【论文推荐】最新七篇强化学习相关论文—逻辑约束、综述、多任务深度强化学习、参数服务器、事件抽取、分层强化学习、过拟合研究
【导读】既昨天推出六篇强化学习(Reinforcement Learning)相关文章,专知内容组今天又推出最近七篇强化学习相关文章,为大家进行介绍,欢迎查看!
1. Logically-Constrained Reinforcement Learning(逻辑约束强化学习)
作者:Mohammadhosein Hasanbeig,Alessandro Abate,Daniel Kroening
机构:University of Oxford
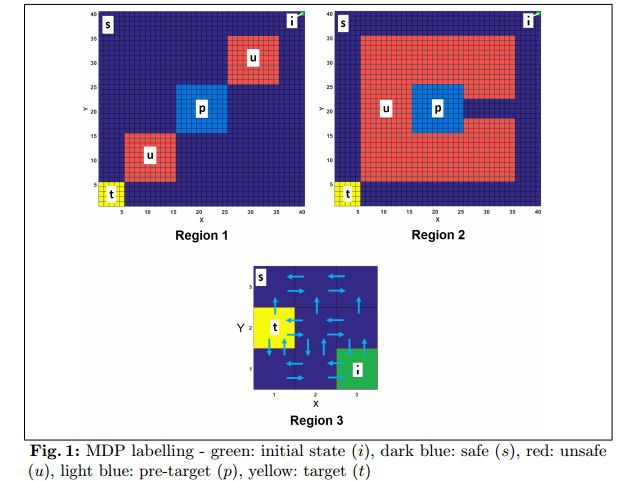
摘要:This paper proposes a Reinforcement Learning (RL) algorithm to synthesize policies for a Markov Decision Process (MDP), such that a linear time property is satisfied. We convert the property into a Limit Deterministic Buchi Automaton (LDBA), then construct a product MDP between the automaton and the original MDP. A reward function is then assigned to the states of the product automaton, according to accepting conditions of the LDBA. With this reward function, our algorithm synthesizes a policy that satisfies the linear time property: as such, the policy synthesis procedure is "constrained" by the given specification. Additionally, we show that the RL procedure sets up an online value iteration method to calculate the maximum probability of satisfying the given property, at any given state of the MDP - a convergence proof for the procedure is provided. Finally, the performance of the algorithm is evaluated via a set of numerical examples. We observe an improvement of one order of magnitude in the number of iterations required for the synthesis compared to existing approaches.
期刊:arXiv, 2018年4月23日
网址:
http://www.zhuanzhi.ai/document/2fa407391615901dbeef65a28fdd9f8c
2. Feature-Based Aggregation and Deep Reinforcement Learning: A Survey and Some New Implementations(基于特征的聚合和深度强化学习:综述及一些新的实现)
作者:Dimitri P. Bertsekas
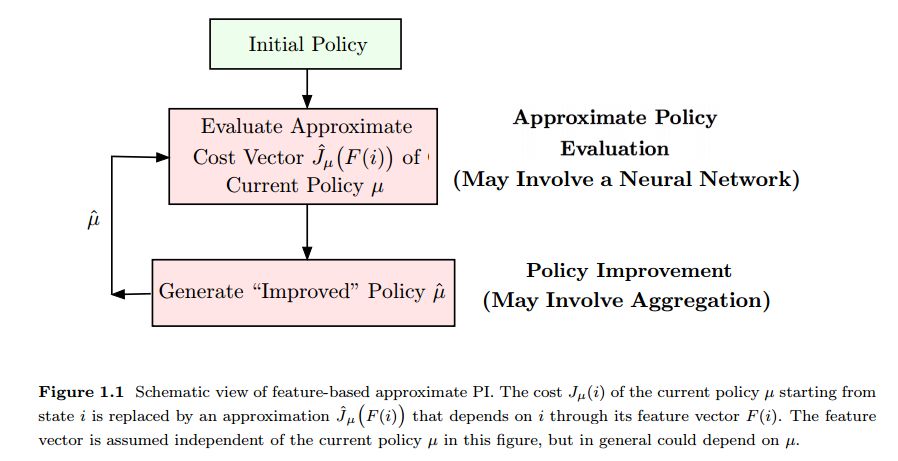
摘要:In this paper we discuss policy iteration methods for approximate solution of a finite-state discounted Markov decision problem, with a focus on feature-based aggregation methods and their connection with deep reinforcement learning schemes. We introduce features of the states of the original problem, and we formulate a smaller "aggregate" Markov decision problem, whose states relate to the features. The optimal cost function of the aggregate problem, a nonlinear function of the features, serves as an architecture for approximation in value space of the optimal cost function or the cost functions of policies of the original problem. We discuss properties and possible implementations of this type of aggregation, including a new approach to approximate policy iteration. In this approach the policy improvement operation combines feature-based aggregation with reinforcement learning based on deep neural networks, which is used to obtain the needed features. We argue that the cost function of a policy may be approximated much more accurately by the nonlinear function of the features provided by aggregation, than by the linear function of the features provided by deep reinforcement learning, thereby potentially leading to more effective policy improvement.
