【欢度国庆】深度学习顶会ICLR2019投稿亮点论文,一文速览
【导读】今天就放国庆节了,举国同欢!假期做点啥呢?出门人山人海,在家看看书看看论文也是一种选择。深度学习顶会ICLR2019投稿刚刚结束(9月27号),投稿论文匿名公开。 在此,专知整理了来自Twitter和知乎众大家讨论的热点论文,供大家一阅,大家可以假期看。
投稿论文地址:
https://openreview.net/group?id=ICLR.cc/2019/Conference
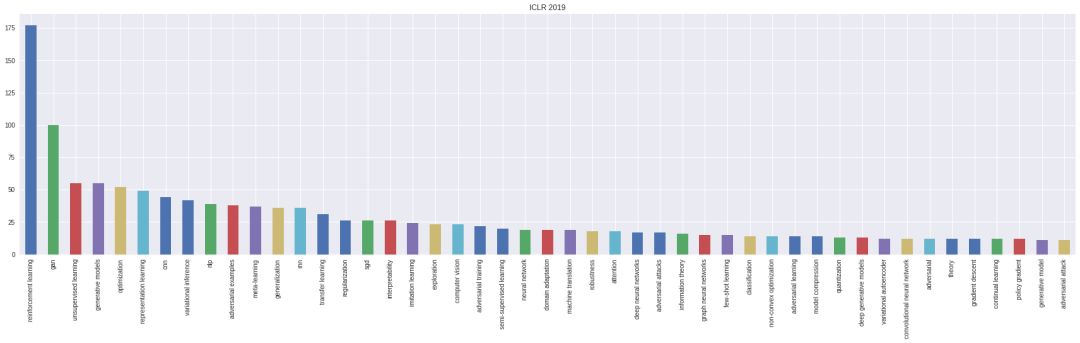
提交论文热门关键词:强化学习、GAN、元学习等等

LARGE SCALE GAN TRAINING FOR HIGH FIDELITY NATURAL IMAGE SYNTHESIS
最强GAN图像生成器,真假难辨
论文地址:
https://openreview.net/pdf?id=B1xsqj09Fm
更多样本地址:
https://drive.google.com/drive/folders/1lWC6XEPD0LT5KUnPXeve_kWeY-FxH002
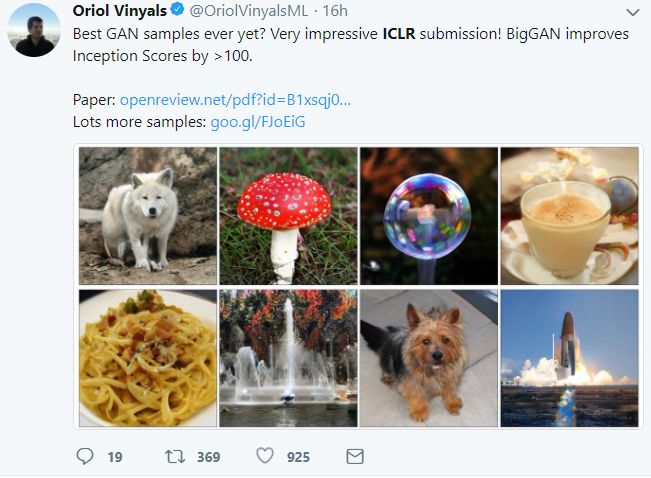
第一篇就是这篇最佳BigGAN,DeepMind负责星际项目的Oriol Vinyals,说这篇论文带来了史上最佳的GAN生成图片,提升Inception Score 100分以上。
论文摘要:
尽管近期由于生成图像建模的研究进展,从复杂数据集例如 ImageNet 中生成高分辨率、多样性的样本仍然是很大的挑战。为此,研究者尝试在最大规模的数据集中训练生成对抗网络,并研究在这种规模的训练下的不稳定性。研究者发现应用垂直正则化(orthogonal regularization)到生成器可以使其服从简单的「截断技巧」(truncation trick),从而允许通过截断隐空间来精调样本保真度和多样性的权衡。这种修改方法可以让模型在类条件的图像合成中达到当前最佳性能。当在 128x128 分辨率的 ImageNet 上训练时,本文提出的模型—BigGAN—可以达到 166.3 的 Inception 分数(IS),以及 9.6 的 Frechet Inception 距离(FID),而之前的最佳 IS 和 FID 仅为 52.52 和 18.65。
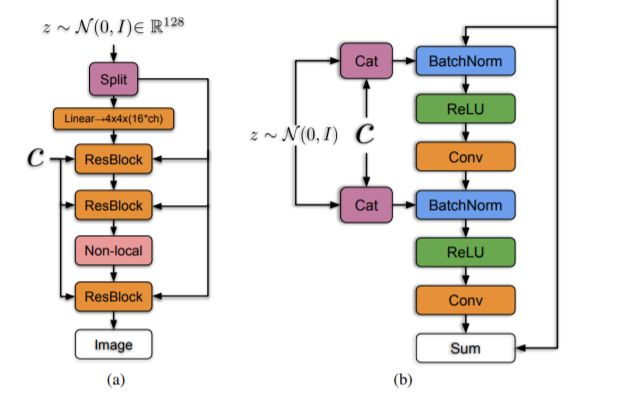
BigGAN的生成器架构

