【论文推荐】最新5篇视觉目标跟踪相关论文—递归神经网络、深度适应计算策略、视觉目标跟踪基准、深度核化相关滤波、检测并跟踪
【导读】专知内容组整理了最近五篇视觉目标跟踪(Object Tracking)相关文章,为大家进行介绍,欢迎查看!
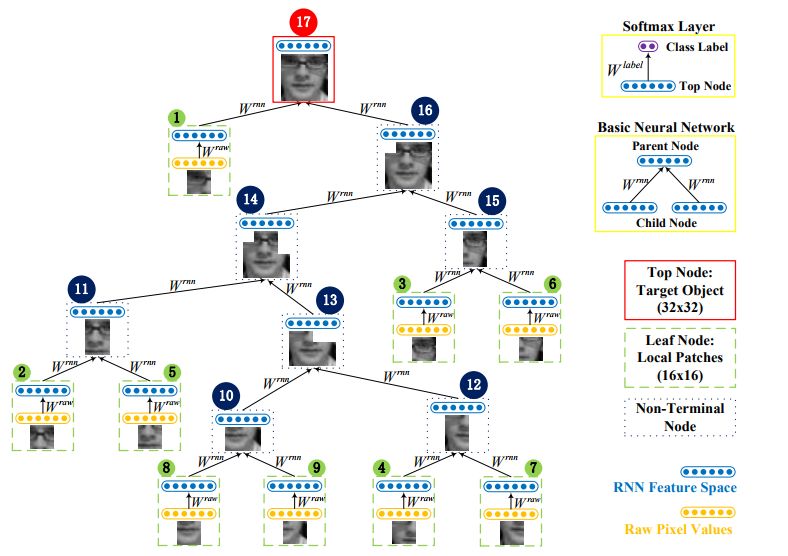
1. Learning Hierarchical Features for Visual Object Tracking with Recursive Neural Networks(使用递归神经网络学习视觉目标跟踪的层次特征)
作者:Li Wang,Ting Liu,Bing Wang,Xulei Yang,Gang Wang
摘要:Recently, deep learning has achieved very promising results in visual object tracking. Deep neural networks in existing tracking methods require a lot of training data to learn a large number of parameters. However, training data is not sufficient for visual object tracking as annotations of a target object are only available in the first frame of a test sequence. In this paper, we propose to learn hierarchical features for visual object tracking by using tree structure based Recursive Neural Networks (RNN), which have fewer parameters than other deep neural networks, e.g. Convolutional Neural Networks (CNN). First, we learn RNN parameters to discriminate between the target object and background in the first frame of a test sequence. Tree structure over local patches of an exemplar region is randomly generated by using a bottom-up greedy search strategy. Given the learned RNN parameters, we create two dictionaries regarding target regions and corresponding local patches based on the learned hierarchical features from both top and leaf nodes of multiple random trees. In each of the subsequent frames, we conduct sparse dictionary coding on all candidates to select the best candidate as the new target location. In addition, we online update two dictionaries to handle appearance changes of target objects. Experimental results demonstrate that our feature learning algorithm can significantly improve tracking performance on benchmark datasets.
