结果。
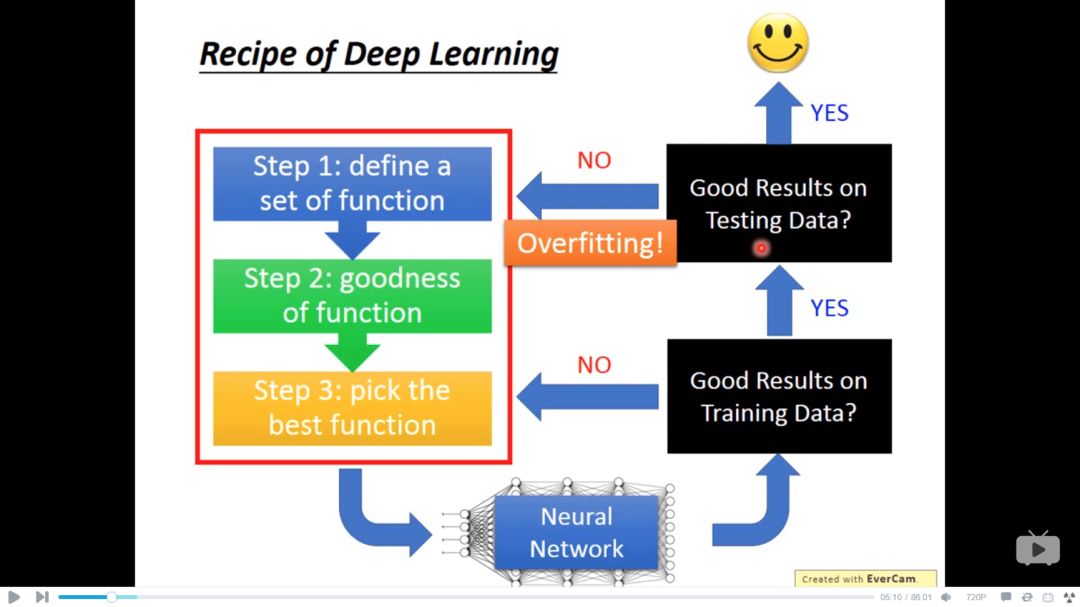
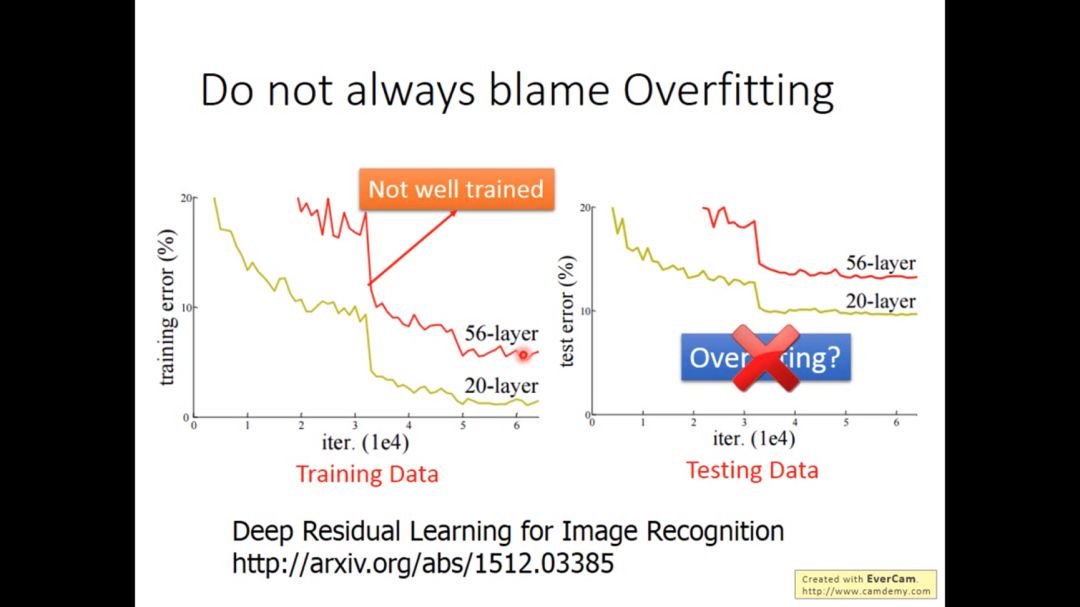
当我们发现训练后的程序在测试集上表现很差,不应该总想着怪罪于overfitting,因为可能本身在training阶段都没train好,从而导致test不好。当解决overfitting问题后,也要再次检查在training data上是否可行。
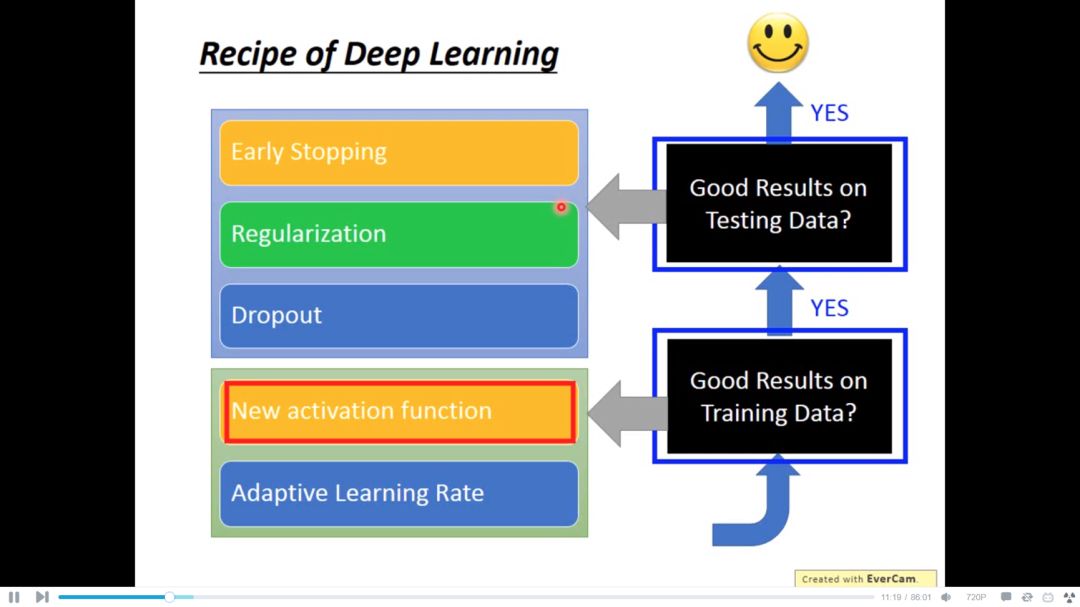
所以对于不同的问题我们应该采取不同的措施
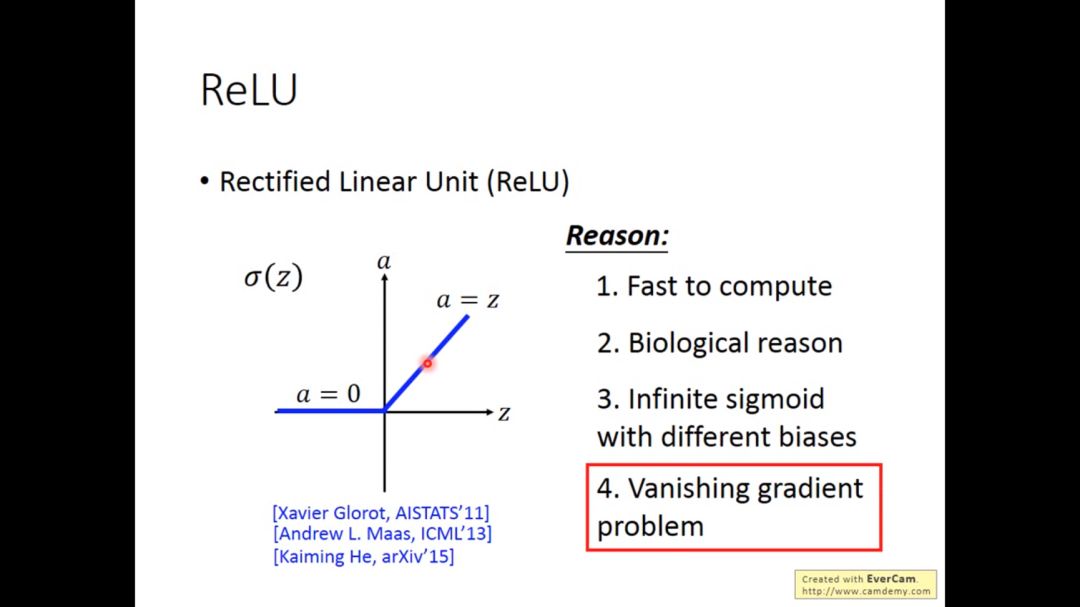
