【干货】基于视频的行人再识别新进展:区域质量估计方法和高质量的数据集
【导读】近日,针对基于视频的行人再识别中局部噪声大、数据集质量低的问题,来自商汤科技(SenseTime)、香港中文大学和北京航空航天大学的学者发表论文提出基于区域的质量估计网络和一个更高质量的数据集。其方法使用一种巧妙的训练方法,能够提取不同帧之间的互补的区域信息,从而更好地进行训练。其数据集包含7,694个tracklets,超过590,000个图片,并具有年龄跨度大、姿态多样性等特点。所提出的方法在PRID 2011,iLIDS-VID和MARS分别达到91.8%,77.1%和77.83%的效果。数据集已公开。
论文:Region-based Quality Estimation Network for Large-scale Person Re-identification

▌摘要
基于视频的行人再识别性能的主要限制之一是由遮挡,模糊和光照引起的局部噪声。由于单个帧的不同区域具有不同的质量,并且相同区域的质量也在逐帧之间变化,所以解决该问题比较好的方法是有效地聚集序列中所有帧的互补信息。如果当前帧中的某区域的质量差,那么可以使用其他帧对应的区域来补偿质量差的图像区域带来的影响。为此,这篇文章提出了一种新颖的基于区域的质量估计网络(RQEN),其使用一种巧妙的训练方法,能够提取不同帧之间的互补的区域信息,从而更好地进行训练。与其他特征提取方法相比,作者在PRID 2011,iLIDS-VID和MARS分别达到91.8%,77.1%和77.83%的有竞争力的效果。
此外,为缓解行人再识别数据集的不足,本文还提供了一个高质量的数据集,名为“Labeled Pedestrian in the Wild (LPW)”,其中包含7,694个tracklets,超过590,000个图片。尽管本数据集的规模比较大,但是注释非常干净。而且,本数据集在以下几个方面更具挑战性:人物年龄差异分布在儿童和老年之间,人的姿态具有多样性:除了正常的行走状态之外,还包括跑步和骑自行车。
▌详细内容
行人再识别的目的是通过比较探针图像和图像库之间的相似性来识别行人。以往的方法可以分为两类:一类是学习更好的特征提取器,另一类是设计度量学习方法(metric learning methods)。基于大规模的训练数据,这两类方法通过卷积神经网络和精细的优化策略都可以在基准数据集(benchmarks)上取得良好的表现,但其性能可能会因为遮挡或明显的身体移动而受到很大的影响。
最近的方法不仅仅使用行人的单个图像,而是采用行人的图像集来进行特征提取(McLaughlin,Martinez del Rincon和Miller 2016)和距离度量学习(You et al 2016)。与单个图像相比,视频序列中的帧提供了更丰富的互补信息(Zheng et al 2016)。将序列中的帧进行聚合的一个最直观的方式就是取平均(Karanam,Li和Radke 2015),但这可能会引入不必要的噪音信息。如图1所示,这个视频序列中的一些图像有部分遮挡的情况,使用简单的平均方法会导致识别失败,因为有效信息被噪声信息削弱了。最近的工作(Liu,Yan,和Ouyang,2017)提出了一个新的模型,它为每个图像帧生成一个自适应分数。然而,这个分数并没有说明哪个部分会造成影响,并且可能由于其小部分噪声而干扰整个框架,造成其他区域中的有价值的信息丢失。这篇文章提出的RQEN方法可以将更多的注意力集中在序列中的有效图像区域上,并且聚集不同帧之间的互补区域信息。