期刊:arXiv, 2018年1月6日
网址:
http://www.zhuanzhi.ai/document/c8ed971ddd77d456c1270db089240e13
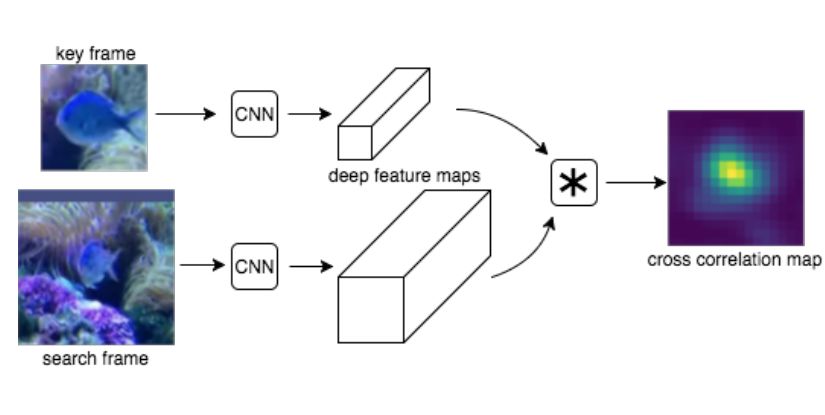
2. Depth-Adaptive Computational Policies for Efficient Visual Tracking(基于深度适应计算策略的有效视觉跟踪)
作者:Chris Ying,Katerina Fragkiadaki
摘要:Current convolutional neural networks algorithms for video object tracking spend the same amount of computation for each object and video frame. However, it is harder to track an object in some frames than others, due to the varying amount of clutter, scene complexity, amount of motion, and object's distinctiveness against its background. We propose a depth-adaptive convolutional Siamese network that performs video tracking adaptively at multiple neural network depths. Parametric gating functions are trained to control the depth of the convolutional feature extractor by minimizing a joint loss of computational cost and tracking error. Our network achieves accuracy comparable to the state-of-the-art on the VOT2016 benchmark. Furthermore, our adaptive depth computation achieves higher accuracy for a given computational cost than traditional fixed-structure neural networks. The presented framework extends to other tasks that use convolutional neural networks and enables trading speed for accuracy at runtime.
期刊:arXiv, 2018年1月2日
网址:
http://www.zhuanzhi.ai/document/b4cf6bf8987ce1aaeea88df664be1177
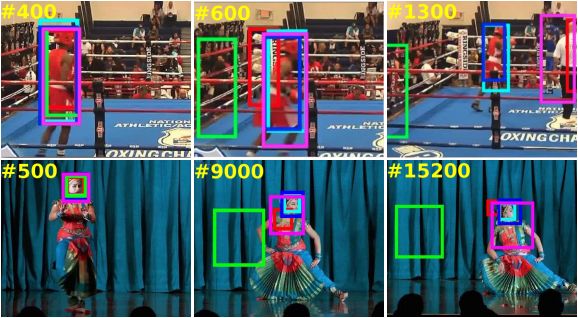
3. Long-Term Visual Object Tracking Benchmark(长期的视觉目标跟踪基准)
作者:Abhinav Moudgil,Vineet Gandhi
摘要:In this paper, we propose a new long video dataset (called Track Long and Prosper - TLP) and benchmark for visual object tracking. The dataset consists of 50 videos from real world scenarios, encompassing a duration of over 400 minutes (676K frames), making it more than 20 folds larger in average duration per sequence and more than 8 folds larger in terms of total covered duration, as compared to existing generic datasets for visual tracking. The proposed dataset paves a way to suitably assess long term tracking performance and possibly train better deep learning architectures (avoiding/reducing augmentation, which may not reflect realistic real world behavior). We benchmark the dataset on 17 state of the art trackers and rank them according to tracking accuracy and run time speeds. We further categorize the test sequences with different attributes and present a thorough quantitative and qualitative evaluation. Our most interesting observations are (a) existing short sequence benchmarks fail to bring out the inherent differences in tracking algorithms which widen up while tracking on long sequences and (b) the accuracy of most trackers abruptly drops on challenging long sequences, suggesting the potential need of research efforts in the direction of long term tracking.