期刊:arXiv, 2018年4月22日
网址:
http://www.zhuanzhi.ai/document/740e37db7a343733723bc7c28d923403
3. Diff-DAC: Distributed Actor-Critic for Average Multitask Deep Reinforcement Learning(Diff-DAC:平均多任务深度强化学习的分布式Actor-Critic算法)
作者:Sergio Valcarcel Macua,Aleksi Tukiainen,Daniel García-Ocaña Hernández,David Baldazo,Enrique Munoz de Cote,Santiago Zazo
机构:Universidad Politecnica de Madrid
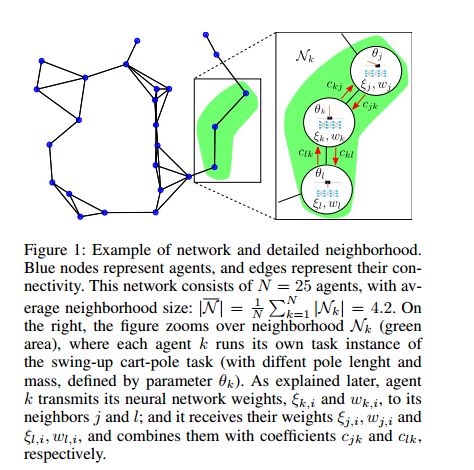
摘要:We propose a fully distributed actor-critic algorithm approximated by deep neural networks, named \textit{Diff-DAC}, with application to single-task and to average multitask reinforcement learning (MRL). Each agent has access to data from its local task only, but it aims to learn a policy that performs well on average for the whole set of tasks. During the learning process, agents communicate their value-policy parameters to their neighbors, diffusing the information across the network, so that they converge to a common policy, with no need for a central node. The method is scalable, since the computational and communication costs per agent grow with its number of neighbors. We derive Diff-DAC's from duality theory and provide novel insights into the standard actor-critic framework, showing that it is actually an instance of the dual ascent method that approximates the solution of a linear program. Experiments suggest that Diff-DAC can outperform the single previous distributed MRL approach (i.e., Dist-MTLPS) and even the centralized architecture.
