【深度】为什么Alphago Zero是深度学习领域的一次巨大突破?
点击上方“专知”关注获取更多AI知识!
【导读】Google DeepMind在Nature上发表最新论文,介绍了迄今最强最新的版本AlphaGo Zero,不使用人类先验知识,使用纯强化学习,将价值网络和策略网络整合为一个架构,3天训练后就以100比0击败了上一版本的AlphaGo。 业界如何看待,我们来听听 Carlos E. Perez的观点。
Carlos E. Perez是 Author of the Deep Learning AI Playbook — IntuitionMachine.com

Credit: War Games(1983) http://www.imdb.com/title/tt0086567/
1983年的电影“战争游戏”有一个令人难忘的高潮,一个被称为WOPR的超级计算机(战争行动计划响应)被要求自我训练去完成一个不可能的任务。马修·布罗德里克饰演的角色问道:“有什么方法可以训练自己么?
34年后,DeepMind已经显示了这是如何在现实生活中完成的!实现方法和上边提到的类似,将玩家的数量设置为零(即zerohumans)。
深度学习技术的这一最新突破非常值得关注。DeepMind的作者使用“自我强化学习”一词来命名。 正如我在关于“AI部落”的论文中所说,DeepMind特别喜欢使用他们的增强学习(RL)方法。 DeepMind已经将Deep Learning层与更经典的RL方法结合。
AlphaGo Zero是其Go-playing自动化的最新成果。 人们会认为,在围棋领域想要超过赢得人类世界冠军的AlphaGo版本是很难的。 然而,AlphaGo Zero不仅击败了以前的系统,而且是以一种验证革命性方法的方式来实现。 更具体地说,以下AlphaGo已经能够完成的:
1. 击败以前版本的AlphaGo(最终得分:100-0)。
2. 从头开始学习执行某项任务,而不需要先前的人类知识(即记录的游戏)。
3. 通过短短三天的训练达到世界冠军级别。
4. 数量级小于神经网络(4 TPU对48 TPU)。
以上每个要点都是值得上头条。 这些点结合在一起体现了强大的压倒性进步。 以下是我对这些点的一些理解。
许多人或许认为第一个点似乎没有什么意义。 也许是因为技术的渐进改进一直是一种常态。 也许一个算法战胜另一种算法100次,并不如有一个人战胜另一个人直接100那么有吸引力。 算法不像人类,人类充满变化。
人们会期待围棋游戏具有足够大的搜索空间,这样就有机会运行能力较差的算法,以幸运地击败更好的。 可以说,AlphaGo Zero已经学会了新的外来动作,因此其竞争对手因为无法理解相同的搜索空间而具有了不可克服的缺点。 并且有一点值得注意,AlphaGo Zero需要的计算资源少于他击败的对手。 显然,它的工作量减少了很多,但也可能只是开发出更加丰富的围棋策略。 人们希望做的更少的工作。 语言压缩是减少认知工作的手段。
第二点挑战了我们目前监督的机器学习模式。 原来的AlphaGo是使用以前的游戏记录线性自举。 随后,自我发挥,以改善其两个内部神经网络(即policy
and value networks)。 相比之下,AlphaGo Zero从头开始只用围棋的规则编程。 它只需要一个单一的网络而不是两个网络。 更令人惊讶的是,它能够引导自身,然后最终学习更先进的人类战略以及以前未知的策略。 此外,学习什么策略的先后顺序有时是意想不到的。 就好像系统已经学会了如何玩围棋的新内部语言。 单个网络对抗两个网络也值得思考 也许存在一些不相交的网络无法学习的策略。
人类通过隐喻和故事学习语言。 在围棋中发现的人类战略被称为names,以便由玩家识别。 人类的围棋语言可能是低效的,因为它不能表达更复杂的复合概念。 AlphaGo Zero似乎能够做的是以同时满足多个目标的方式执行其动作。 所以人类,或许早期版本的AlphaGo也被限制在一种相对线性的思维方式,而AlphaGo Zero并没有受到低效的策略语言的阻碍。 同样有趣的是,人们可能认为这个系统实际上不使用可能存在语言中的隐含偏见。 DeepMind的大卫·贝尔(David Silver)有更加大胆的声明:
它比以前的方法更强大,因为通过不以任何使用人工数据或人类经验的方式,我们就已经消除了人类知识的限制,并且能够创造知识本身。
大西洋报道了这个新系统的游戏的一些有趣的观察:
资深玩家也注意到了AlphaGo的特质。 洛克哈特和其他人提到,它几乎同时在各种游戏中表现良好,采取一种可能似乎对人类玩家有点疯狂的方法,他们可能会一次把更多的精力集中在较小的领域。
学习到的语言是它计算的围棋历史中从没出现过的。