1. new activation function
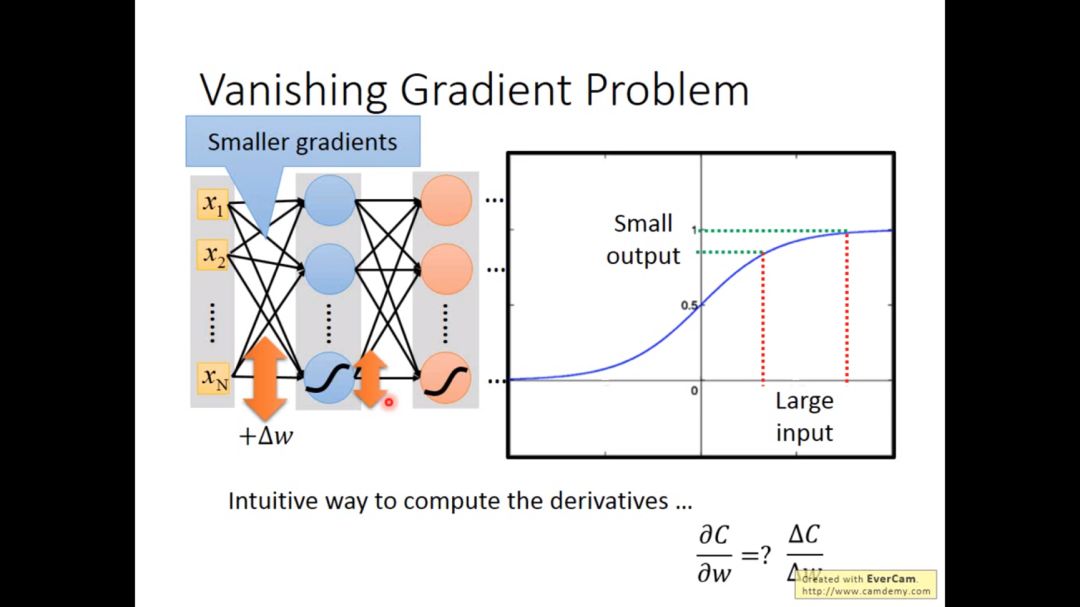
下图的activition function 是sigmoid function, 注意下图不是overfitting,因为在training阶段已经坏掉了.
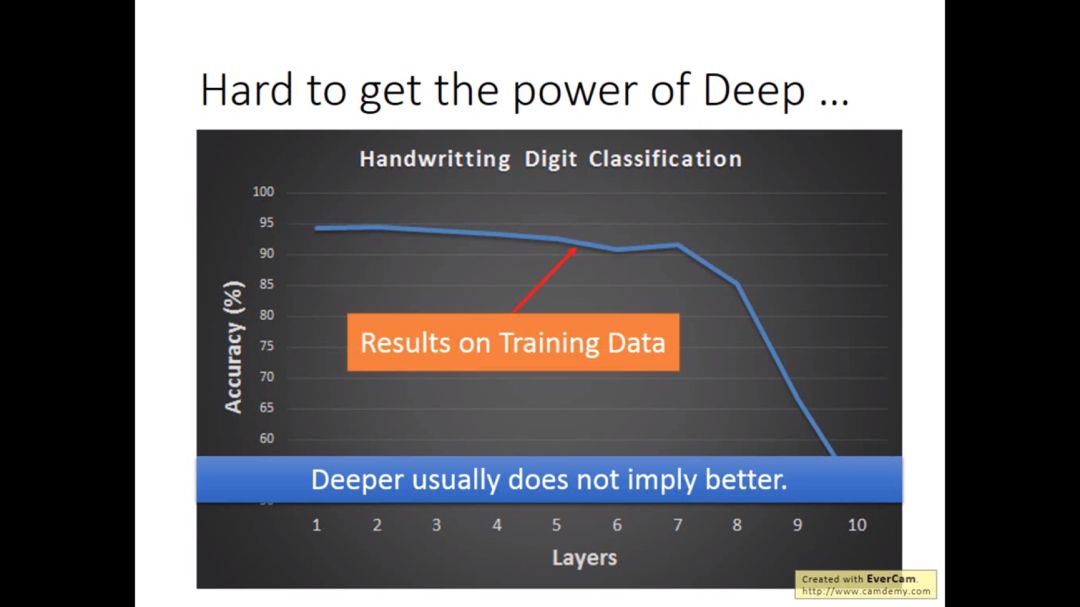
根据反向传播的公式,我们会发现靠近输入端的参数更新非常缓慢,而靠近输出端的参数更新很快,直觉中最开始的w变化,对于输出的影响,Sigmoid函数会使影响越来越小,所以sigmoid函数不是很好。