图1:说明不同的聚合方法。第一行是一系列行人图像,第二行使第一个卷积层提取的feature map(特征图)。
考虑到上述因素,为了使提出的系统对部分遮挡或有噪声的图像具有鲁棒性,并能够有选择地使用序列中基于互补区域的信息,这篇文章提出了一种自适应能力更强的基于区域的质量估计网络(RQEN),网络包括局部特征提取部分和基于区域的质量预测部分。其目的是削弱质量差的图像区域的影响,同时利用序列中的互补信息。该方法使用端到端(end-to-end)训练使网络能够估计图像不同区域的信息的有效性。在后续聚合单元的辅助下,图像的置信度较高的区域将为图像序列的表示贡献更多的信息,反之,具有遮挡或噪声的图像区域占据较低的比例。
另一个问题是目前的行人再识别数据集(Wang等2014; Hirzer等2011; Li等2014; Zheng等2015)在规模或干净度方面都存在缺陷。一般的数据库行人身份个数范围从200到1500不等,对于更广泛的实验来说还是太少。目前也存在规模相对较大的数据集,但由于其清洁度较差导致检测或跟踪任务失败。而且,大部分数据集中的行人,都是通过手绘边界框精确对齐的。 但事实上,行人检测器检测到的边框可能会发生错位或部分缺失(Zheng et al 2015)。为了解决这些问题,本文引入一个既清晰又接近实际的大规模数据集。
为了弥补大规模、干净数据集的缺失,本文提出了一个新的数据集,名为“Labeled Pedestrian in the Wild (LPW)”。它包含三个不同的场景共2731名行人,其中每一个行人图片由2到4台摄像机拍摄。 LPW的显着特征是:包含7,694个tracklets,超过590000个图像。它与现有的数据集有三个重要区别:大规模且干净度高、自动检测边界框、更多拥挤的场景和更大的年龄跨度。这个数据集提供了一个更真实、更具挑战性的benchmark,这有助于进一步探索更强大的算法。
总的来说,这篇文章的贡献如下:
首先考虑了图像不同区域的质量,以便更好地将序列中的互补区域信息聚合起来,利用较高质量的特定图像区域信息来弥补其他帧质量差的相同区域。
提出联合训练多级特征的工作流程,使基于区域的质量预测器能够在iLIDS-VID和PRID 2011上对区域质量进行适当估计,从而实现基于视频的行人再识别。
建立一个大规模、干净度高的行人数据集“Labeled Pedestrian in the Wild (LPW)”。 它包含7,694个tracklets和超过59万个图像,可以在http://liuyu.us/dataset/lpw/index.html 进行下载。
▌方法简介
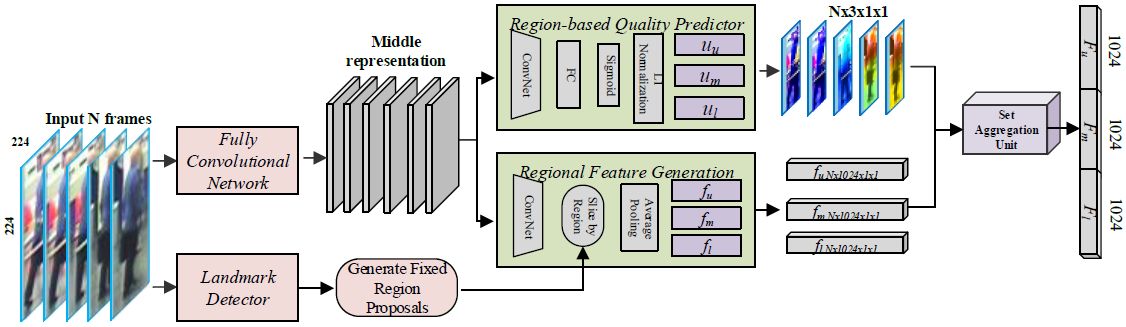
图2:提出的RQEN模型的流程。网络的输入是同一个人的图像集。利用全卷积网络生成每个图像的中间表示。然后将这些表示输入到具有landmarks和基于区域质量预测器的局部特征生成单元。图像中用不同颜色表示不同区域的得分(红到蓝表示得分[0-1])。然后,所有图像的分数和特征通过聚合单元进行融合,并生成图像集的最终表示。
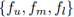
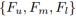
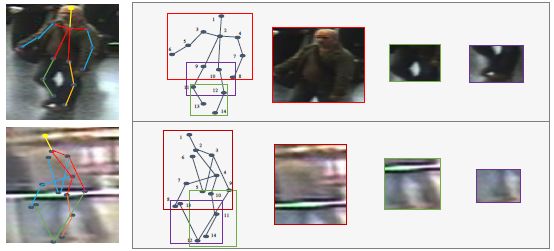
图3:在iLIDS-VID上检测到的有14个landmarks的样本。第一行的landmarks被成功检测到,第二行图像由于分辨率较低并且很模糊,因此没有被检测到。
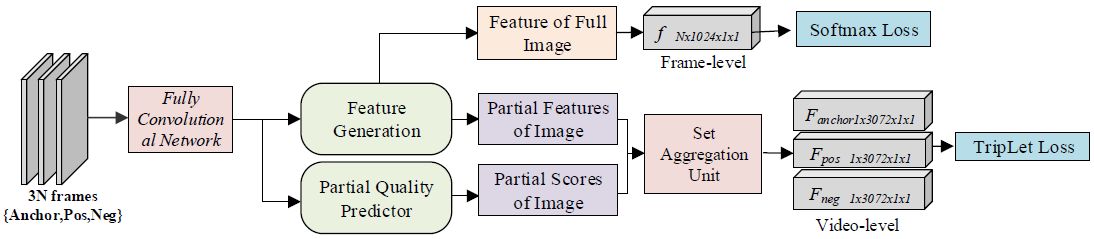
图4:RQEN训练的结构图。帧级特征通过Softmax损失进行监督,而视频级特征则由三元组损失进行监督。
图4展示了RQEN的训练过程,RQEN的整体损失函数见下式:
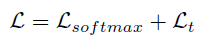
其中,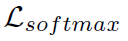
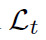
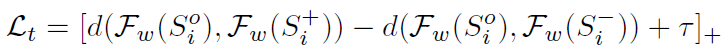
这里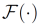
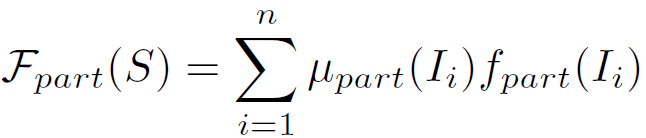
这里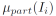
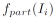
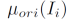
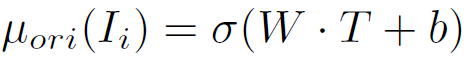
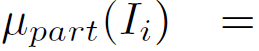
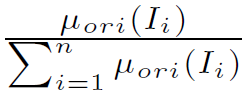
其中,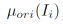
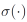
▌实验结果