期刊:arXiv, 2018年4月22日
网址:
http://www.zhuanzhi.ai/document/dd0c59185f32e1a63d110608e0a5c1ed
4. MQGrad: Reinforcement Learning of Gradient Quantization in Parameter Server(MQGrad: 参数服务器中梯度量化的强化学习)
作者:Guoxin Cui,Jun Xu,Wei Zeng,Yanyan Lan,Jiafeng Guo,Xueqi Cheng
机构:Chinese Academy of Sciences
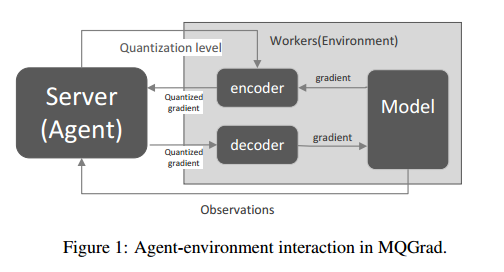
摘要:One of the most significant bottleneck in training large scale machine learning models on parameter server (PS) is the communication overhead, because it needs to frequently exchange the model gradients between the workers and servers during the training iterations. Gradient quantization has been proposed as an effective approach to reducing the communication volume. One key issue in gradient quantization is setting the number of bits for quantizing the gradients. Small number of bits can significantly reduce the communication overhead while hurts the gradient accuracies, and vise versa. An ideal quantization method would dynamically balance the communication overhead and model accuracy, through adjusting the number bits according to the knowledge learned from the immediate past training iterations. Existing methods, however, quantize the gradients either with fixed number of bits, or with predefined heuristic rules. In this paper we propose a novel adaptive quantization method within the framework of reinforcement learning. The method, referred to as MQGrad, formalizes the selection of quantization bits as actions in a Markov decision process (MDP) where the MDP states records the information collected from the past optimization iterations (e.g., the sequence of the loss function values). During the training iterations of a machine learning algorithm, MQGrad continuously updates the MDP state according to the changes of the loss function. Based on the information, MDP learns to select the optimal actions (number of bits) to quantize the gradients. Experimental results based on a benchmark dataset showed that MQGrad can accelerate the learning of a large scale deep neural network while keeping its prediction accuracies.
期刊:arXiv, 2018年4月22日
网址:
http://www.zhuanzhi.ai/document/b6c26bd0e7e5228b2391b2d22cc6f3a8
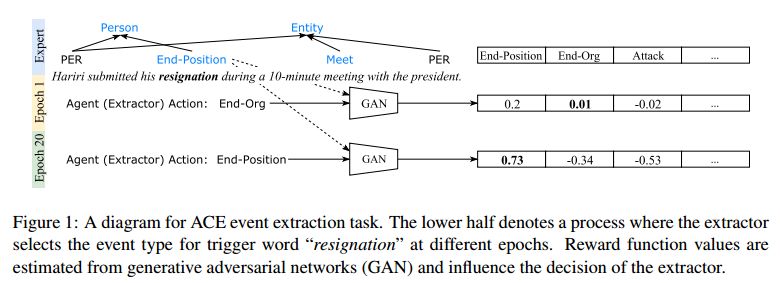
5. Event Extraction with Generative Adversarial Imitation Learning(基于生成对抗模仿学习的事件抽取)
作者:Tongtao Zhang,Heng Ji
摘要:We propose a new method for event extraction (EE) task based on an imitation learning framework, specifically, inverse reinforcement learning (IRL) via generative adversarial network (GAN). The GAN estimates proper rewards according to the difference between the actions committed by the expert (or ground truth) and the agent among complicated states in the environment. EE task benefits from these dynamic rewards because instances and labels yield to various extents of difficulty and the gains are expected to be diverse -- e.g., an ambiguous but correctly detected trigger or argument should receive high gains -- while the traditional RL models usually neglect such differences and pay equal attention on all instances. Moreover, our experiments also demonstrate that the proposed framework outperforms state-of-the-art methods, without explicit feature engineering.
期刊:arXiv, 2018年4月21日
网址:
http://www.zhuanzhi.ai/document/5bceb51b336f63bbcde33eda6758ce73
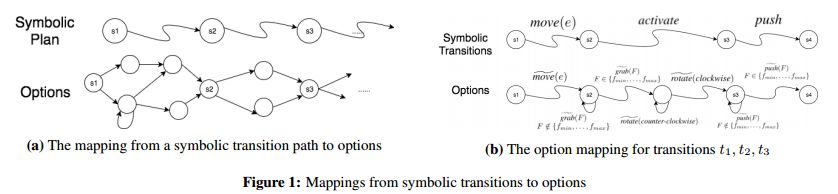
6. PEORL: Integrating Symbolic Planning and Hierarchical Reinforcement Learning for Robust Decision-Making(PEORL:集成符号规划和分层强化学习的鲁棒决策)
作者:Fangkai Yang,Daoming Lyu,Bo Liu,Steven Gustafson
机构:Auburn University
摘要:Reinforcement learning and symbolic planning have both been used to build intelligent autonomous agents. Reinforcement learning relies on learning from interactions with real world, which often requires an unfeasibly large amount of experience. Symbolic planning relies on manually crafted symbolic knowledge, which may not be robust to domain uncertainties and changes. In this paper we present a unified framework {\em PEORL} that integrates symbolic planning with hierarchical reinforcement learning (HRL) to cope with decision-making in a dynamic environment with uncertainties. Symbolic plans are used to guide the agent's task execution and learning, and the learned experience is fed back to symbolic knowledge to improve planning. This method leads to rapid policy search and robust symbolic plans in complex domains. The framework is tested on benchmark domains of HRL.