我们可以用ReLU代替sigmoid函数
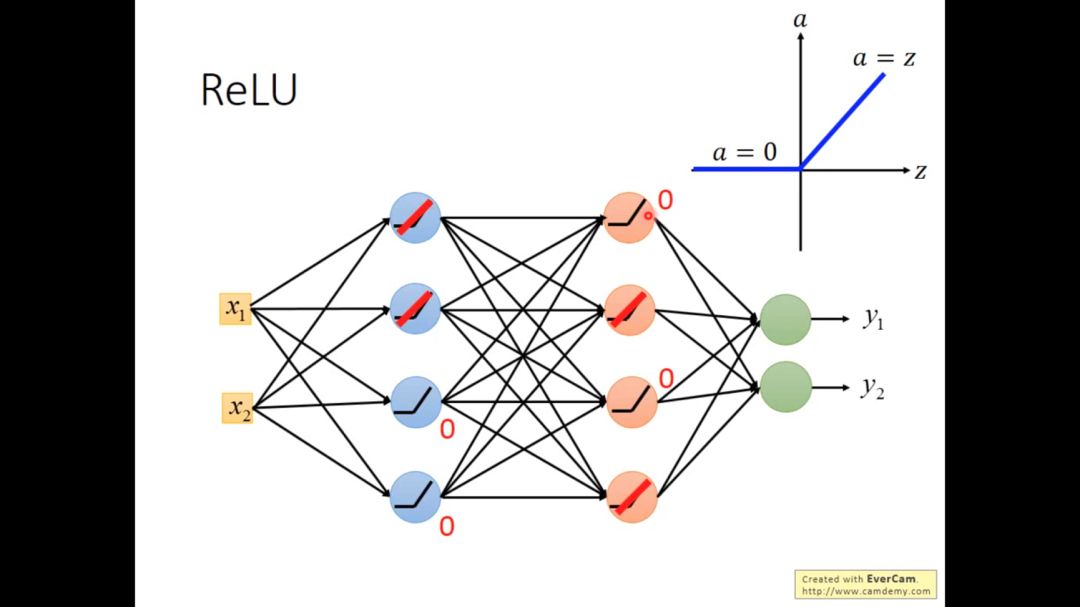
对于ReLU,当输入小于0时,输出为0
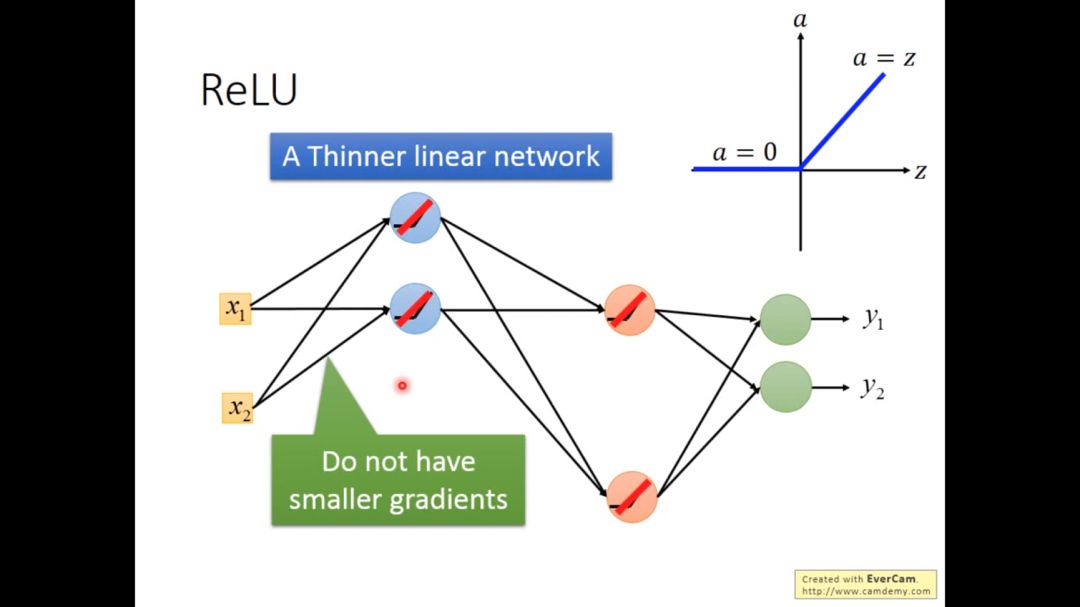
所以整个线性网络会变成细长的线性网络,并且靠近输入层的参数更新并不会有很小的梯度。
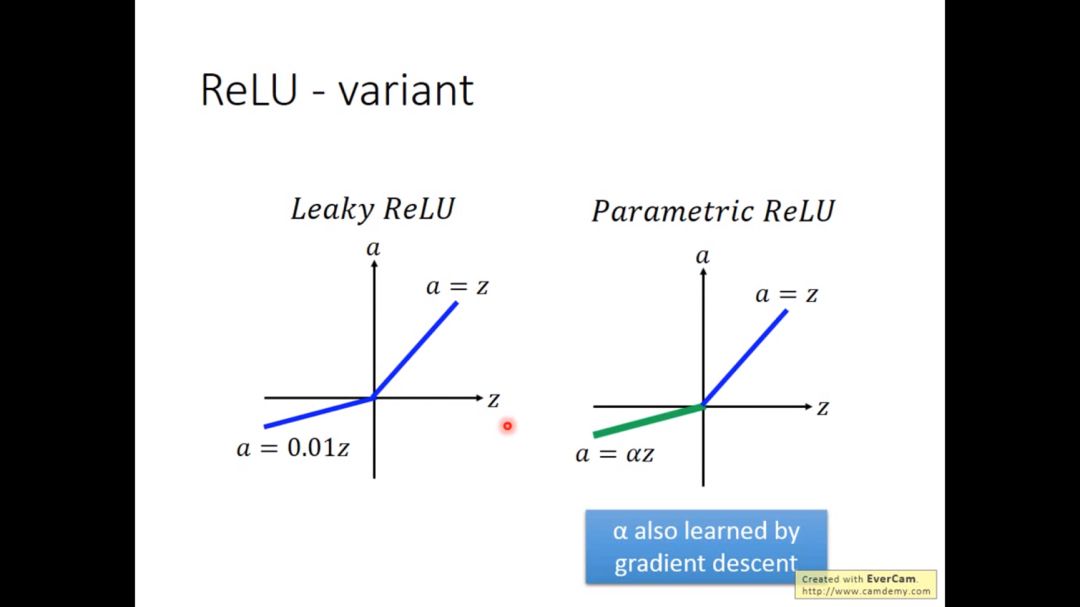
ReLU有一些改进版,leaky ReLU小于0的部分为0.01z,parametricReLU小于0的部分为αZ,其中α可以通过梯度下降学到。