图5: LPW数据库中来自不同相机的图像样张。其中姿态种类多,年龄跨度大。

表1:LPW数据库与存在的数据库进行比较。其他数据库包括:MAERS(Zheng et al 016),Market(Zheng et al 2015),iLIDSVID(wang et al 2014),PRID2011(Hirzer et al 011)和CUHK3(Li et al 2014). DT故障表示是否在序列中的检测或跟踪失败。 符号#表示相应的数量。
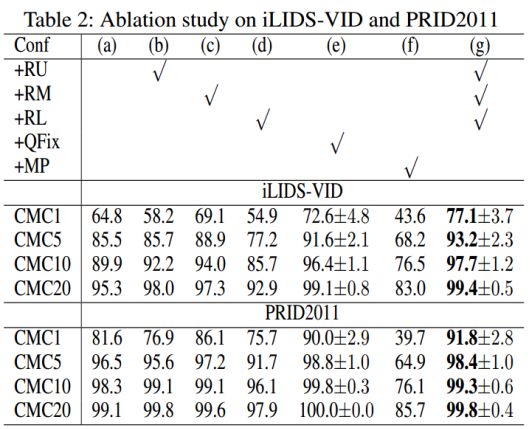
表2:关于iLIDS-VID和PRID2011数据集上的Ablation研究。
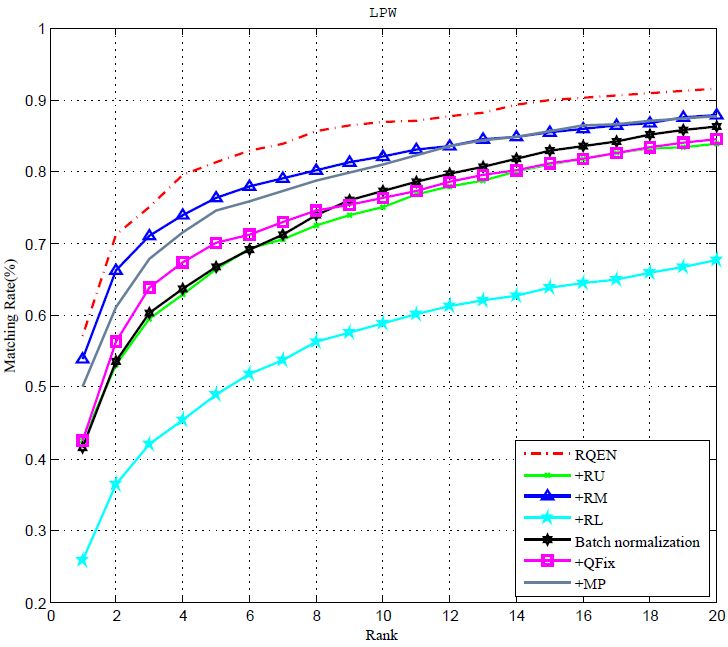
图6:在LPW数据集上进行RQEN,baseline和ablation研究实验。
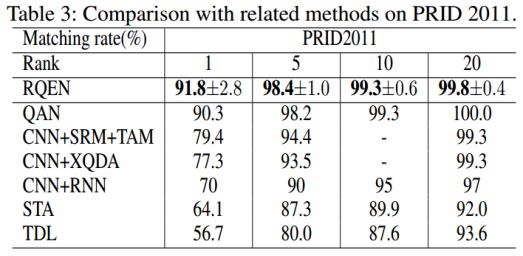
表3:在PRID 2011数据集上比较不同的方法。
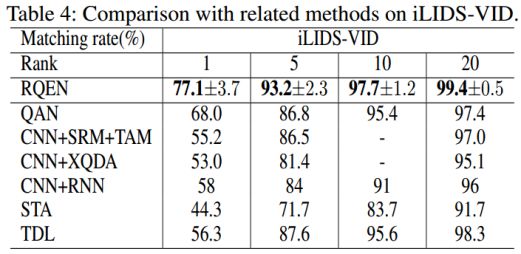
表4:在iLIDS-VID数据集上比较不同的方法。