第三点表明,训练时间也比以前更令人惊讶。 就像AlphaGo Zero学习如何改进自己的学习。
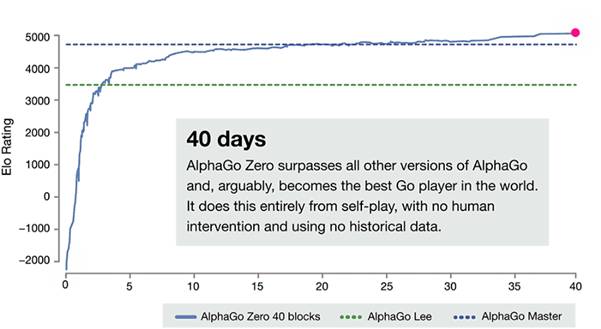
资料来源:https://deepmind.com/blog/alphago-zero-learning-scratch/
AlphaGo Zero只花了3天时间就达到了人类高手的水平。 此外,即使在超越了上一版本AlphaGo的最佳性能后,它的性能还是可以不断变的提高。 它是怎么做到不断地改进学习呢? 这种能够进行增量学习并不断改进神经网络被称为FeedbackNet。在常见的基于SGD的梯度优化学习中,利用相同的数据进行反复的迭代来不断地完善神经网络。
然而,在围棋的世界里,每个训练数据集都是全新的,而且随着训练的深入而变得越来越具有挑战性。这里训练集是由自己产生的,目标函数的计算是从MCTS的结果得出的。网络通过不断地迭代自己而不会利用外部训练数据,这些数据是从网络本身的前一个版本自己生成数据。
关于最后一个问题,文件报告指出,以前的系统在inference时使用了48个TPU,而现在只需要4个Google TPU就够了。更令人惊讶的是,论文指出,它可以运行在单个系统上,而并不需要分布式计算。所以任何人如果有一台包含四个基于Volta的Nvidia GPU的台式机就可以复现这些实验结果。新系统只需要之前1/10的算力深刻的说明了AlphaGo Zero带来的新变革。我还没有详细分析它的原因,也许可以解释成新系统使用了一个更简单的架构吧。
几乎所有最新出版的深度学习论文(或发表在Arxiv上)都习惯在现有架构的基础上做些小的修改。而且为了实现更高的预测精度,新的实现也往往需要更多的硬件资源。但是AlphaGo Zero确是一个另类,他用了一个资源消耗少而且不那么复杂的架构就完成了性能的飞跃。
其实强化学习在很早之前就被应用在了游戏上,这些技术并不是什么新东西,很多在几十年前就被发明出来了。然而这些方法的威力最终却是被DeepMind团队的实验验给充分验证了。 深度学习中,像运动员比赛一样,纸上谈兵永远说明不了问题,你必须在实践中来一较高下。总之,不管想法如何简单,你不做个实验试试,你永远不会知道会得到什么结果。
AlphaGo Zero使用的策略迭代算法或神经网络的架构并不是什么新东西。 策略迭代算法在策略估计和策略改进之间交替进行,来学得新的学习改进改进方法。也就是说,在估计的当前策略的价值函数和当前正在使用价值值函数之间找到更好的策略。
在一个常见的用于行人检测的卷积神经网络中:
在20到40的分块网络中,网络深度从39到79层不等。另外还有2层用于策略判断,3层用于价值判断。
类似于之前的版本,AlphaGo Zero同样采用蒙特卡罗树搜索(MCTS)用于下一步的选择。 AlphaGo Zero利用树形搜索的计算方式来评估和训练神经网络。所以总得来说使用以前训练过的神经网络的MCTS,可以搜索新的获胜动作。策略评估从许多采样轨迹估计值函数。该搜索的结果然后用于驱动神经网络的学习。所以在每场比赛之后,一个新的和潜在的改进的网络被用于下一个自我提高的游戏中。 DeepMind称这种方法为“自我强化学习”:
AlphaGo Zero 的神经网络使用自我对弈数据做训练,这些自我对弈是在一种新的强化学习算法下完成的。在每个位置 s,神经网络 fθ都会进行蒙特卡洛树搜索(MCTS)。MCTS 输出下每步棋的落子概率 π。这样搜索得出的概率通常比神经网络 fθ(s)的原始落子概率 p 要更加强一些;MCTS 也因此可以被视为一个更加强大的策略提升 operator。
系统通过搜索进行自我对弈,也即使用增强的基于 MCTS 的策略选择下哪步棋,然后使用获胜者 z 作为价值样本,这个过程可以被视为一个强有力的策略评估 operator。
随着在游戏中的每一次自我迭代,系统会变得越来越强大。令人震惊的事,利用一些新的搜索机制能够创造性地发现新的策略,同时只需要较少的训练数据。就好像它会自我反省,学会更好地提高自己。
这种自我博弈让我想起了一篇名叫“深度学习中的奇怪循环”(“The Strange Loop in Deep Learning)的早期文章。我写了关于深度学习的许多最新进展,例如阶梯网络和GAN,它们利用不断地循环来改善识别和生成结果。这么来说,当你有这样的机制能够对其最终输出进行评估时,还原度要高得多,也需要更少的训练数据。在AlphaGo Zero中根本就没有训练数据可言。 训练数据是在自我博弈中产生的。 例如,GAN通过使两个网络(鉴别器和发生器)相互协作来协同改进其生成。 AlphaGo Zero比较了以前游戏训练的网络与当前网络的功能。