激活函数也可以换成maxout,maxout是在输入的一组元素中选取最大的元素
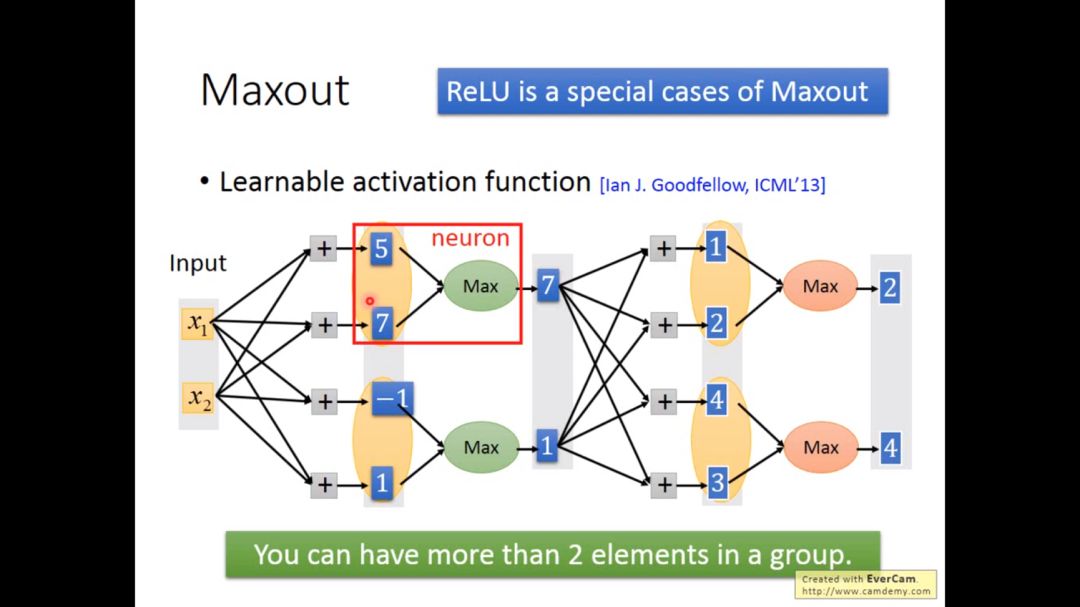
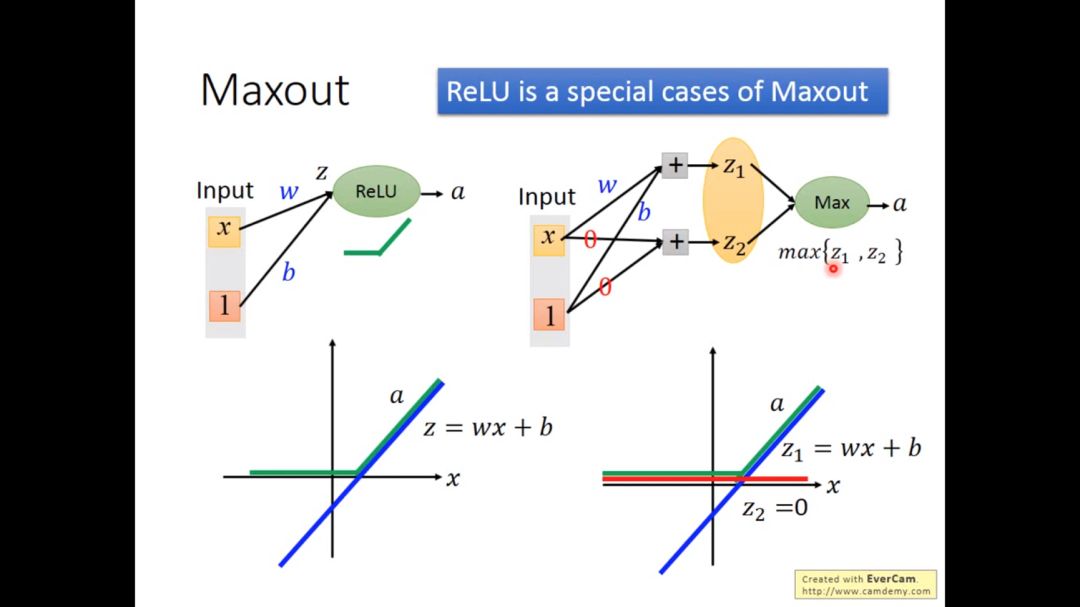
ReLU可以当成Maxout的特殊情况
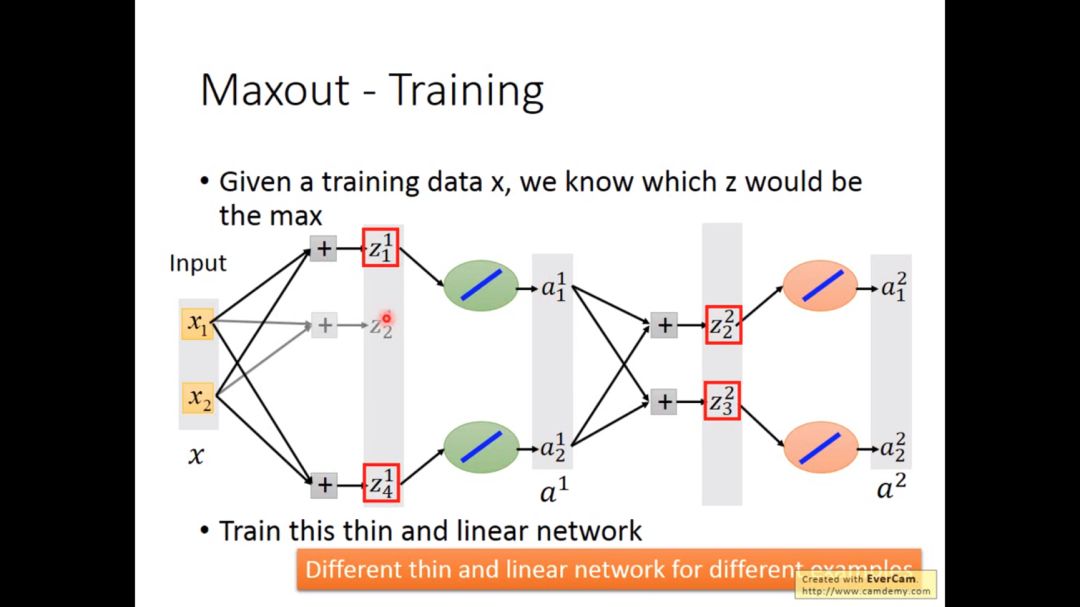
给定一个训练集x,我们就知道网络中那个z是最大的,于是也变成了细长的线性网络
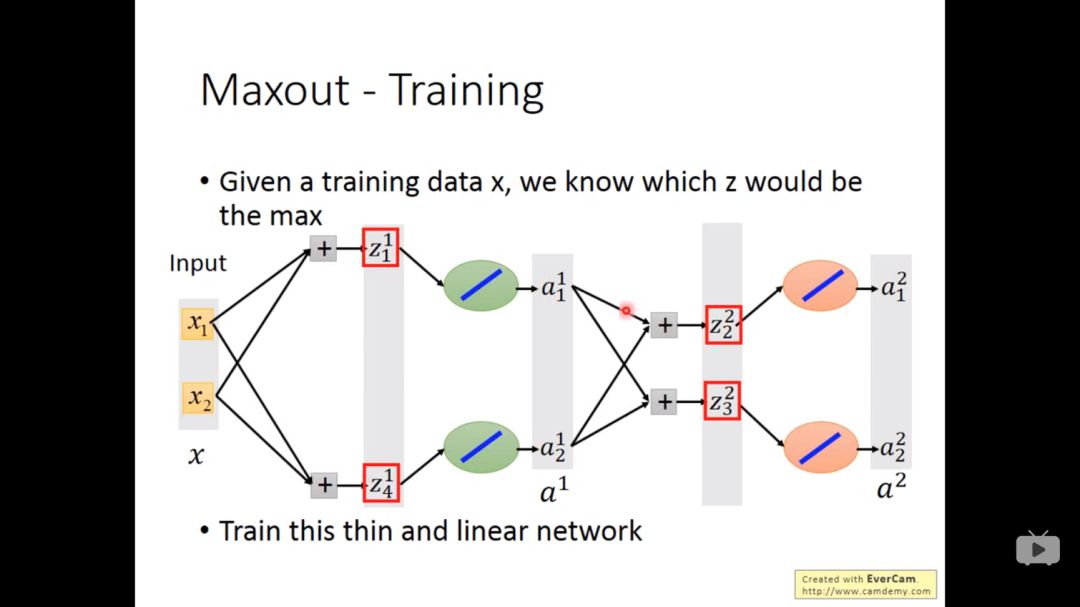
每个不同的input,其网络不一样,所以所有的w都会被train到