生成样例,真是惟妙惟肖

Recurrent Experience Replay in Distributed Reinforcement Learning
分布式强化学习中的循环经验池
论文地址:
https://openreview.net/pdf?id=r1lyTjAqYX
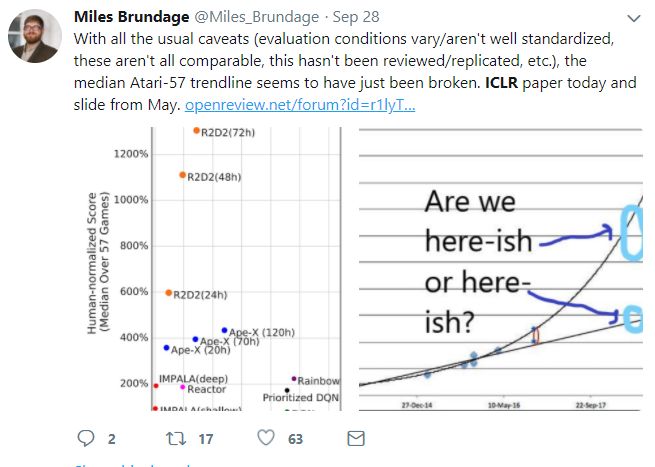
Building on the recent successes of distributed training of RL agents, in this paper we investigate the training of RNN-based RL agents from experience replay. We investigate the effects of parameter lag resulting in representational drift and recurrent state staleness and empirically derive an improved training strategy. Using a single network architecture and fixed set of hyper-parameters, the resulting agent, Recurrent Replay Distributed DQN, triples the previous state of the art on Atari-57, and surpasses the state of the art on DMLab-30. R2D2 is the first agent to exceed human-level performance in 52 of the 57 Atari games.

Shallow Learning For Deep Networks
深度神经网络的浅层学习
论文地址:
https://openreview.net/forum?id=r1Gsk3R9Fm
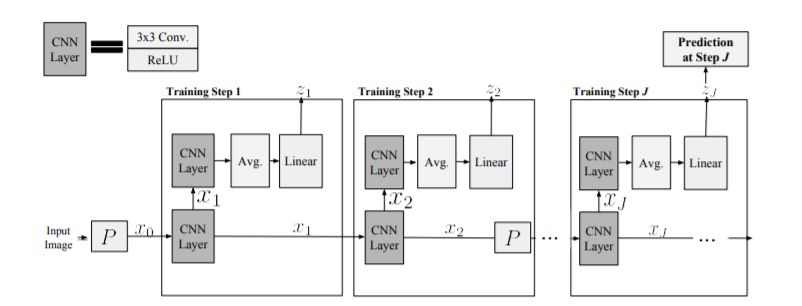
浅层监督的一层隐藏层神经网络具有许多有利的特性,使它们比深层对应物更容易解释,分析和优化,但缺乏表示能力。在这里,我们使用1-hiddenlayer学习问题逐层顺序构建深层网络,这可以从浅层网络继承属性。与之前使用浅网络的方法相反,我们关注的是深度学习被认为对成功至关重要的问题。因此,我们研究了两个大规模图像识别任务的CNN:ImageNet和CIFAR-10。使用一组简单的架构和训练想法,我们发现解决序列1隐藏层辅助问题导致CNN超过ImageNet上的AlexNet性能。通过解决2层和3层隐藏层辅助问题来扩展ourtraining方法以构建单个层,我们获得了一个11层网络,超过ImageNet上的VGG-11,获得了89.8%的前5个单一作物。据我们所知,这是CNN的端到端培训的第一个竞争性替代方案,可以扩展到ImageNet。我们进行了广泛的实验来研究它在中间层上引起的性质。

