推荐系统顶会 RecSys2019 最佳论文奖出炉!可复现性成为焦点—18篇顶级会议只有7篇可以合理复现
【导读】第 13 届推荐系统顶级会议 ACM RecSys 正在 9 月 16 日到 20 日的丹麦哥本哈根举行。来自米兰理工大学的Maurizio Ferrari Dacrema等人的论文《Are We Really Making Much Progress? A Worrying Analysis of Recent Neural Recommendation Approaches》获得了最佳长文。
这篇论文也非常有意思,针对当前top-n推荐任务中已有前沿方法的复现性进行了一系列实验分析。考虑了过去几年在顶级研究会议上提出的18种算法(KDD、SIGIR、WWW和RecSys)。但只有7中算法能够合理地复现,并且其中6种方法没有最简单的启发式方法(例如,基于最近邻居或基于图的技术)好。另一方面,作者也发现,一些论文通常通过将一个复杂的神经模型与另一个神经模型进行比较来说明其方法的优越性但这是不够的,因为该神经模型不一定是最好的Baseline。作者也open了其代码,在文末我们也把这18篇论文列出来了。这篇工作揭示了当前机器学习科研学术中存在的一些潜在问题,值得各位科研工作者深思。


最佳论文奖证书(来自网络)
题目:Are We Really Making Much Progress? A Worrying Analysis of Recent Neural Recommendation Approaches
作者: Maurizio Ferrari Dacrema, Paolo Cremonesi, Dietmar Jannach

【摘要】深度学习技术已经成为研究推荐系统算法方面的研究人员的首选方法。随着人们对机器学习兴趣的增强(相关领域论文越来越多),跟踪代表当前最先进水平的任务(例如top-n推荐任务)变得越来越困难。同时,最近的一些论文指出了当今应用机器学习研究实践中存在的问题,例如,在提出新模型时,结果的可重复性或基线的选择。
在这项工作中,我们报告了对top-n推荐任务的算法的系统分析结果。特别地,我们考虑了过去几年在顶级研究会议上提出的18种算法。其中只有7个可以合理地复现。然而,对于这些方法,结果表明,其中6种方法没有较为简单的启发式方法(例如,基于最近邻居或基于图的技术)性能好。剩下的一个明显优于baseline,但并没有始终优于一个well-tuned的非神经线性排序方法。总的来说,我们的工作揭示了当今机器学习学术中存在的一些潜在问题,并呼吁改进这一领域。
参考链接:
https://arxiv.org/abs/1907.06902
代码
作者也 open 其代码和数据集,以及比较的7种最前沿的方法的code,对这感兴趣地建议跑跑代码,学习一下。
https://github.com/MaurizioFD/RecSys2019_DeepLearning_Evaluation
请关注专知公众号(点击上方蓝色专知关注)
后台回复“RecSys2019B” 就可以获取最新论文的下载链接~
引言
在短短几年内,深度学习技术开始主导推荐系统的算法研究领域。针对不同的设置和算法任务,提出了新的推荐方法,包括基于长期偏好的top-n推荐和基于会话的[36]推荐。鉴于人们对机器学习越来越感兴趣,最近发表的相关研究论文数量也相应增加,以及深度学习技术在视觉或语言处理等其他领域的成功,我们可以预期,这些工作也会在推荐系统领域取得实质性进展。然而,在机器学习的其他应用领域也有迹象表明,所取得的进步(以相对于现有模型的精确度改进来衡量)并不总是像预期的那样强大。
不同的因素导致了下面这些学术不好的现象,包括(i)比较弱的baseline; (ii)建立弱的方法作为新baseline; (iii)比较其他论文以及复现其结果的困难。
本文通过一系列研究工作,目标是阐明上述问题是否也存在于基于深度学习的推荐算法领域。特别地,本文着重解决了两个主要的研究问题:
复现性:该领域最近的研究在多大程度上是可重复的(通过合理的努力)?
进展:与相对简单但调优良好的baseline方法相比,最近的算法实际上在多大程度上带来了更好的性能结果?
为了回答这些问题,本文进行了一个系统的研究,我们分析了一些研究论文,这些论文使用深度学习的方法,为top-n推荐任务提出了新的算法方法。为此,我们浏览了KDD、SIGIR、TheWebConf (WWW)和RecSys最近的会议接受论文,以便进行相应的研究工作。我们确定了18篇相关论文。
在第一个步骤中,我们尝试复现论文中报告的结果,这些情况下,源代码由作者提供,并且我们可以访问实验中使用的数据。最后,我们仅有7篇论文就可以以可接受的确定性程度重现已发表的结果。因此,我们工作的第一项贡献是对该领域当前研究的可复现性水平进行评估。
在我们研究的第二部分,我们重新执行了原始论文中报告的实验,并且在比较中加入了额外的baseline方法。特别地,我们使用了基于用户和基于商品的最近邻的启发式方法,以及简单的基于图的方法的两种变体。我们的研究出乎意料地显示,在大多数被调查的案例中(7个中有6个),所提出的深度学习技术并不总是优于简单的、但经过fine-tune的baseline方法。在一个例子中,即使是向每个人推荐最受欢迎的商品的非个性化方法,在某些准确性度量方面也是最好的。因此,我们的第二个贡献在于发现了与当前机器学习研究实践相关的一个潜在的更深远的问题。
本文组织如下。接下来,在第二部分,我们描述了我们的研究方法和我们如何复现现有的方法。第3节提供了重新执行实验的结果,同时还提供了附加的baseline。