期刊:arXiv, 2018年4月21日
网址:
http://www.zhuanzhi.ai/document/f901ebc69ed7fc56da1cc28d18a3c53e
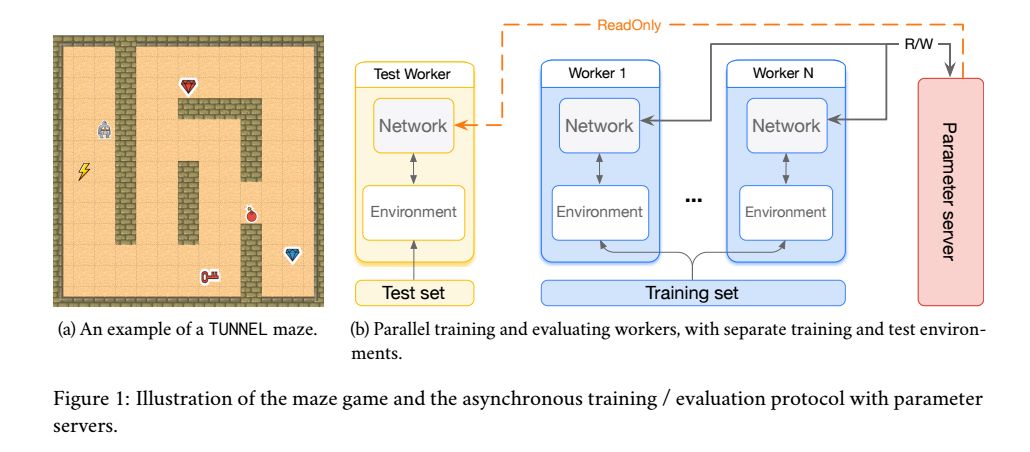
7. A Study on Overfitting in Deep Reinforcement Learning(深度强化学习中的过拟合研究)
作者:Chiyuan Zhang,Oriol Vinyals,Remi Munos,Samy Bengio
摘要:Recent years have witnessed significant progresses in deep Reinforcement Learning (RL). Empowered with large scale neural networks, carefully designed architectures, novel training algorithms and massively parallel computing devices, researchers are able to attack many challenging RL problems. However, in machine learning, more training power comes with a potential risk of more overfitting. As deep RL techniques are being applied to critical problems such as healthcare and finance, it is important to understand the generalization behaviors of the trained agents. In this paper, we conduct a systematic study of standard RL agents and find that they could overfit in various ways. Moreover, overfitting could happen "robustly": commonly used techniques in RL that add stochasticity do not necessarily prevent or detect overfitting. In particular, the same agents and learning algorithms could have drastically different test performance, even when all of them achieve optimal rewards during training. The observations call for more principled and careful evaluation protocols in RL. We conclude with a general discussion on overfitting in RL and a study of the generalization behaviors from the perspective of inductive bias.
期刊:arXiv, 2018年4月21日
网址:
http://www.zhuanzhi.ai/document/51c1c6cca099593d2c46b0ee89dd4751
-END-
专 · 知
人工智能领域主题知识资料查看与加入专知人工智能服务群:
【专知AI服务计划】专知AI知识技术服务会员群加入与人工智能领域26个主题知识资料全集获取

点击上面图片加入会员
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

点击“阅读原文”,使用专知
展开全文