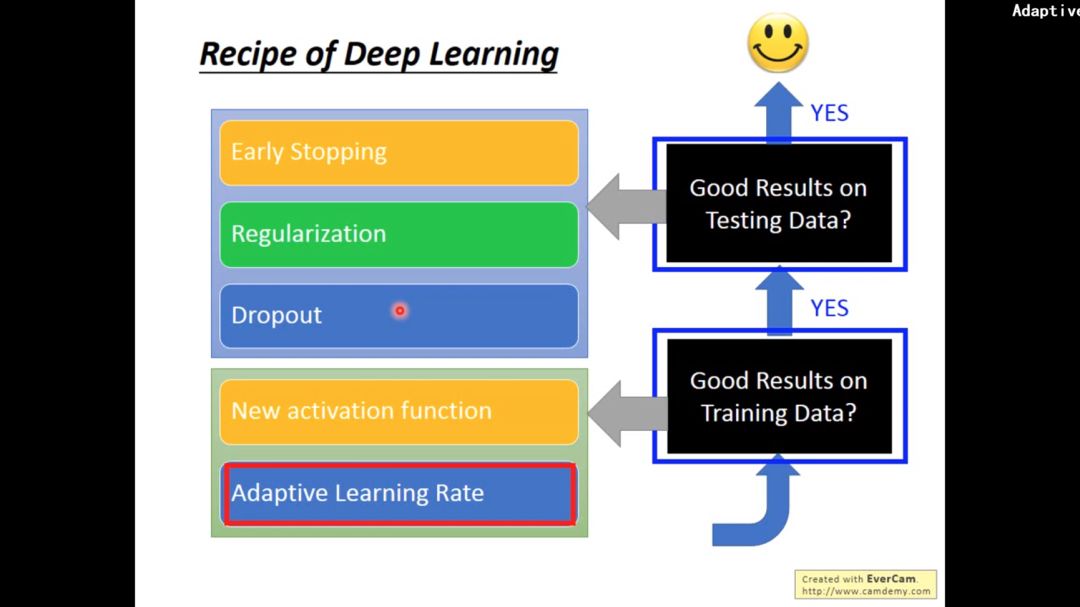
2. adaptive learning rate
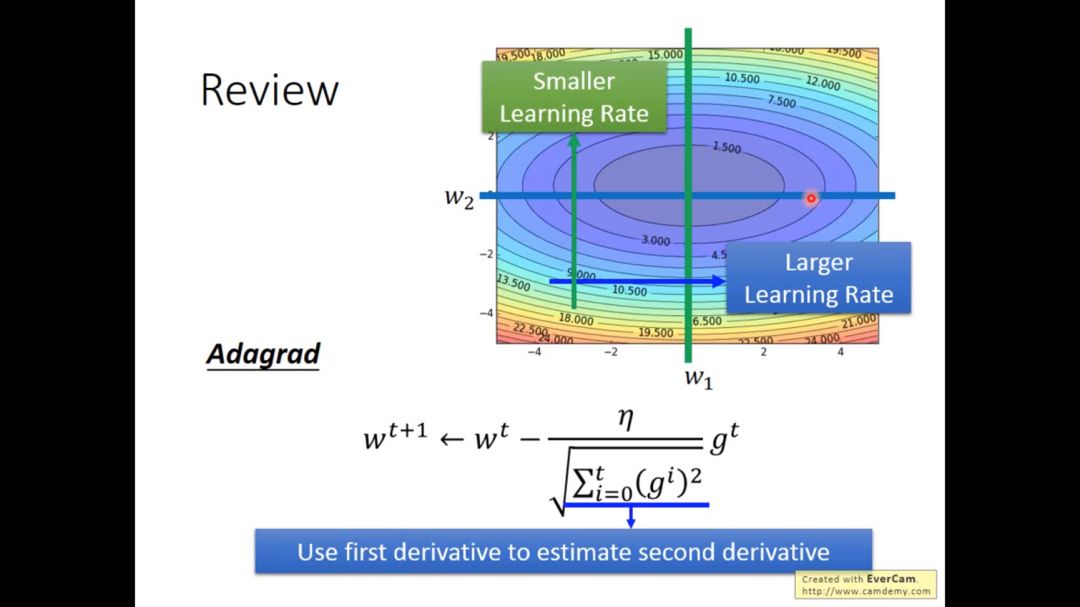
在之前介绍的adagrad算法,其核心思想是用一阶微分来估计二阶微分
现在介绍adagrad进阶版,叫RMSProp

当α比较小时,意思是倾向于相信最新的gradient
在物理学中物体都有惯性,我们可以在梯度下降过程中借鉴惯性的性质
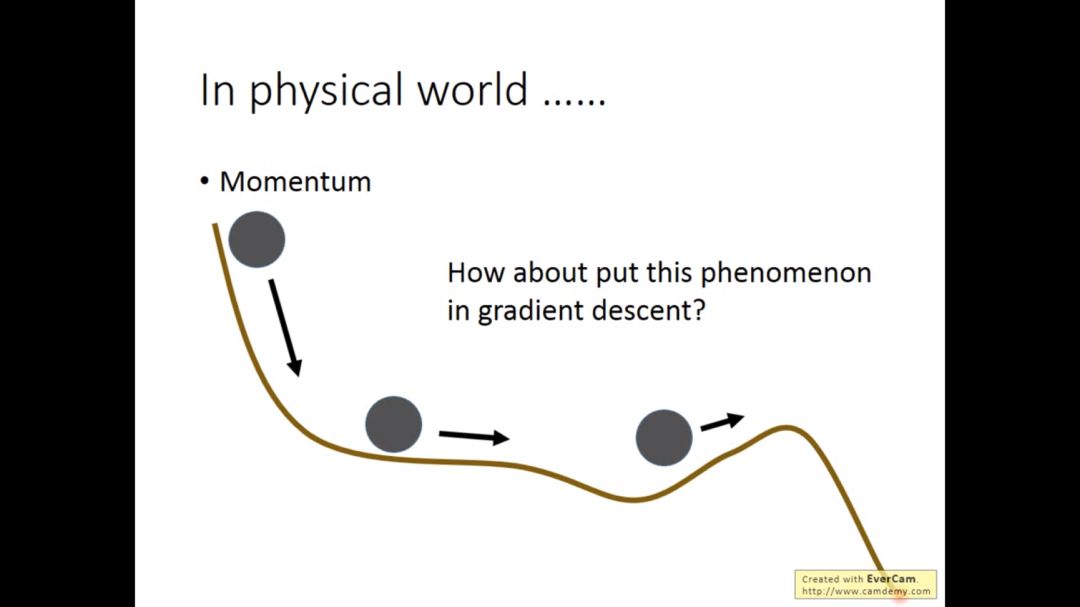
梯度下降时,更新参数不仅仅依赖于算出的梯度值,还依赖于之前更新参数的值