表1:从2015年到2018年,每个会议系列的top-n推荐深度学习算法以及可重复性。(文末有其具体信息)
第3节总结了将可复现的工作与所述baseline方法的比较结果。分享详细的统计数据、结果和最终参数。
3.1 协同记忆网络(Collaborative Memory Networks, CMN)
CMN方法是在SIGIR ' 18上提出的,将记忆网络和神经注意力机制与潜在因素和邻域模型[10]相结合。
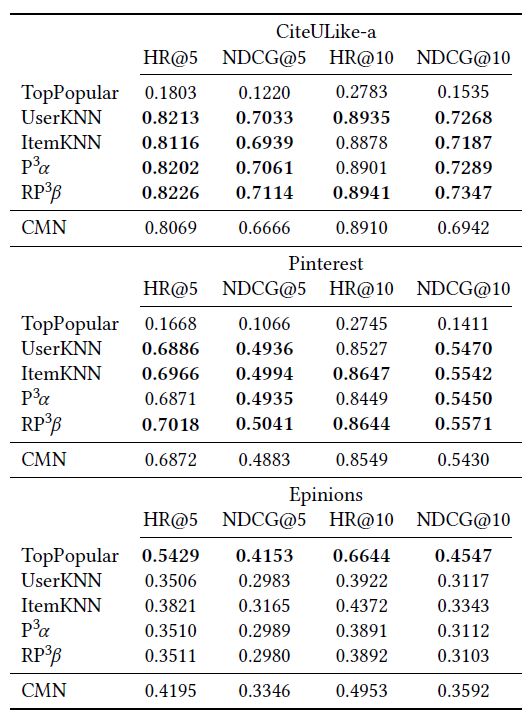
表2: 使用原始论文中报告的度量和cutofs的CMN方法的实验结果。当数字对应于最佳结果或baseline优于CMN时,数字以粗体显示。
分析表明,在baseline优化之后,CMN在任何情况下都不是任何数据集中性能最好的方法。
3.2 基于Metapath的推荐上下文( Metapath based Context for RECommendation, MCRec)
MCRec[17]是在KDD ' 18上提出的,它是一个基于Meta路径的模型,利用电影类型等辅助信息进行top-n推荐。
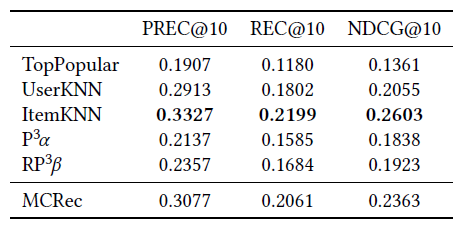
表3:MCRec与baseline的比较(Movie-Lens100k)
表3显示,传统的ItemKNN方法在正确调参时,在所有性能指标上都优于MCRec。
3.3 协同变分自编码器(Collaborative Variational Autoencoder,CVAE)
在KDD ' 18上提出的CVAE方法[23]是一种综合考虑内容和评级信息的技术。该模型以无监督的方式从内容数据中学习深层的潜在表示,并从内容和评级中学习商品和用户之间的隐式关系。

