【论文推荐】最新5篇知识图谱相关论文—强化学习、习知识图谱的表示、词义消除歧义、并行翻译嵌入、图数据库
【导读】专知内容组整理了最近五篇知识图谱(Knowledge Graph)相关文章,为大家进行介绍,欢迎查看!
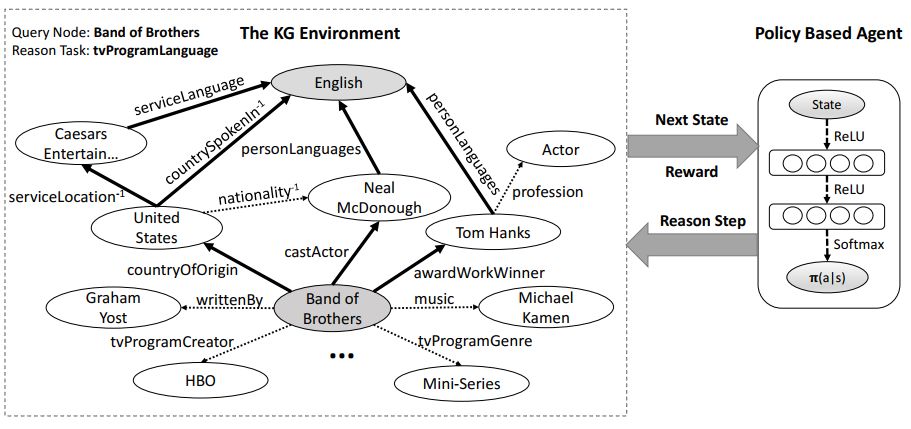
1. DeepPath: A Reinforcement Learning Method for Knowledge Graph Reasoning(DeepPath:一种知识图推理的强化学习方法)
作者:Wenhan Xiong,Thien Hoang,William Yang Wang
摘要:We study the problem of learning to reason in large scale knowledge graphs (KGs). More specifically, we describe a novel reinforcement learning framework for learning multi-hop relational paths: we use a policy-based agent with continuous states based on knowledge graph embeddings, which reasons in a KG vector space by sampling the most promising relation to extend its path. In contrast to prior work, our approach includes a reward function that takes the accuracy, diversity, and efficiency into consideration. Experimentally, we show that our proposed method outperforms a path-ranking based algorithm and knowledge graph embedding methods on Freebase and Never-Ending Language Learning datasets.
期刊:arXiv, 2018年1月9日
网址:
http://www.zhuanzhi.ai/document/e1626a7c7c6b00771eabfb2402872e99
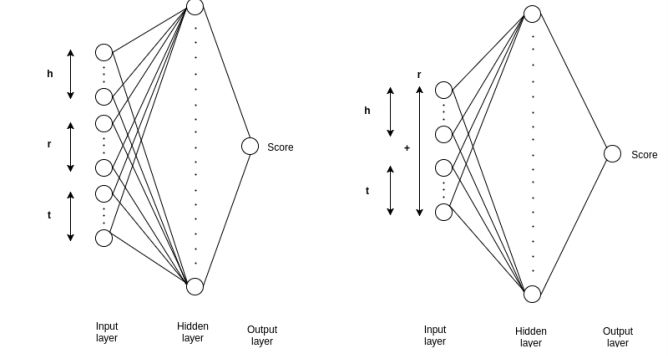
2. Revisiting Simple Neural Networks for Learning Representations of Knowledge Graphs(知识图谱的表示学习:Revisiting简单的神经网络)
作者:Srinivas Ravishankar, Chandrahas,Partha Pratim Talukdar
摘要:We address the problem of learning vector representations for entities and relations in Knowledge Graphs (KGs) for Knowledge Base Completion (KBC). This problem has received significant attention in the past few years and multiple methods have been proposed. Most of the existing methods in the literature use a predefined characteristic scoring function for evaluating the correctness of KG triples. These scoring functions distinguish correct triples (high score) from incorrect ones (low score). However, their performance vary across different datasets. In this work, we demonstrate that a simple neural network based score function can consistently achieve near start-of-the-art performance on multiple datasets. We also quantitatively demonstrate biases in standard benchmark datasets, and highlight the need to perform evaluation spanning various datasets.