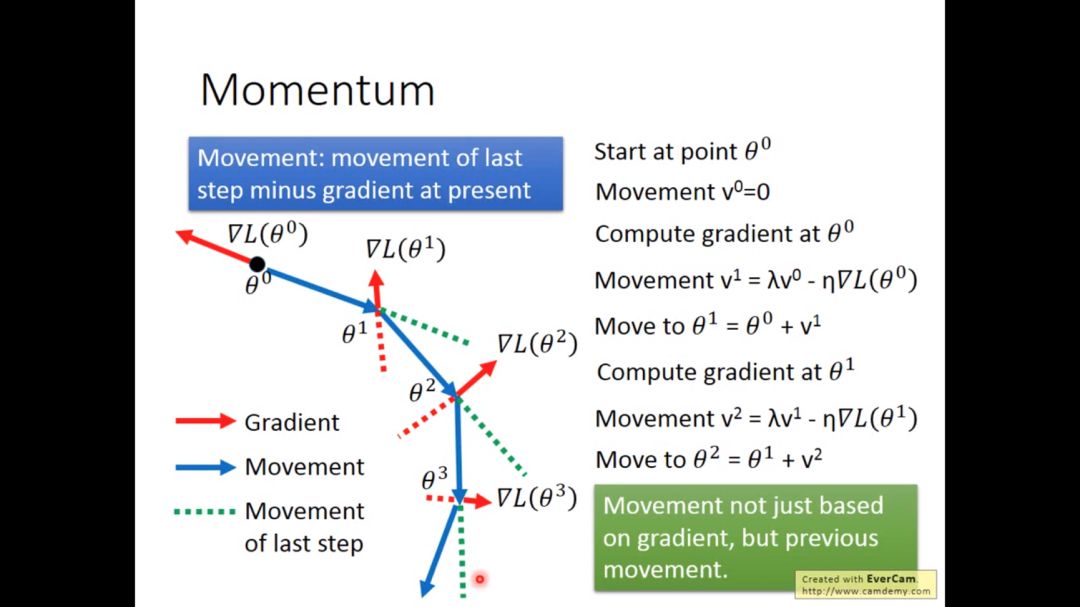
所以这次的移动是上一步的移动减去现在的梯度

这个方法不一定会达到全局最低点,但最起码给了我们点希望
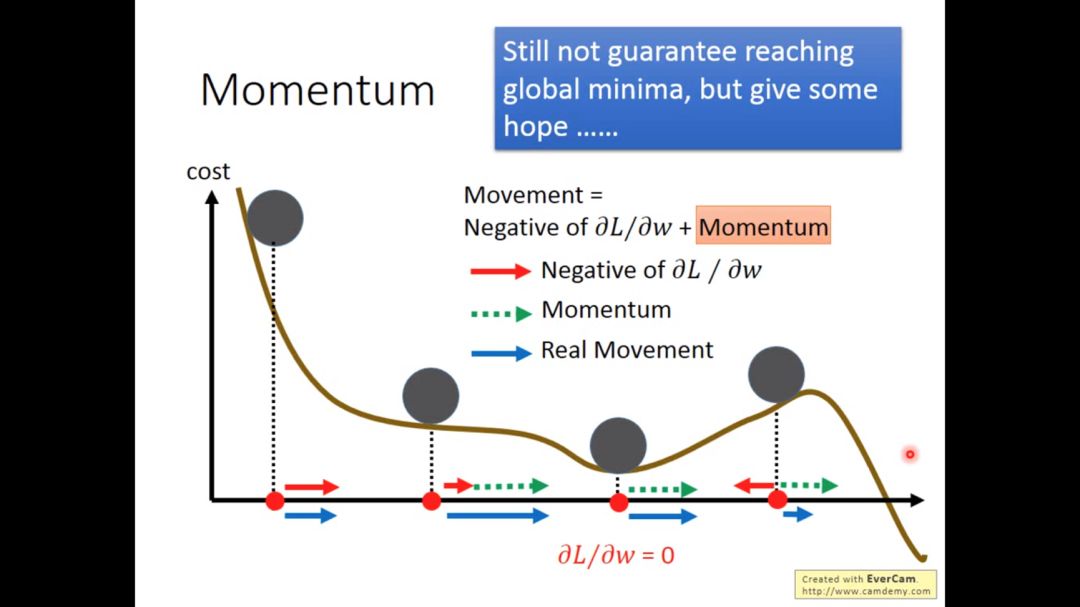
下图为adam的算法,是RMSProp和Momentum的结合版

3. Early stopping
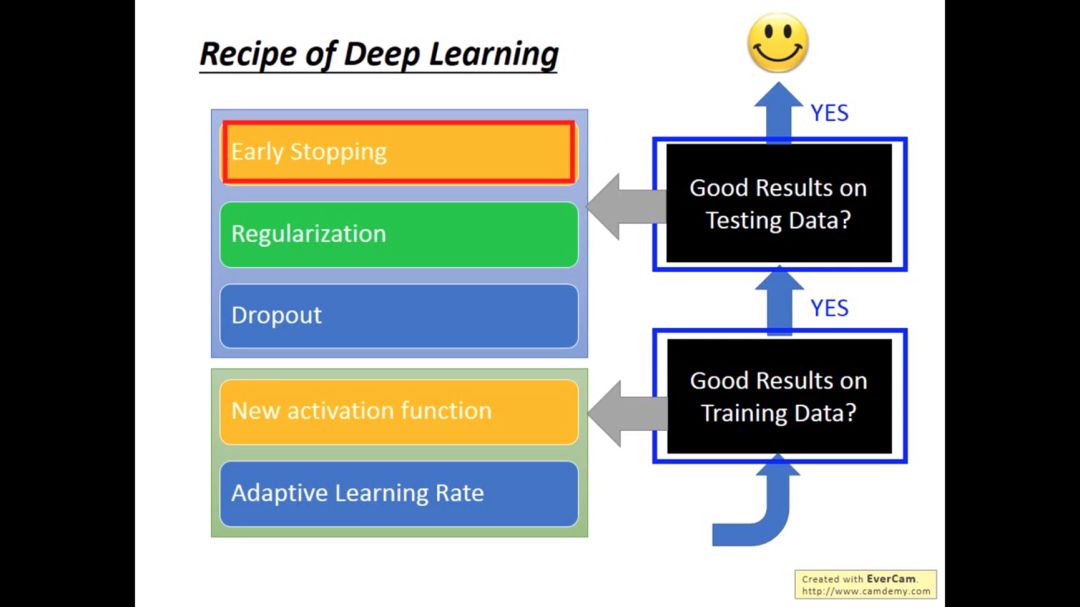
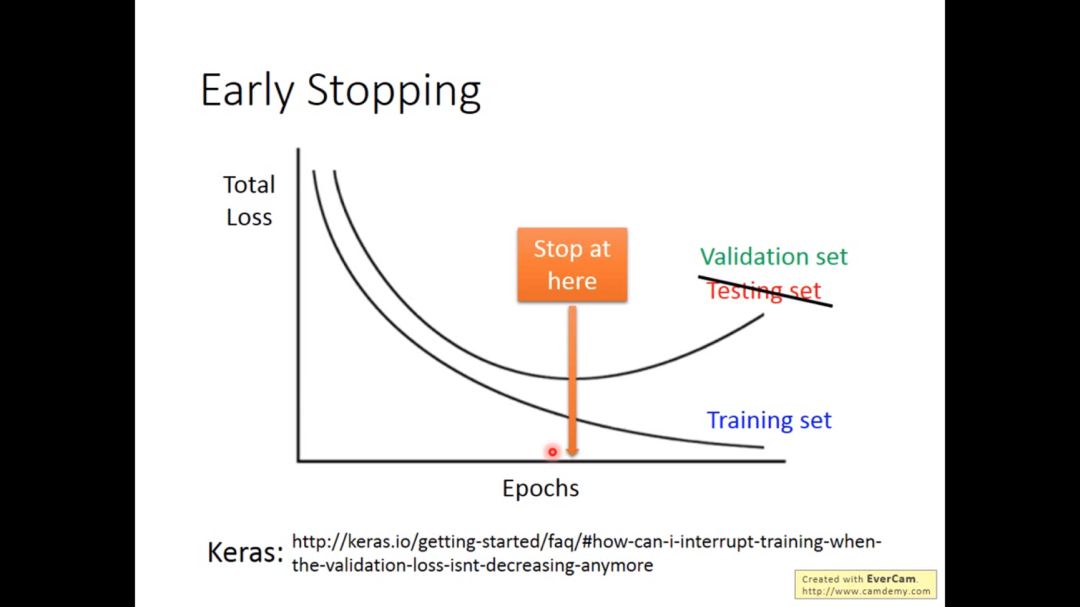
为什么会发生early stopping的现象?