表4:CVAE (CiteULike-a)的实验结果。
一般来说,在列表长度为50时,ItemKNN-CFCBF在所有测试的配置中始终优于CVAE。
3.4 协同深度学习(Collaborative Deep Learning,CDL)
所讨论的CVAE方法将KDD’15中较早且经常被引用的CDL方法[48]作为其baseline之一,并使用了相同的评估程序和CiteULike数据集。
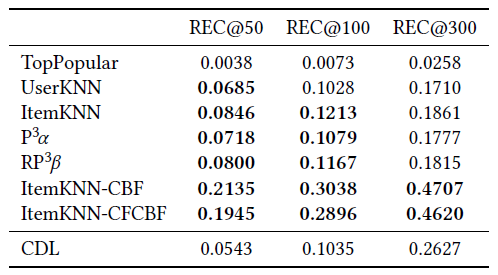
表5:dense CiteULike-a数据集上CDL的实验结果。
3.5 神经协同过滤(Neural Collaborative Filtering, NCF)
在WWW ' 17上提出的基于神经网络的协同过滤[14],通过用一种可以从数据中学习任意函数的神经结构来代替内积,从而推广了矩阵因子分解。
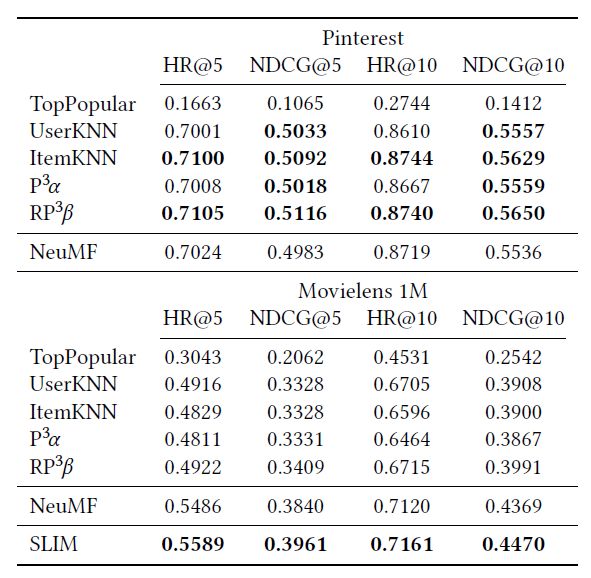
表6:NCF实验结果。
表6显示,尽管NeuMF优于baseline,但SLIM方法(一个比较简单的线性方法[33])比baseline好,在这个数据集上也优于NeuMF。
3.6 频谱协同滤波(Spectral Collaborative Filtering,SpectralCF)
SpectralCF[53]是在RecSys ' 18会议上提出的,它是专门针对冷启动问题而设计的,它是基于频谱图理论的概念。
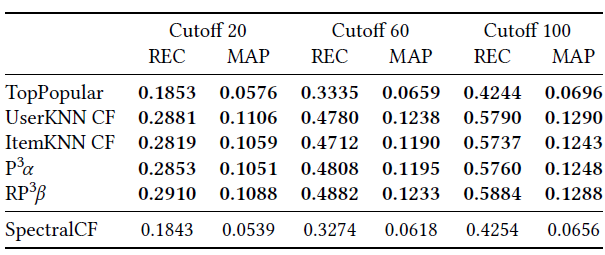
表7: SpectralCF的实验结果(MovieLens1M,使用自己的随机分割和5次重复测量)。
3.7 Variational Autoencoders for Collaborative Filtering,Mult-VAE
Mult-VAE[24]是一种基于变分自编码器的隐式反馈协同滤波方法。该论文发表于WWW ' 18。
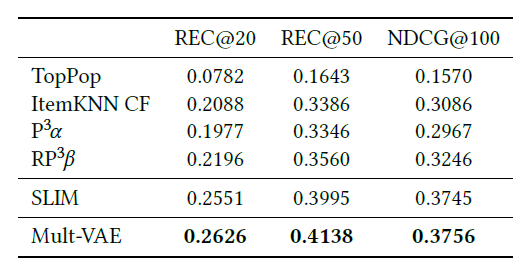
表8: Mult-VAE (Netfix data),使用原始论文中报告的指标和cutof。
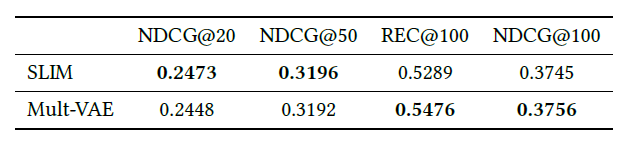
表9: 使用Netfix数据集的额外cutof长度的Mult-VAE的实验结果。
另一方面,作者也发现了另一个有趣的现象,许多最近的论文使用了神经协同过滤方法(NCF)[14]作为他们最好的baseline之一。然而,根据作者的分析,此方法在一个数据集上能够被简单的baseline所超过,并且不会在另一个数据集上产生更好的结果,而线性回归方法的实现(SLIM)也优于该方法。因此,通常通过将一个复杂的神经模型与另一个神经模型进行比较来说明其方法的优越性是不够的,因为该神经模型不一定是最好的Baseline。
结论
在本文中,作者分析了一些最近出现的用于top-n推荐的神经算法。分析表明,复现已发表的研究仍然具有挑战性。此外,通过概念上和计算上更简单的算法,可以至少在某些数据集上超越大多数已发表的工作。因此,我们的工作表明在评估这一领域的算法贡献方面需要有更加严格和更好的方式。
作者也说到,到目前为止,我们的分析仅限于在某些会议系列中发表的论文。在我们正在进行和未来的工作中,我们计划将我们的分析扩展到其他出版机构和其他类型的推荐问题。此外,我们计划考虑更传统的算法作为baseline,例如,基于矩阵分解。(期待)
七篇论文可复现List:
[10] Travis Ebesu, Bin Shen, and Yi Fang. 2018. Collaborative Memory Network for Recommendation Systems. In Proceedings SIGIR ’18. 515–524.
[14] Xiangnan He, Lizi Liao, Hanwang Zhang, Liqiang Nie, Xia Hu, and Tat-Seng Chua. 2017. Neural collaborative fltering. In Proceedings WWW ’17. 173–182.
[17] Binbin Hu, Chuan Shi, Wayne Xin Zhao, and Philip S Yu. 2018. Leveraging meta-path based context for top-n recommendation with a neural co-attention model. In Proceedings KDD ’18. 1531–1540.
[23] Xiaopeng Li and James She. 2017. Collaborative variational autoencoder for recommender systems. In Proceedings KDD ’17. 305–314.
[24] Dawen Liang, Rahul G Krishnan, Matthew D Hofman, and Tony Jebara. 2018. Variational Autoencoders for Collaborative Filtering. In Proceedings WWW ’18. 689–698.
[48] Hao Wang, Naiyan Wang, and Dit-Yan Yeung. 2015. Collaborative deep learning for recommender systems. In Proceedings KDD ’15. 1235–1244.