表5:在LPW上的迁移学习能力。在预训练数据集ImageNet和LPW上比较提出的方法的性能。
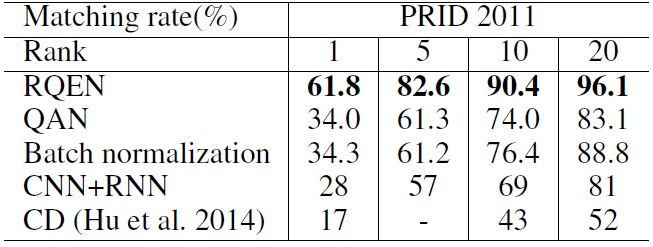
表6:跨不同数据集进行性能测试。CD(Hu et al 014)表示在Shinpuhkan 2014上训练,其他方法是在iLIDS-VID数据集上训练。PRID2011数据集用来进行测试。
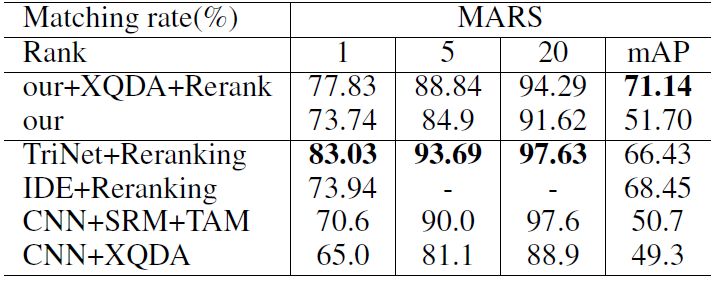
表7:在MARS数据集上比较几个最好的方法。

图7:图像不同部分的质量分数。分数从[0 -1]分别映射到不同的颜色(蓝色-红色)
▌结论
本文针对基于视频的行人再识别问题,提出一种基于区域的质量估计网络(RQEN)。RQEN可以学习每个图像的局部质量,并聚合图像序列中不同帧互补的图像局部信息。这篇文章采用巧妙的梯度设计来设计端到端的训练策略,并通过分类和验证损失联合训练网络。RQEN在PRID 2011和iLIDS-VID上取得了最先进的成果。作者还提出了一个大型的、干净的数据集,名为“Labeled Pedestrian in the Wild (LPW)”,其中包含7,694个tracklets,超过59万个图像。 数据集具有遮挡、姿态变化大、年龄跨度大等特点,因此更具有挑战性,适合实际应用。
参考链接:
https://arxiv.org/abs/1711.08766
-END-
专 · 知
人工智能领域主题知识资料查看获取:【专知荟萃】人工智能领域26个主题知识资料全集(入门/进阶/论文/综述/视频/专家等)
同时欢迎各位用户进行专知投稿,详情请点击:
【诚邀】专知诚挚邀请各位专业者加入AI创作者计划!了解使用专知!
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

请加专知小助手微信(Rancho_Fang),加入专知主题人工智能群交流!

点击“阅读原文”,使用专知!
展开全文