如果learning rate设得对的话,training set的loss会逐渐降低,而testing set与training set可能分布不同,所以testing set的loss可能先降后升,这时就不要一直train下去,而是要在testing loss最小的地方停止train。这里的testing set 实际指的是validation set。
应该train的过程应该停在使得testing loss 最小的地方而不是使得training loss最小的地方
具体做法是不让weight update次数太多
4. Regularization
Regularization目的是为了发现一组参数它们不仅最小化损失函数并且它们的值接近于0

下图最下面左边一项的系数是略小于1的值,使得w越来越趋近于0,但最下面右边一项使得其平衡,总的作用就是weight decay

对于L1 regularization的微分,每次是减去一个固定的值

5. dropout
对于dropout,每个neuron有百分之p的概率去dropout,也就是去除
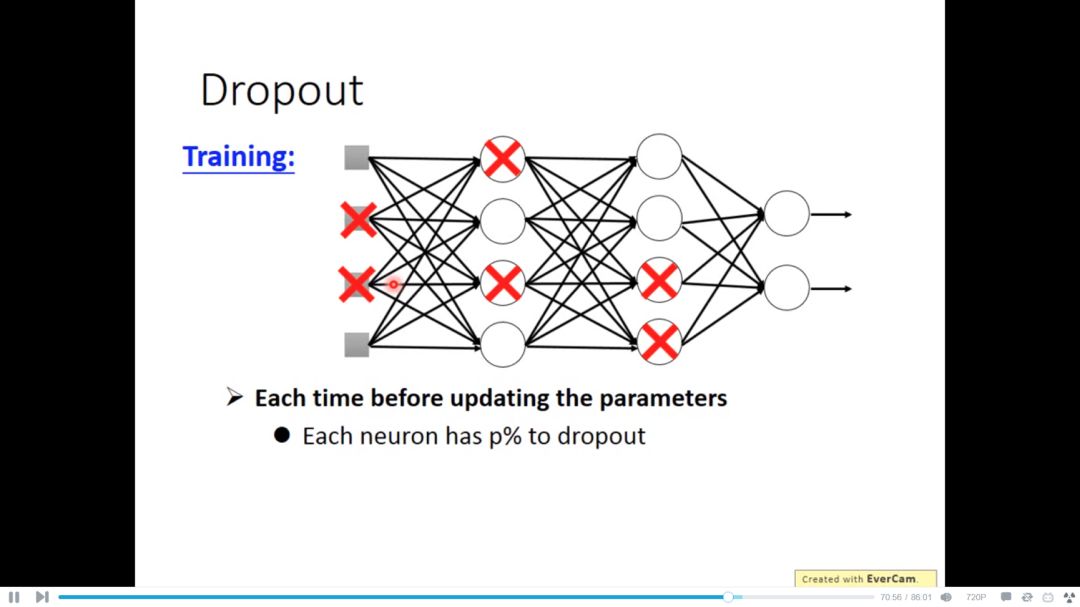
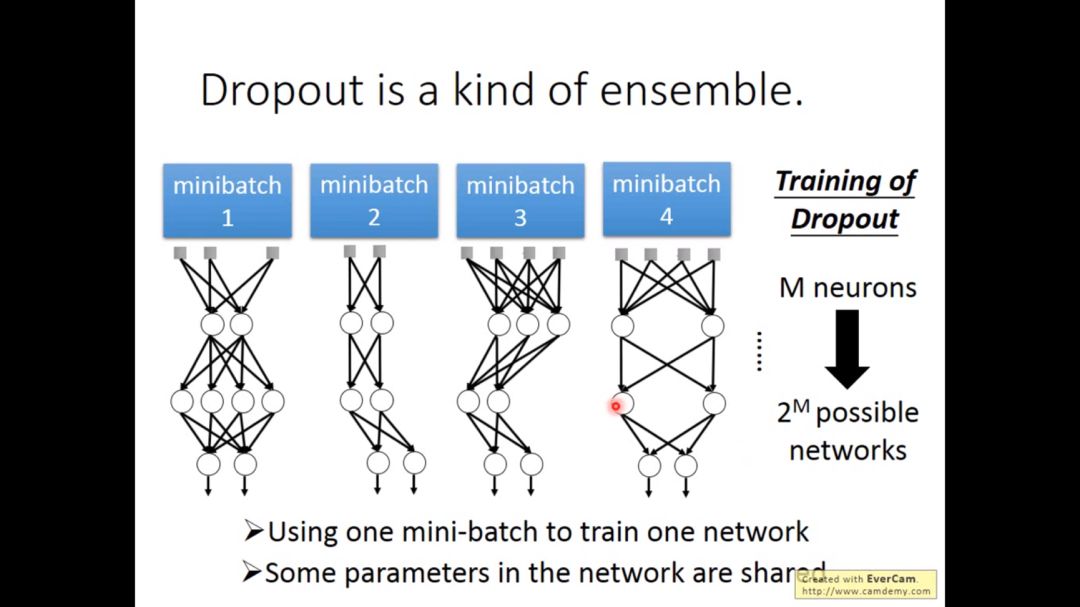
每次updata都要重新sample neurons,所以每次得到的网络是不一样的
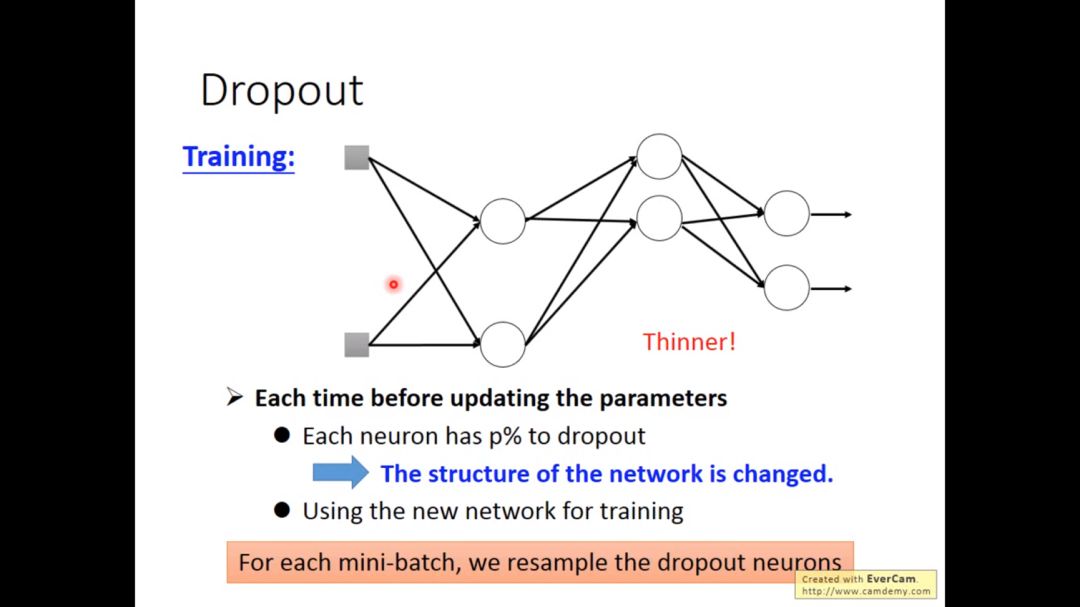