[53] Lei Zheng, Chun-Ta Lu, Fei Jiang, Jiawei Zhang, and Philip S. Yu. 2018. Spectral Collaborative Filtering. In Proceedings RecSys ’18. 311–319.
十一篇论文不可复现List:
[43] Yi Tay, Luu Anh Tuan, and Siu Cheung Hui. 2018. Multi-Pointer Co-Attention Networks for Recommendation. In Proceedings SIGKDD ’18. 2309–2318.
[41] Zhu Sun, Jie Yang, Jie Zhang, Alessandro Bozzon, Long-Kai Huang, and Chi Xu. 2018. Recurrent Knowledge Graph Embedding for Efective Recommendation. In Proceedings RecSys ’18. 297–305.
[6] Homanga Bharadhwaj, Homin Park, and Brian Y. Lim. 2018. RecGAN: Recurrent Generative Adversarial Networks for Recommendation Systems. In Proceedings RecSys ’18. 372–376.
[38] Noveen Sachdeva, Kartik Gupta, and Vikram Pudi. 2018. Attentive Neural Architecture Incorporating Song Features for Music Recommendation. In Proceedings RecSys ’18. 417–421.
[44] Trinh Xuan Tuan and Tu Minh Phuong. 2017. 3D Convolutional Networks for Session-based Recommendation with Content Features. In Proceedings RecSys ’17. 138–146.
[21] Donghyun Kim, Chanyoung Park, Jinoh Oh, Sungyoung Lee, and Hwanjo Yu. 2016. Convolutional Matrix Factorization for Document Context-Aware Recommendation. In Proceedings RecSys ’16. 233–240.
[45] Flavian Vasile, Elena Smirnova, and Alexis Conneau. 2016. Meta-Prod2Vec: Product Embeddings Using Side-Information for Recommendation. In Proceedings RecSys ’16. 225–232.
[32] Jarana Manotumruksa, Craig Macdonald, and Iadh Ounis. 2018. A Contextual Attention Recurrent Architecture for Context-Aware Venue Recommendation. In Proceedings SIGIR ’18. 555–564.
[7] Jingyuan Chen, Hanwang Zhang, Xiangnan He, Liqiang Nie, Wei Liu, and Tat-Seng Chua. 2017. Attentive collaborative fltering: Multimedia recommendation with item-and component-level attention. In Proceedings SIGIR ’17. 335–344.
[42] Yi Tay, Luu Anh Tuan, and Siu Cheung Hui. 2018. Latent relational metric learning via memory-based attention for collaborative ranking. In Proceedings WWW ’18. 729–739.
[11] Ali Mamdouh Elkahky, Yang Song, and Xiaodong He. 2015. A multi-view deep learning approach for cross domain user modeling in recommendation systems. In Proceedings WWW ’15. 278–288.
-END-
专 · 知
专知,专业可信的人工智能知识分发,让认知协作更快更好!欢迎登录www.zhuanzhi.ai,注册登录专知,获取更多AI知识资料!

欢迎微信扫一扫加入专知人工智能知识星球群,获取最新AI专业干货知识教程视频资料和与专家交流咨询!

请加专知小助手微信(扫一扫如下二维码添加),加入专知人工智能主题群,咨询技术商务合作~

专知《深度学习:算法到实战》课程全部完成!570+位同学在学习,现在报名,限时优惠!网易云课堂人工智能畅销榜首位!

点击“阅读原文”,了解报名专知《深度学习:算法到实战》课程
展开全文