期刊:arXiv, 2018年1月8日
网址:
http://www.zhuanzhi.ai/document/44b7ed0f174e881a48d482e481e9ae57
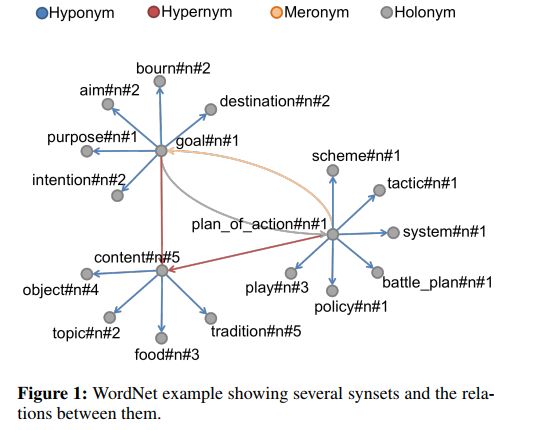
3. Knowledge-based Word Sense Disambiguation using Topic Models(基于知识的词义消歧:一个主题模型方法)
作者:Devendra Singh Chaplot,Ruslan Salakhutdinov
摘要:Word Sense Disambiguation is an open problem in Natural Language Processing which is particularly challenging and useful in the unsupervised setting where all the words in any given text need to be disambiguated without using any labeled data. Typically WSD systems use the sentence or a small window of words around the target word as the context for disambiguation because their computational complexity scales exponentially with the size of the context. In this paper, we leverage the formalism of topic model to design a WSD system that scales linearly with the number of words in the context. As a result, our system is able to utilize the whole document as the context for a word to be disambiguated. The proposed method is a variant of Latent Dirichlet Allocation in which the topic proportions for a document are replaced by synset proportions. We further utilize the information in the WordNet by assigning a non-uniform prior to synset distribution over words and a logistic-normal prior for document distribution over synsets. We evaluate the proposed method on Senseval-2, Senseval-3, SemEval-2007, SemEval-2013 and SemEval-2015 English All-Word WSD datasets and show that it outperforms the state-of-the-art unsupervised knowledge-based WSD system by a significant margin.
期刊:arXiv, 2018年1月6日
网址:
http://www.zhuanzhi.ai/document/7c88481a97379dde4cc5761cde0037b0
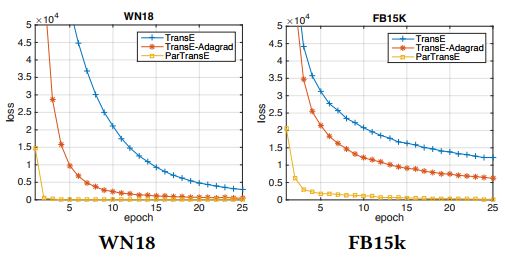
4. Efficient Parallel Translating Embedding For Knowledge Graphs(知识图谱的有效并行翻译嵌入)
作者:Denghui Zhang,Manling Li,Yantao Jia,Yuanzhuo Wang,Xueqi Cheng
摘要:Knowledge graph embedding aims to embed entities and relations of knowledge graphs into low-dimensional vector spaces. Translating embedding methods regard relations as the translation from head entities to tail entities, which achieve the state-of-the-art results among knowledge graph embedding methods. However, a major limitation of these methods is the time consuming training process, which may take several days or even weeks for large knowledge graphs, and result in great difficulty in practical applications. In this paper, we propose an efficient parallel framework for translating embedding methods, called ParTrans-X, which enables the methods to be paralleled without locks by utilizing the distinguished structures of knowledge graphs. Experiments on two datasets with three typical translating embedding methods, i.e., TransE [3], TransH [17], and a more efficient variant TransE- AdaGrad [10] validate that ParTrans-X can speed up the training process by more than an order of magnitude.
期刊:arXiv, 2018年1月9日
网址:
http://www.zhuanzhi.ai/document/382970f40f2aaf9211ea9c4a3878b67c
5. Learning to Speed Up Query Planning in Graph Databases(图数据库中加速query规划的学习)
作者:Mohammad Hossain Namaki,F A Rezaur Rahman Chowdhury,Md Rakibul Islam,Janardhan Rao Doppa,Yinghui Wu
摘要:Querying graph structured data is a fundamental operation that enables important applications including knowledge graph search, social network analysis, and cyber-network security. However, the growing size of real-world data graphs poses severe challenges for graph databases to meet the response-time requirements of the applications. Planning the computational steps of query processing - Query Planning - is central to address these challenges. In this paper, we study the problem of learning to speedup query planning in graph databases towards the goal of improving the computational-efficiency of query processing via training queries.We present a Learning to Plan (L2P) framework that is applicable to a large class of query reasoners that follow the Threshold Algorithm (TA) approach. First, we define a generic search space over candidate query plans, and identify target search trajectories (query plans) corresponding to the training queries by performing an expensive search. Subsequently, we learn greedy search control knowledge to imitate the search behavior of the target query plans. We provide a concrete instantiation of our L2P framework for STAR, a state-of-the-art graph query reasoner. Our experiments on benchmark knowledge graphs including DBpedia, YAGO, and Freebase show that using the query plans generated by the learned search control knowledge, we can significantly improve the speed of STAR with negligible loss in accuracy.
期刊:arXiv, 2018年1月21日
网址:
http://www.zhuanzhi.ai/document/984e5b54eabd51c1ca43dfc8d3801ca5
-END-
专 · 知
人工智能领域主题知识资料查看获取:【专知荟萃】人工智能领域26个主题知识资料全集(入门/进阶/论文/综述/视频/专家等)
同时欢迎各位用户进行专知投稿,详情请点击:
【诚邀】专知诚挚邀请各位专业者加入AI创作者计划!了解使用专知!
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

请加专知小助手微信(Rancho_Fang),加入专知主题人工智能群交流!
点击“阅读原文”,使用专知!
展开全文