Relational Graph Attention Networks
关联性图注意力网络
论文地址:
https://openreview.net/forum?id=Bklzkh0qFm¬eId=HJxMHja3Y7
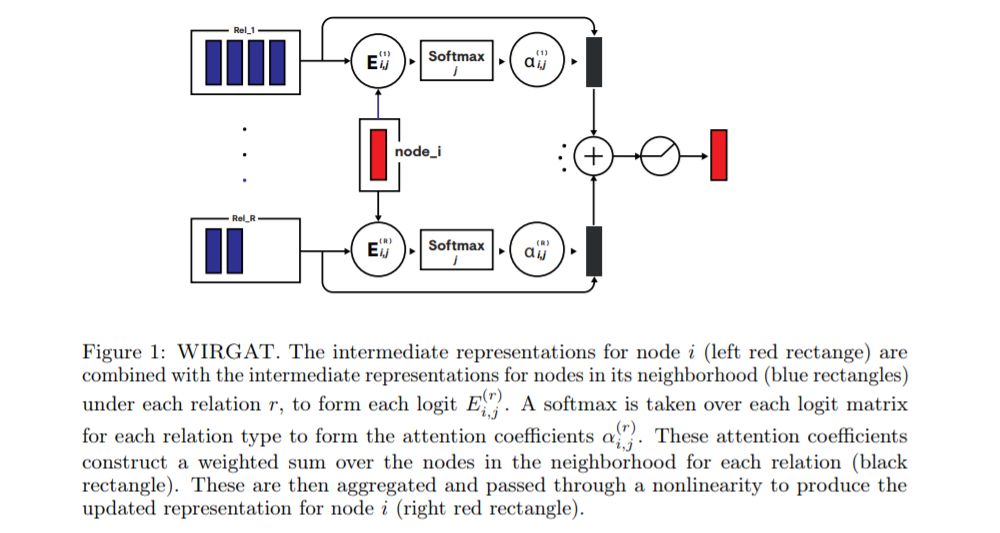
论文摘要:
In this paper we present Relational Graph Attention Networks, an extension of Graph Attention Networks to incorporate both node features and relational information into a masked attention mechanism, extending graph-based attention methods to a wider variety of problems, specifically, predicting the properties of molecules. We demonstrate that our attention mechanism gives competitive results on a molecular toxicity classification task (Tox21), enhancing the performance of its spectral-based convolutional equivalent. We also investigate the model on a series of transductive knowledge base completion tasks, where its performance is noticeably weaker. We provide insights as to why this may be, and suggest when it is appropriate to incorporate an attention layer into a graph architecture.

A Solution to China Competitive Poker Using Deep Learning
斗地主深度学习算法
论文地址:
https://openreview.net/forum?id=rJzoujRct7
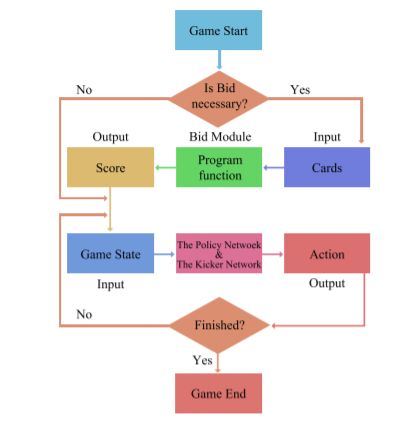
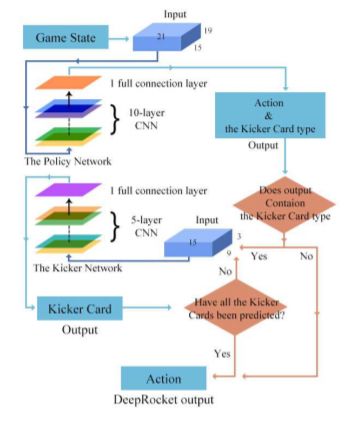
论文摘要:
Recently, deep neural networks have achieved superhuman performance in various games such as Go, chess and Shogi. Compared to Go, China Competitive Poker, also known as Dou dizhu, is a type of imperfect information game, including hidden information, randomness, multi-agent cooperation and competition. It has become widespread and is now a national game in China. We introduce an approach to play China Competitive Poker using Convolutional Neural Network (CNN) to predict actions. This network is trained by supervised learning from human game records. Without any search, the network already beats the best AI program by a large margin, and also beats the best human amateur players in duplicate mode.
其他有意思论文:
ICLR 2019 有什么值得关注的亮点?
- 周博磊的回答 - 知乎
https://www.zhihu.com/question/296404213/answer/500575759
问句开头式:
Are adversarial examples inevitable?
Transfer Value or Policy? A Value-centric Framework Towards Transferrable Continuous Reinforcement Learning
How Important is a Neuron?
How Powerful are Graph Neural Networks?
Do Language Models Have Common Sense?
Is Wasserstein all you need?
哲理警句式:
Learning From the Experience of Others: Approximate Empirical Bayes in Neural Networks
In Your Pace: Learning the Right Example at the Right Time
Learning what you can do before doing anything
Like What You Like: Knowledge Distill via Neuron Selectivity Transfer
Don’s Settle for Average, Go for the Max: Fuzzy Sets and Max-Pooled Word Vectors
抖机灵式:
Look Ma, No GANs! Image Transformation with ModifAE
No Pressure! Addressing Problem of Local Minima in Manifold Learning
Backplay: 'Man muss immer umkehren'
Talk The Walk: Navigating Grids in New York City through Grounded Dialogue
Fatty and Skinny: A Joint Training Method of Watermark
A bird's eye view on coherence, and a worm's eye view on cohesion
Beyond Winning and Losing: Modeling Human Motivations and Behaviors with Vector-valued Inverse Reinforcement Learning
一句总结式:
ImageNet-trained CNNs are biased towards texture; increasing shape bias improves accuracy and robustness.
-END-
专 · 知
人工智能领域26个主题知识资料全集获取与加入专知人工智能服务群: 欢迎微信扫一扫加入专知人工智能知识星球群,获取专业知识教程视频资料和与专家交流咨询!

请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请加专知小助手微信(扫一扫如下二维码添加),加入专知主题群(请备注主题类型:AI、NLP、CV、 KG等)交流~

请关注专知公众号,获取人工智能的专业知识!
点击“阅读原文”,使用专知
展开全文