萦绕在每个人脑海中一个很重要的问题是:“AlphaGo Zero的算法是否具有通用性?”DeepMind公开表示将把这项技术应用于药物发现。早些时候我写了关于如何评估深度学习技术的适用性(https://medium.com/intuitionmachine/where-is-deep-learning-applicable-understand-the-known-unknowns-f4272e3136ec)。 在这种评估中,任何领域有六个不确定因素需要解决:执行不确定性,观察不确定性,持续时间不确定性,行动不确定性,评估不确定性和训练不确定性。
在AlphaGo Zero中,训练的不确定性似乎已被解决。 AlphaGo Zero通过与自己的对抗来学习最好的策略。也就是说它能够自己想象各种情况,然后通过自我完善发现最好的策略。这种策略可以有效地被执行,因为所有其他不确定性都是已知的。也就是说一系列行动的结果不存在不确定性。有了这样完整的信息,行动的效果就是可以预测的。有一种方法来说明有效性,就是Go游戏的行为是可以预测的,但现实世界的系统并不是这样。
在许多现实世界的场景中,我们仍然可以建立相对精确的模拟或是一个虚拟世界。当然这里发现的策略迭代方法同样适用于这些虚拟世界。现在有些增强学习技术已经应用于虚拟世界中(比如视频游戏和战略游戏)。 DeepMind还没有公开在Atari游戏中使用策略迭代的实验结果。然而大多数游戏当然不需要这么复杂的策略,,但是有一些游戏比如Montezuma’s Revenge却又这种需求。 DeepMind的Atari游戏实验就像AlphaGo Zero,因为没有人工数据来训练机器。
AlphaGo Zero和很多游戏之间的区别在于,游戏中每个状态的决策都要复杂都要比围棋复杂很多。 事实上不同的游戏需要考虑更多一连串的决策。 蒙特卡搜索树同样也能解决这些问题吗?
还有一个很重要的问题就是需要记住之前做过的决策。 AlphaGo Zero似乎只关心当前的状态,对很早之前作出的判断并不关系。这不像人常常会根据以前的行为来确定自己的下一次行动。这是向对手传递动作的一种方法,但通常更像是假冒伪装。但这是一个只适用于人而不是机器的策略!
最后基于回合的游戏在现实世界中还有一个适用性的问题。现实世界中的相互作用有着更加动态和连续性的特点,互动的时间也相对比较长。而在游戏中,动作数量却是有限的。或许在未来这并不是一个问题,毕竟所有的互动需要双方采取行动和反应,而这些动作动过分块可以看成是离散的。
如果我要说出AlphaGo Zero中的一个比较务实的深度学习发现,那应该就是使用深度学习网络的策略迭代会产生令人吃惊的效果。在以前的研究中,我们只是刚刚意识到强化学习的能力。然而AlphaGo的成功有力的验证了这一点。
我们可以从人类语言的角度来思考这种迭代策略,语言就是讲各种复杂的概念反复层叠而成的。在AlphaGo Zero的情况下,它就是学到了一种没有传统包袱的新语言,它学到新语言是如此先进以至于常人无法理解。作为人类,我们通过与我们这个世界的的不断交互来了解世界。随后我们逐渐形成视觉空间,序列概念,韵律和动作。我们所有的理解来源于这些基本的行为。然而一台机器却可以不断地发现新概念,这个概念也不能归为这些基本行为之一。
这样说来很讽刺,当DeepMind训练了一个不带人来偏见的智能体,然而人类却发现根本不能理解它!不能理解的维度有很多,“太大而不能理解”可能是因为信息太多了,“太小而不能理解”可能是因为形成的最基本行为概念没法理解。让我们仔细想想,这确实是一个大多数人会忽视,但是DeepMind已经发现的震撼人心的事情!
特注:
请登录www.zhuanzhi.ai或者点击阅读原文,
顶端搜索“强化学习” 主题,直接获取查看获得全网收录资源进行查看, 涵盖论文等资源下载链接,并获取更多与AlphaGo Zero的核心技术强化学习的知识资料!如下图所示。
此外,请关注专知公众号(扫一扫最下面专知二维码,或者点击上方蓝色专知),后台回复“强化学习” 就可以获取全部知识资料的pdf文档集合下载链接!
欢迎转发到你的微信群和朋友圈,分享专业AI知识!
-END-
欢迎使用专知
专知,一个新的认知方式!目前聚焦在人工智能领域为AI从业者提供专业可信的知识分发服务, 包括主题定制、主题链路、搜索发现等服务,帮你又好又快找到所需知识。
使用方法>>访问www.zhuanzhi.ai, 或点击文章下方“阅读原文”即可访问专知
中国科学院自动化研究所专知团队
@2017 专知
专 · 知
关注我们的公众号,获取最新关于专知以及人工智能的资讯、技术、算法、深度干货等内容。扫一扫下方关注我们的微信公众号。


点击“阅读原文”,使用专知!
展开全文