使用dropout,training的performance是会变差的,因为neurons变少,但为了让test的结果变好
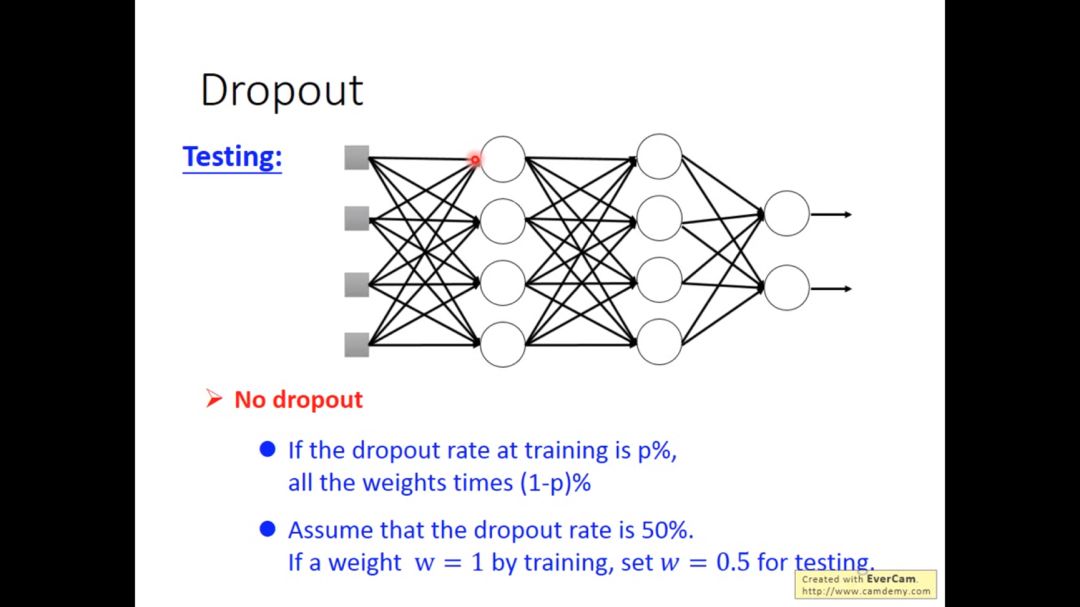
下图是一个很形象的例子

如果我们每次以p%的概率去dropout,最后学习到的权重值需要乘以(1-p)%
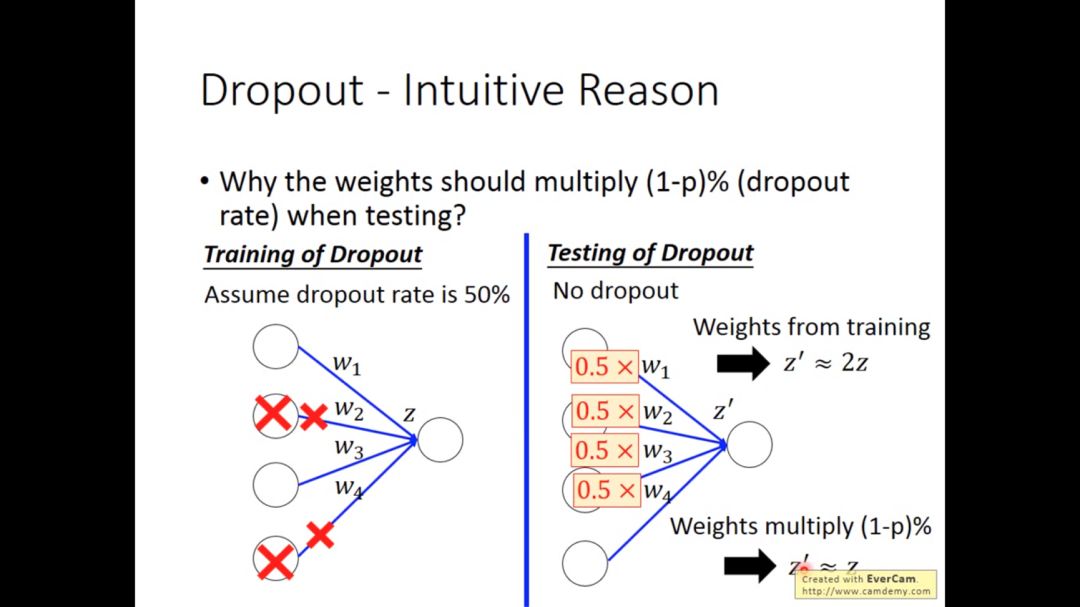
ensemble的含义在于,很大很笨重的model,bias很准,variance很大,当笨重的model有很多个,虽然variance很大,但平均起来就很准
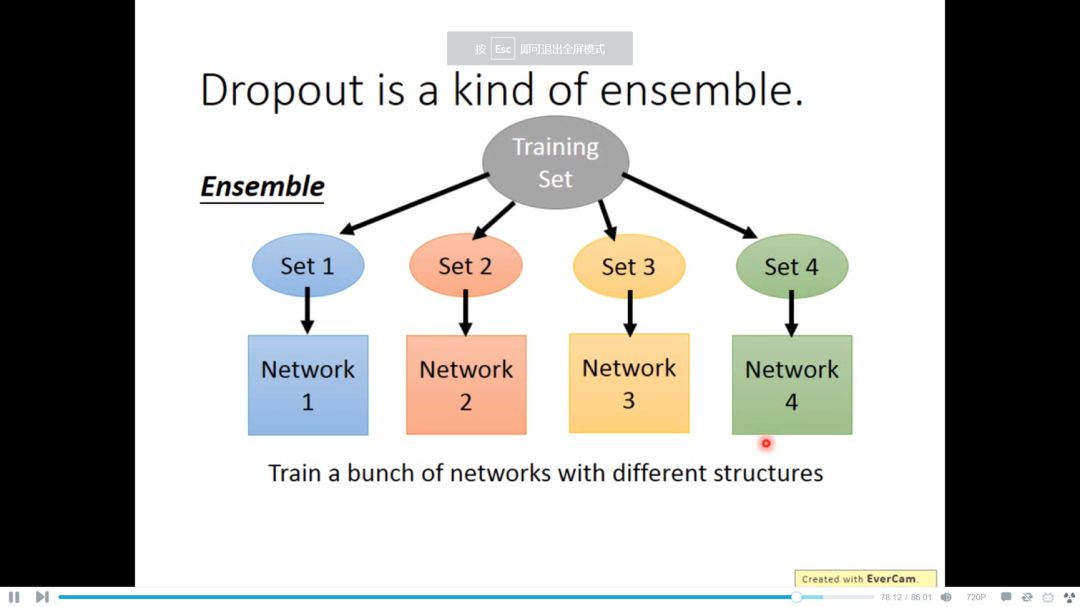
Dropout本质上做的就是ensemble工作
请关注专知公众号(扫一扫最下面专知二维码,或者点击上方蓝色专知),
后台回复“LHY2017” 就可以获取 2017年李宏毅中文机器学习课程下载链接~
-END-
专 · 知
人工智能领域主题知识资料查看获取:【专知荟萃】人工智能领域26个主题知识资料全集(入门/进阶/论文/综述/视频/专家等)
同时欢迎各位用户进行专知投稿,详情请点击:
【诚邀】专知诚挚邀请各位专业者加入AI创作者计划!了解使用专知!
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

请加专知小助手微信(Rancho_Fang),加入专知主题人工智能群交流!
点击“阅读原文”,使用专知!
展开全文