期刊:arXiv, 2017年12月28日
网址:
http://www.zhuanzhi.ai/document/fb89e63302d559deced080c7620e490b
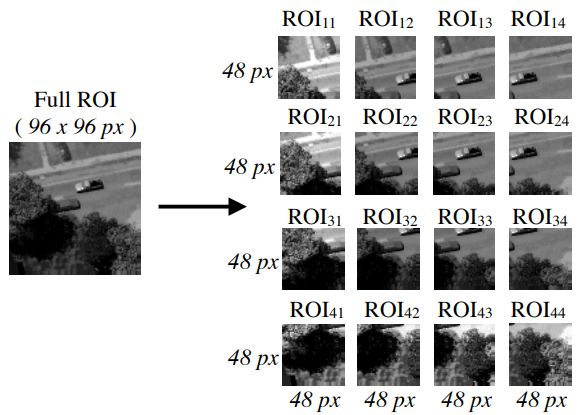
4. Tracking in Aerial Hyperspectral Videos using Deep Kernelized Correlation Filters(深度核化相关滤波在空中高光谱视频中的应用)
作者:Burak Uzkent,Aneesh Rangnekar,Matthew J. Hoffman
摘要:Hyperspectral imaging holds enormous potential to improve the state-of-the-art in aerial vehicle tracking with low spatial and temporal resolutions. Recently, adaptive multi-modal hyperspectral sensors, controlled by Dynamic Data Driven Applications Systems (DDDAS) methodology, have attracted growing interest due to their ability to record extended data quickly from the aerial platforms. In this study, we apply popular concepts from traditional object tracking - (1) Kernelized Correlation Filters (KCF) and (2) Deep Convolutional Neural Network (CNN) features - to the hyperspectral aerial tracking domain. Specifically, we propose the Deep Hyperspectral Kernelized Correlation Filter based tracker (DeepHKCF) to efficiently track aerial vehicles using an adaptive multi-modal hyperspectral sensor. We address low temporal resolution by designing a single KCF-in-multiple Regions-of-Interest (ROIs) approach to cover a reasonable large area. To increase the speed of deep convolutional features extraction from multiple ROIs, we design an effective ROI mapping strategy. The proposed tracker also provides flexibility to couple it to the more advanced correlation filter trackers. The DeepHKCF tracker performs exceptionally with deep features set up in a synthetic hyperspectral video generated by the Digital Imaging and Remote Sensing Image Generation (DIRSIG) software. Additionally, we generate a large, synthetic, single-channel dataset using DIRSIG to perform vehicle classification in the Wide Area Motion Imagery (WAMI) platform . This way, the high-fidelity of the DIRSIG software is proved and a large scale aerial vehicle classification dataset is released to support studies on vehicle detection and tracking in the WAMI platform.
期刊:arXiv, 2017年12月27日
网址:
http://www.zhuanzhi.ai/document/04b73ae2f925a548b8cf690eb0932717
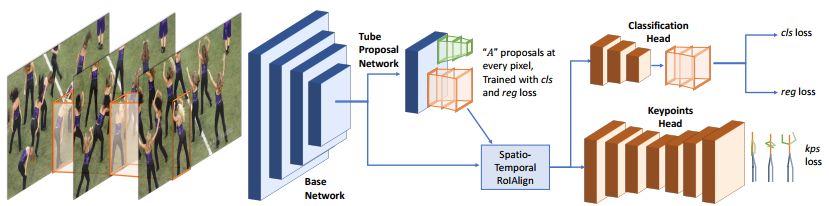
5. Detect-and-Track: Efficient Pose Estimation in Videos(检测并跟踪:视频中的有效姿态估计)
作者:Rohit Girdhar,Georgia Gkioxari,Lorenzo Torresani,Manohar Paluri,Du Tran
摘要:This paper addresses the problem of estimating and tracking human body keypoints in complex, multi-person video. We propose an extremely lightweight yet highly effective approach that builds upon the latest advancements in human detection and video understanding. Our method operates in two-stages: keypoint estimation in frames or short clips, followed by lightweight tracking to generate keypoint predictions linked over the entire video. For frame-level pose estimation we experiment with Mask R-CNN, as well as our own proposed 3D extension of this model, which leverages temporal information over small clips to generate more robust frame predictions. We conduct extensive ablative experiments on the newly released multi-person video pose estimation benchmark, PoseTrack, to validate various design choices of our model. Our approach achieves an accuracy of 55.2% on the validation and 51.8% on the test set using the Multi-Object Tracking Accuracy (MOTA) metric, and achieves state of the art performance on the ICCV 2017 PoseTrack keypoint tracking challenge.
期刊:arXiv, 2017年12月26日
网址:
http://www.zhuanzhi.ai/document/98ca61d328d8eb3633ea8010f75b0a5d
-END-
专 · 知
人工智能领域主题知识资料查看获取:【专知荟萃】人工智能领域26个主题知识资料全集(入门/进阶/论文/综述/视频/专家等)
同时欢迎各位用户进行专知投稿,详情请点击:
【诚邀】专知诚挚邀请各位专业者加入AI创作者计划!了解使用专知!
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

请加专知小助手微信(Rancho_Fang),加入专知主题人工智能群交流!
点击“阅读原文”,使用专知!
展开全文



